 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiheng Chen
Ethical-Lens: Curbing Malicious Usages of Open-Source Text-to-Image Models
Apr 18, 2024
The burgeoning landscape of text-to-image models, exemplified by innovations such as Midjourney and DALLE 3, has revolutionized content creation across diverse sectors. However, these advancements bring forth critical ethical concerns, particularly with the misuse of open-source models to generate content that violates societal norms. Addressing this, we introduce Ethical-Lens, a framework designed to facilitate the value-aligned usage of text-to-image tools without necessitating internal model revision. Ethical-Lens ensures value alignment in text-to-image models across toxicity and bias dimensions by refining user commands and rectifying model outputs. Systematic evaluation metrics, combining GPT4-V, HEIM, and FairFace scores, assess alignment capability. Our experiments reveal that Ethical-Lens enhances alignment capabilities to levels comparable with or superior to commercial models like DALLE 3, ensuring user-generated content adheres to ethical standards while maintaining image quality. This study indicates the potential of Ethical-Lens to ensure the sustainable development of open-source text-to-image tools and their beneficial integration into society. Our code is available at https://github.com/yuzhu-cai/Ethical-Lens.
Towards Collaborative Autonomous Driving: Simulation Platform and End-to-End System
Apr 15, 2024Vehicle-to-everything-aided autonomous driving (V2X-AD) has a huge potential to provide a safer driving solution. Despite extensive researches in transportation and communication to support V2X-AD, the actual utilization of these infrastructures and communication resources in enhancing driving performances remains largely unexplored. This highlights the necessity of collaborative autonomous driving: a machine learning approach that optimizes the information sharing strategy to improve the driving performance of each vehicle. This effort necessitates two key foundations: a platform capable of generating data to facilitate the training and testing of V2X-AD, and a comprehensive system that integrates full driving-related functionalities with mechanisms for information sharing. From the platform perspective, we present V2Xverse, a comprehensive simulation platform for collaborative autonomous driving. This platform provides a complete pipeline for collaborative driving. From the system perspective, we introduce CoDriving, a novel end-to-end collaborative driving system that properly integrates V2X communication over the entire autonomous pipeline, promoting driving with shared perceptual information. The core idea is a novel driving-oriented communication strategy. Leveraging this strategy, CoDriving improves driving performance while optimizing communication efficiency. We make comprehensive benchmarks with V2Xverse, analyzing both modular performance and closed-loop driving performance. Experimental results show that CoDriving: i) significantly improves the driving score by 62.49% and drastically reduces the pedestrian collision rate by 53.50% compared to the SOTA end-to-end driving method, and ii) achieves sustaining driving performance superiority over dynamic constraint communication conditions.
V2X-PC: Vehicle-to-everything Collaborative Perception via Point Cluster
Mar 25, 2024The objective of the collaborative vehicle-to-everything perception task is to enhance the individual vehicle's perception capability through message communication among neighboring traffic agents. Previous methods focus on achieving optimal performance within bandwidth limitations and typically adopt BEV maps as the basic collaborative message units. However, we demonstrate that collaboration with dense representations is plagued by object feature destruction during message packing, inefficient message aggregation for long-range collaboration, and implicit structure representation communication. To tackle these issues, we introduce a brand new message unit, namely point cluster, designed to represent the scene sparsely with a combination of low-level structure information and high-level semantic information. The point cluster inherently preserves object information while packing messages, with weak relevance to the collaboration range, and supports explicit structure modeling. Building upon this representation, we propose a novel framework V2X-PC for collaborative perception. This framework includes a Point Cluster Packing (PCP) module to keep object feature and manage bandwidth through the manipulation of cluster point numbers. As for effective message aggregation, we propose a Point Cluster Aggregation (PCA) module to match and merge point clusters associated with the same object. To further handle time latency and pose errors encountered in real-world scenarios, we propose parameter-free solutions that can adapt to different noisy levels without finetuning. Experiments on two widely recognized collaborative perception benchmarks showcase the superior performance of our method compared to the previous state-of-the-art approaches relying on BEV maps.
FastMAC: Stochastic Spectral Sampling of Correspondence Graph
Mar 13, 2024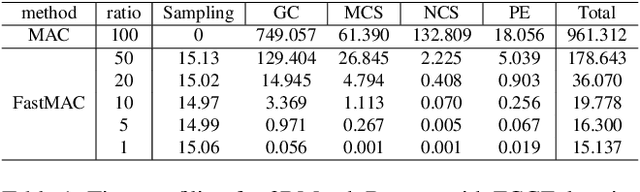
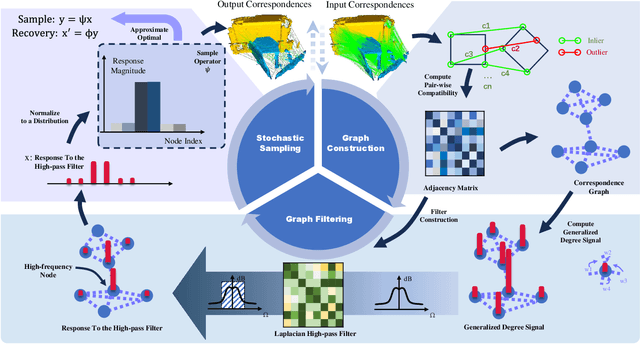
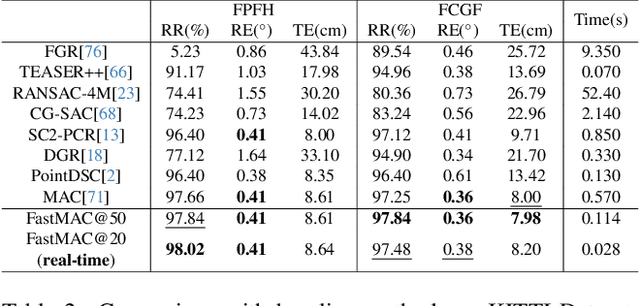
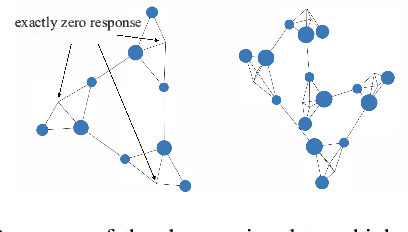
3D correspondence, i.e., a pair of 3D points, is a fundamental concept in computer vision. A set of 3D correspondences, when equipped with compatibility edges, forms a correspondence graph. This graph is a critical component in several state-of-the-art 3D point cloud registration approaches, e.g., the one based on maximal cliques (MAC). However, its properties have not been well understood. So we present the first study that introduces graph signal processing into the domain of correspondence graph. We exploit the generalized degree signal on correspondence graph and pursue sampling strategies that preserve high-frequency components of this signal. To address time-consuming singular value decomposition in deterministic sampling, we resort to a stochastic approximate sampling strategy. As such, the core of our method is the stochastic spectral sampling of correspondence graph. As an application, we build a complete 3D registration algorithm termed as FastMAC, that reaches real-time speed while leading to little to none performance drop. Through extensive experiments, we validate that FastMAC works for both indoor and outdoor benchmarks. For example, FastMAC can accelerate MAC by 80 times while maintaining high registration success rate on KITTI. Codes are publicly available at https://github.com/Forrest-110/FastMAC.
Decentralized and Lifelong-Adaptive Multi-Agent Collaborative Learning
Mar 11, 2024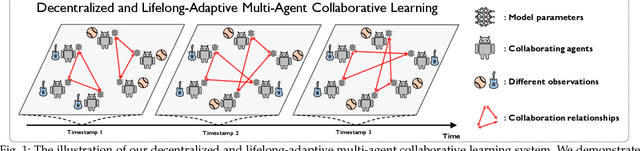
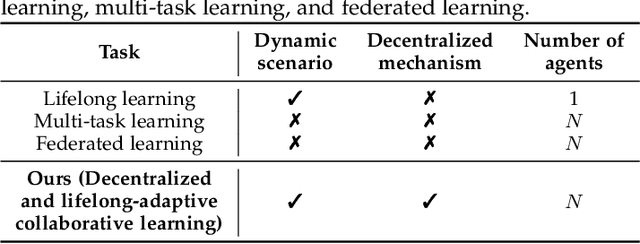
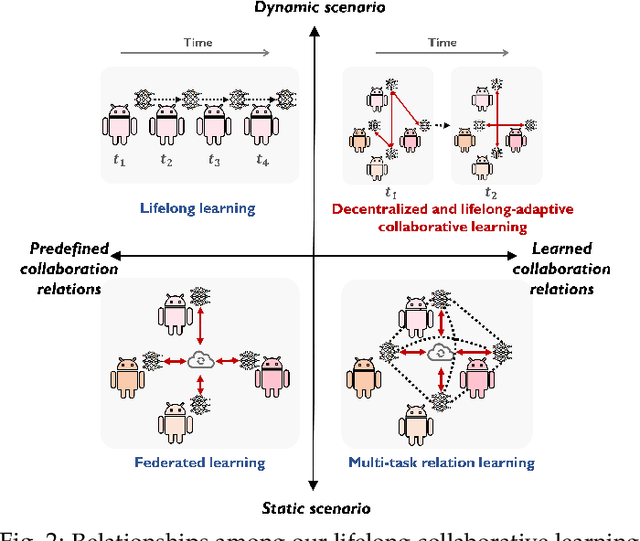
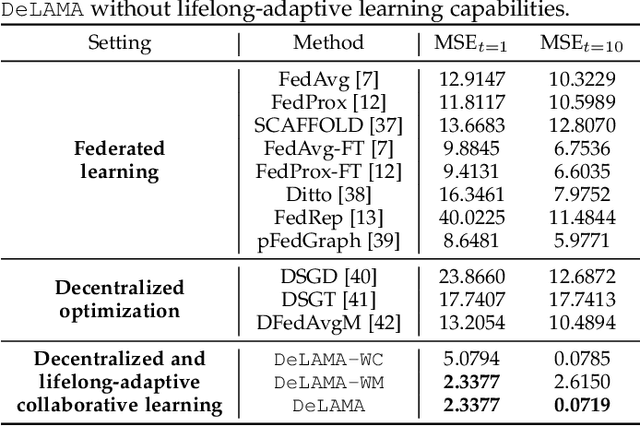
Decentralized and lifelong-adaptive multi-agent collaborative learning aims to enhance collaboration among multiple agents without a central server, with each agent solving varied tasks over time. To achieve efficient collaboration, agents should: i) autonomously identify beneficial collaborative relationships in a decentralized manner; and ii) adapt to dynamically changing task observations. In this paper, we propose DeLAMA, a decentralized multi-agent lifelong collaborative learning algorithm with dynamic collaboration graphs. To promote autonomous collaboration relationship learning, we propose a decentralized graph structure learning algorithm, eliminating the need for external priors. To facilitate adaptation to dynamic tasks, we design a memory unit to capture the agents' accumulated learning history and knowledge, while preserving finite storage consumption. To further augment the system's expressive capabilities and computational efficiency, we apply algorithm unrolling, leveraging the advantages of both mathematical optimization and neural networks. This allows the agents to `learn to collaborate' through the supervision of training tasks. Our theoretical analysis verifies that inter-agent collaboration is communication efficient under a small number of communication rounds. The experimental results verify its ability to facilitate the discovery of collaboration strategies and adaptation to dynamic learning scenarios, achieving a 98.80% reduction in MSE and a 188.87% improvement in classification accuracy. We expect our work can serve as a foundational technique to facilitate future works towards an intelligent, decentralized, and dynamic multi-agent system. Code is available at https://github.com/ShuoTang123/DeLAMA.
Enhancing Data Quality in Federated Fine-Tuning of Foundation Models
Mar 07, 2024
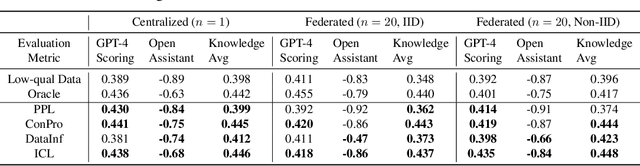
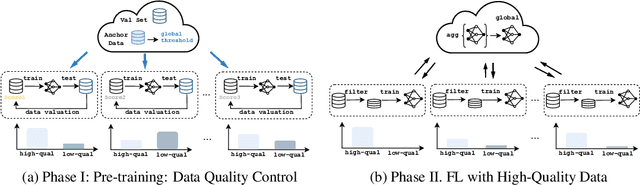
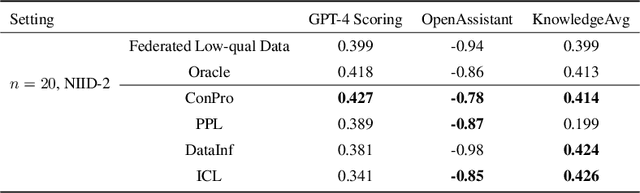
In the current landscape of foundation model training, there is a significant reliance on public domain data, which is nearing exhaustion according to recent research. To further scale up, it is crucial to incorporate collaboration among multiple specialized and high-quality private domain data sources. However, the challenge of training models locally without sharing private data presents numerous obstacles in data quality control. To tackle this issue, we propose a data quality control pipeline for federated fine-tuning of foundation models. This pipeline computes scores reflecting the quality of training data and determines a global threshold for a unified standard, aiming for improved global performance. Our experiments show that the proposed quality control pipeline facilitates the effectiveness and reliability of the model training, leading to better performance.
OpenFedLLM: Training Large Language Models on Decentralized Private Data via Federated Learning
Feb 10, 2024Trained on massive publicly available data, large language models (LLMs) have demonstrated tremendous success across various fields. While more data contributes to better performance, a disconcerting reality is that high-quality public data will be exhausted in a few years. In this paper, we offer a potential next step for contemporary LLMs: collaborative and privacy-preserving LLM training on the underutilized distributed private data via federated learning (FL), where multiple data owners collaboratively train a shared model without transmitting raw data. To achieve this, we build a concise, integrated, and research-friendly framework/codebase, named OpenFedLLM. It covers federated instruction tuning for enhancing instruction-following capability, federated value alignment for aligning with human values, and 7 representative FL algorithms. Besides, OpenFedLLM supports training on diverse domains, where we cover 8 training datasets; and provides comprehensive evaluations, where we cover 30+ evaluation metrics. Through extensive experiments, we observe that all FL algorithms outperform local training on training LLMs, demonstrating a clear performance improvement across a variety of settings. Notably, in a financial benchmark, Llama2-7B fine-tuned by applying any FL algorithm can outperform GPT-4 by a significant margin while the model obtained through individual training cannot, demonstrating strong motivation for clients to participate in FL. The code is available at https://github.com/rui-ye/OpenFedLLM.
Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation
Feb 08, 2024Aligning large language models (LLMs) with human values is imperative to mitigate potential adverse effects resulting from their misuse. Drawing from the sociological insight that acknowledging all parties' concerns is a key factor in shaping human values, this paper proposes a novel direction to align LLMs by themselves: social scene simulation. To achieve this, we present MATRIX, a novel social scene simulator that emulates realistic scenes around a user's input query, enabling the LLM to take social consequences into account before responding. MATRIX serves as a virtual rehearsal space, akin to a Monopolylogue, where the LLM performs diverse roles related to the query and practice by itself. To inject this alignment, we fine-tune the LLM with MATRIX-simulated data, ensuring adherence to human values without compromising inference speed. We theoretically show that the LLM with MATRIX outperforms Constitutional AI under mild assumptions. Finally, extensive experiments validate that our method outperforms over 10 baselines across 4 benchmarks. As evidenced by 875 user ratings, our tuned 13B-size LLM exceeds GPT-4 in aligning with human values. Code is available at https://github.com/pangxianghe/MATRIX.
Hypergraph Node Classification With Graph Neural Networks
Feb 08, 2024Hypergraphs, with hyperedges connecting more than two nodes, are key for modelling higher-order interactions in real-world data. The success of graph neural networks (GNNs) reveals the capability of neural networks to process data with pairwise interactions. This inspires the usage of neural networks for data with higher-order interactions, thereby leading to the development of hypergraph neural networks (HyperGNNs). GNNs and HyperGNNs are typically considered distinct since they are designed for data on different geometric topologies. However, in this paper, we theoretically demonstrate that, in the context of node classification, most HyperGNNs can be approximated using a GNN with a weighted clique expansion of the hypergraph. This leads to WCE-GNN, a simple and efficient framework comprising a GNN and a weighted clique expansion (WCE), for hypergraph node classification. Experiments on nine real-world hypergraph node classification benchmarks showcase that WCE-GNN demonstrates not only higher classification accuracy compared to state-of-the-art HyperGNNs, but also superior memory and runtime efficiency.
Editable Scene Simulation for Autonomous Driving via Collaborative LLM-Agents
Feb 08, 2024Scene simulation in autonomous driving has gained significant attention because of its huge potential for generating customized data. However, existing editable scene simulation approaches face limitations in terms of user interaction efficiency, multi-camera photo-realistic rendering and external digital assets integration. To address these challenges, this paper introduces ChatSim, the first system that enables editable photo-realistic 3D driving scene simulations via natural language commands with external digital assets. To enable editing with high command flexibility,~ChatSim leverages a large language model (LLM) agent collaboration framework. To generate photo-realistic outcomes, ChatSim employs a novel multi-camera neural radiance field method. Furthermore, to unleash the potential of extensive high-quality digital assets, ChatSim employs a novel multi-camera lighting estimation method to achieve scene-consistent assets' rendering. Our experiments on Waymo Open Dataset demonstrate that ChatSim can handle complex language commands and generate corresponding photo-realistic scene videos.