 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWanru Zhao
Attacks on Third-Party APIs of Large Language Models
Apr 24, 2024
Large language model (LLM) services have recently begun offering a plugin ecosystem to interact with third-party API services. This innovation enhances the capabilities of LLMs, but it also introduces risks, as these plugins developed by various third parties cannot be easily trusted. This paper proposes a new attacking framework to examine security and safety vulnerabilities within LLM platforms that incorporate third-party services. Applying our framework specifically to widely used LLMs, we identify real-world malicious attacks across various domains on third-party APIs that can imperceptibly modify LLM outputs. The paper discusses the unique challenges posed by third-party API integration and offers strategic possibilities to improve the security and safety of LLM ecosystems moving forward. Our code is released at https://github.com/vk0812/Third-Party-Attacks-on-LLMs.
Enhancing Data Quality in Federated Fine-Tuning of Foundation Models
Mar 07, 2024
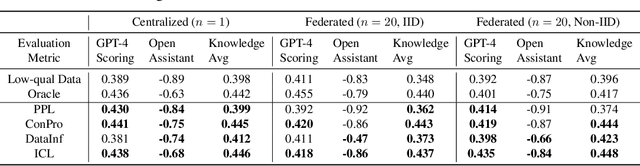
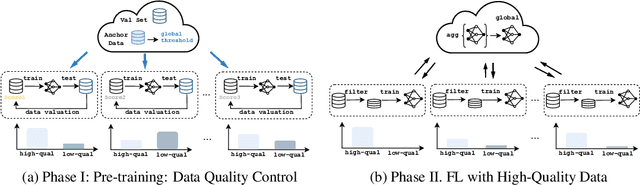
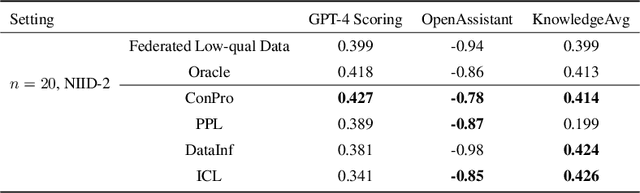
In the current landscape of foundation model training, there is a significant reliance on public domain data, which is nearing exhaustion according to recent research. To further scale up, it is crucial to incorporate collaboration among multiple specialized and high-quality private domain data sources. However, the challenge of training models locally without sharing private data presents numerous obstacles in data quality control. To tackle this issue, we propose a data quality control pipeline for federated fine-tuning of foundation models. This pipeline computes scores reflecting the quality of training data and determines a global threshold for a unified standard, aiming for improved global performance. Our experiments show that the proposed quality control pipeline facilitates the effectiveness and reliability of the model training, leading to better performance.
FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
vFedSec: Efficient Secure Aggregation for Vertical Federated Learning via Secure Layer
May 26, 2023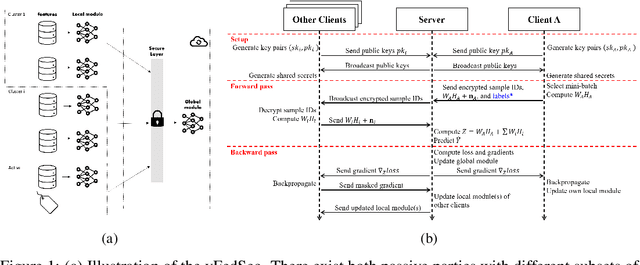
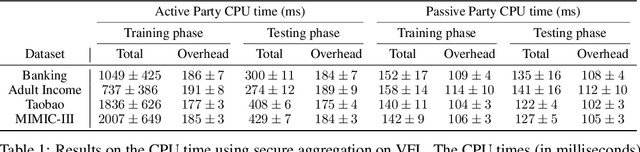
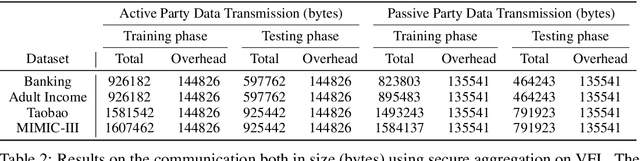

Most work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, individual data points are scattered across different clients/organizations in a vertical setting. Solutions for this type of FL require the exchange of intermediate outputs and gradients between participants, posing a potential risk of privacy leakage when privacy and security concerns are not considered. In this work, we present vFedSec - a novel design with an innovative Secure Layer for training vertical FL securely and efficiently using state-of-the-art security modules in secure aggregation. We theoretically demonstrate that our method does not impact the training performance while protecting private data effectively. Empirically results also show its applicability with extensive experiments that our design can achieve the protection with negligible computation and communication overhead. Also, our method can obtain 9.1e2 ~ 3.8e4 speedup compared to widely-adopted homomorphic encryption (HE) method.
Efficient Vertical Federated Learning with Secure Aggregation
May 18, 2023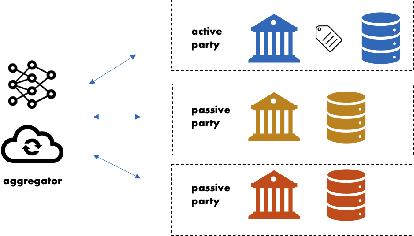
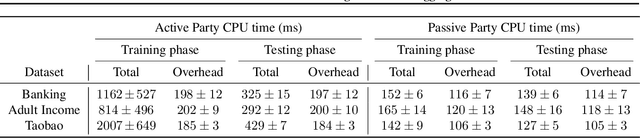

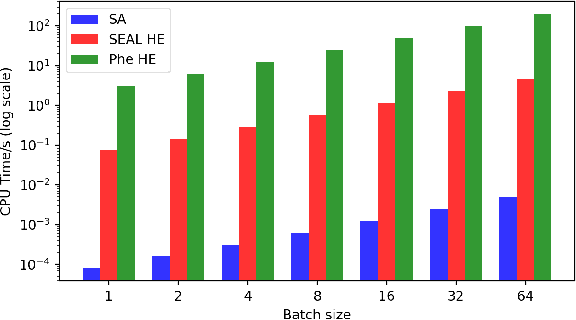
The majority of work in privacy-preserving federated learning (FL) has been focusing on horizontally partitioned datasets where clients share the same sets of features and can train complete models independently. However, in many interesting problems, such as financial fraud detection and disease detection, individual data points are scattered across different clients/organizations in vertical federated learning. Solutions for this type of FL require the exchange of gradients between participants and rarely consider privacy and security concerns, posing a potential risk of privacy leakage. In this work, we present a novel design for training vertical FL securely and efficiently using state-of-the-art security modules for secure aggregation. We demonstrate empirically that our method does not impact training performance whilst obtaining 9.1e2 ~3.8e4 speedup compared to homomorphic encryption (HE).
Protea: Client Profiling within Federated Systems using Flower
Jul 03, 2022

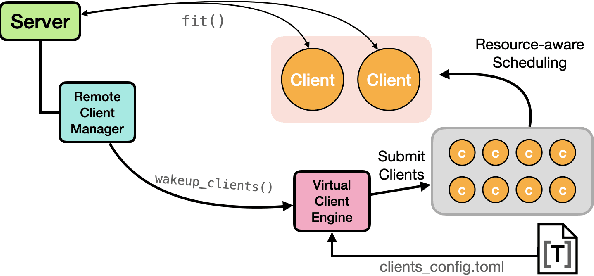
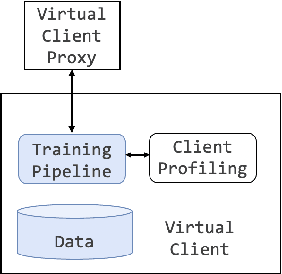
Federated Learning (FL) has emerged as a prospective solution that facilitates the training of a high-performing centralised model without compromising the privacy of users. While successful, research is currently limited by the possibility of establishing a realistic large-scale FL system at the early stages of experimentation. Simulation can help accelerate this process. To facilitate efficient scalable FL simulation of heterogeneous clients, we design and implement Protea, a flexible and lightweight client profiling component within federated systems using the FL framework Flower. It allows automatically collecting system-level statistics and estimating the resources needed for each client, thus running the simulation in a resource-aware fashion. The results show that our design successfully increases parallelism for 1.66 $\times$ faster wall-clock time and 2.6$\times$ better GPU utilisation, which enables large-scale experiments on heterogeneous clients.