 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYan Gao
From Image to Video, what do we need in multimodal LLMs?
Apr 18, 2024
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
Agent Group Chat: An Interactive Group Chat Simulacra For Better Eliciting Collective Emergent Behavior
Mar 20, 2024
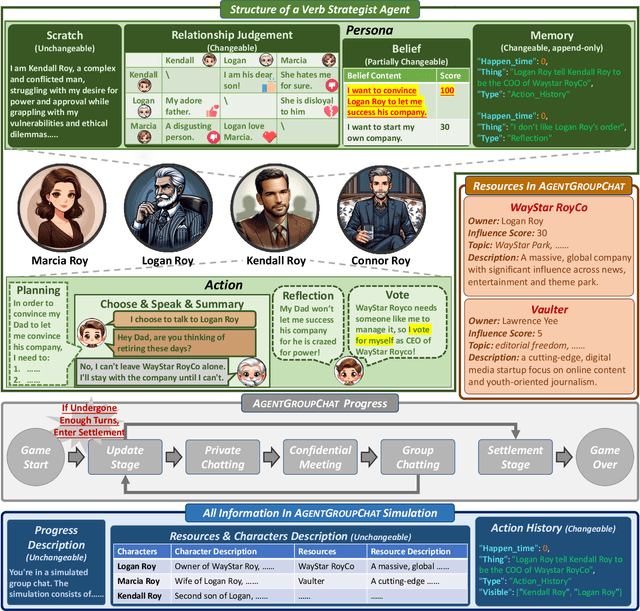
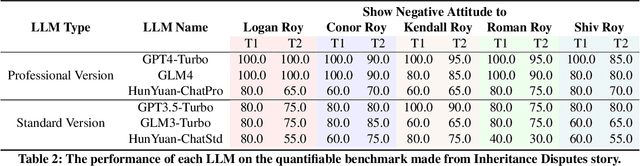
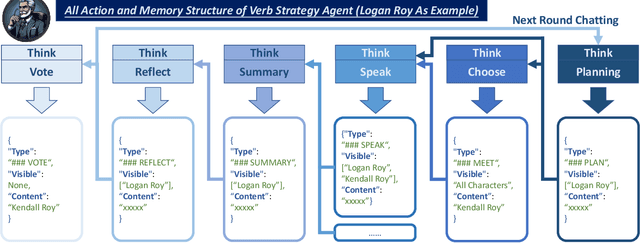
To investigate the role of language in human collective behaviors, we developed the Agent Group Chat simulation to simulate linguistic interactions among multi-agent in different settings. Agents are asked to free chat in this simulation for their own purposes based on their character setting, aiming to see agents exhibit emergent behaviours that are both unforeseen and significant. Four narrative scenarios, Inheritance Disputes, Law Court Debates, Philosophical Discourses, Movie Casting Contention, are integrated into Agent Group Chat to evaluate its support for diverse storylines. By configuring specific environmental settings within Agent Group Chat, we are able to assess whether agents exhibit behaviors that align with human expectations. We evaluate the disorder within the environment by computing the n-gram Shannon entropy of all the content speak by characters. Our findings reveal that under the premise of agents possessing substantial alignment with human expectations, facilitating more extensive information exchange within the simulation ensures greater orderliness amidst diversity, which leads to the emergence of more unexpected and meaningful emergent behaviors. The code is open source in https://github.com/MikeGu721/AgentGroup, and online platform will be open soon.
Tapilot-Crossing: Benchmarking and Evolving LLMs Towards Interactive Data Analysis Agents
Mar 08, 2024
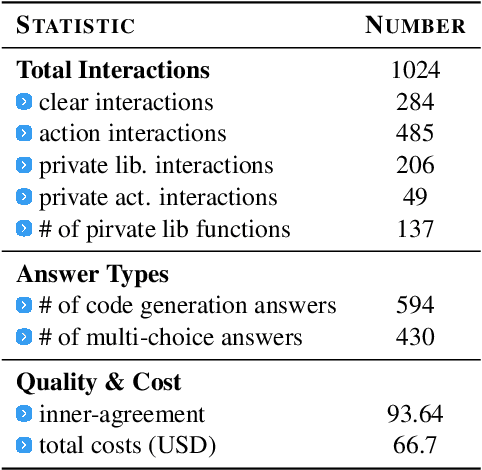
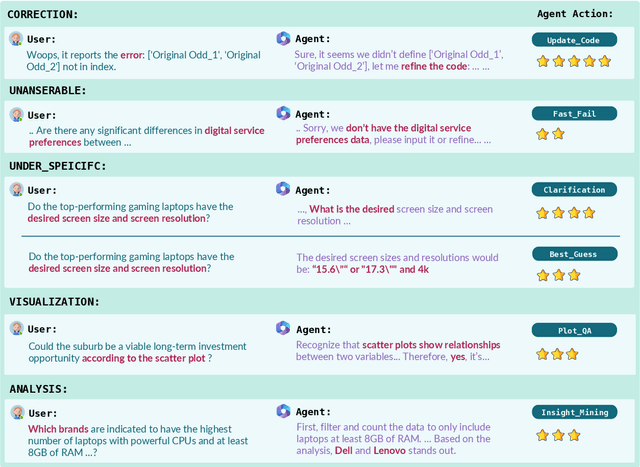
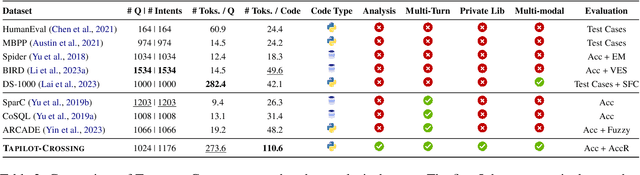
Interactive Data Analysis, the collaboration between humans and LLM agents, enables real-time data exploration for informed decision-making. The challenges and costs of collecting realistic interactive logs for data analysis hinder the quantitative evaluation of Large Language Model (LLM) agents in this task. To mitigate this issue, we introduce Tapilot-Crossing, a new benchmark to evaluate LLM agents on interactive data analysis. Tapilot-Crossing contains 1024 interactions, covering 4 practical scenarios: Normal, Action, Private, and Private Action. Notably, Tapilot-Crossing is constructed by an economical multi-agent environment, Decision Company, with few human efforts. We evaluate popular and advanced LLM agents in Tapilot-Crossing, which underscores the challenges of interactive data analysis. Furthermore, we propose Adaptive Interaction Reflection (AIR), a self-generated reflection strategy that guides LLM agents to learn from successful history. Experiments demonstrate that Air can evolve LLMs into effective interactive data analysis agents, achieving a relative performance improvement of up to 44.5%.
NoteLLM: A Retrievable Large Language Model for Note Recommendation
Mar 04, 2024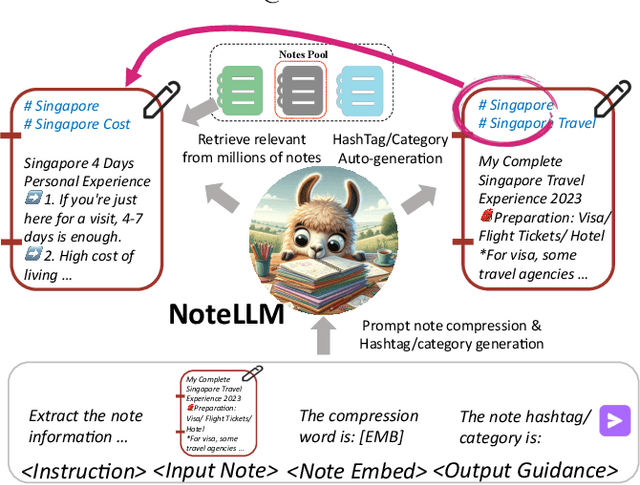
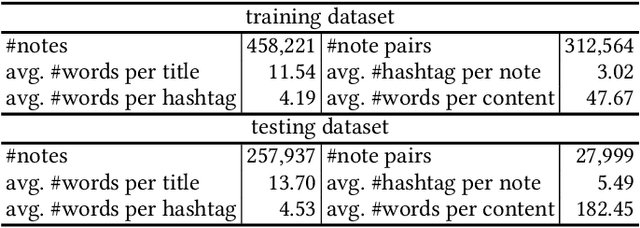
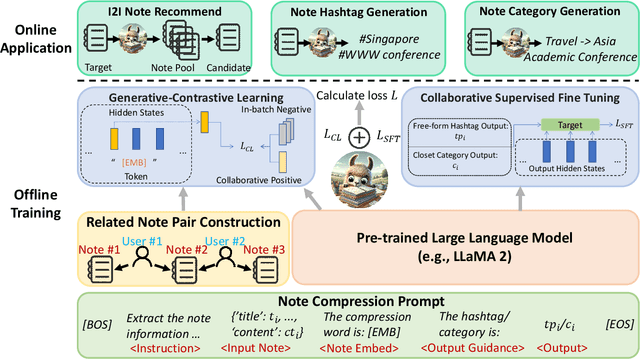
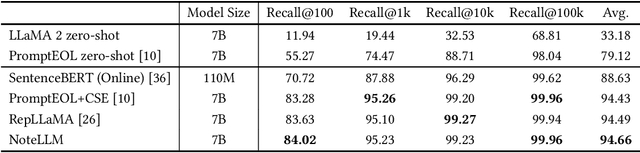
People enjoy sharing "notes" including their experiences within online communities. Therefore, recommending notes aligned with user interests has become a crucial task. Existing online methods only input notes into BERT-based models to generate note embeddings for assessing similarity. However, they may underutilize some important cues, e.g., hashtags or categories, which represent the key concepts of notes. Indeed, learning to generate hashtags/categories can potentially enhance note embeddings, both of which compress key note information into limited content. Besides, Large Language Models (LLMs) have significantly outperformed BERT in understanding natural languages. It is promising to introduce LLMs into note recommendation. In this paper, we propose a novel unified framework called NoteLLM, which leverages LLMs to address the item-to-item (I2I) note recommendation. Specifically, we utilize Note Compression Prompt to compress a note into a single special token, and further learn the potentially related notes' embeddings via a contrastive learning approach. Moreover, we use NoteLLM to summarize the note and generate the hashtag/category automatically through instruction tuning. Extensive validations on real scenarios demonstrate the effectiveness of our proposed method compared with the online baseline and show major improvements in the recommendation system of Xiaohongshu.
NL2Formula: Generating Spreadsheet Formulas from Natural Language Queries
Feb 20, 2024Writing formulas on spreadsheets, such as Microsoft Excel and Google Sheets, is a widespread practice among users performing data analysis. However, crafting formulas on spreadsheets remains a tedious and error-prone task for many end-users, particularly when dealing with complex operations. To alleviate the burden associated with writing spreadsheet formulas, this paper introduces a novel benchmark task called NL2Formula, with the aim to generate executable formulas that are grounded on a spreadsheet table, given a Natural Language (NL) query as input. To accomplish this, we construct a comprehensive dataset consisting of 70,799 paired NL queries and corresponding spreadsheet formulas, covering 21,670 tables and 37 types of formula functions. We realize the NL2Formula task by providing a sequence-to-sequence baseline implementation called fCoder. Experimental results validate the effectiveness of fCoder, demonstrating its superior performance compared to the baseline models. Furthermore, we also compare fCoder with an initial GPT-3.5 model (i.e., text-davinci-003). Lastly, through in-depth error analysis, we identify potential challenges in the NL2Formula task and advocate for further investigation.
FedAnchor: Enhancing Federated Semi-Supervised Learning with Label Contrastive Loss for Unlabeled Clients
Feb 15, 2024Federated learning (FL) is a distributed learning paradigm that facilitates collaborative training of a shared global model across devices while keeping data localized. The deployment of FL in numerous real-world applications faces delays, primarily due to the prevalent reliance on supervised tasks. Generating detailed labels at edge devices, if feasible, is demanding, given resource constraints and the imperative for continuous data updates. In addressing these challenges, solutions such as federated semi-supervised learning (FSSL), which relies on unlabeled clients' data and a limited amount of labeled data on the server, become pivotal. In this paper, we propose FedAnchor, an innovative FSSL method that introduces a unique double-head structure, called anchor head, paired with the classification head trained exclusively on labeled anchor data on the server. The anchor head is empowered with a newly designed label contrastive loss based on the cosine similarity metric. Our approach mitigates the confirmation bias and overfitting issues associated with pseudo-labeling techniques based on high-confidence model prediction samples. Extensive experiments on CIFAR10/100 and SVHN datasets demonstrate that our method outperforms the state-of-the-art method by a significant margin in terms of convergence rate and model accuracy.
Text2Analysis: A Benchmark of Table Question Answering with Advanced Data Analysis and Unclear Queries
Dec 21, 2023Tabular data analysis is crucial in various fields, and large language models show promise in this area. However, current research mostly focuses on rudimentary tasks like Text2SQL and TableQA, neglecting advanced analysis like forecasting and chart generation. To address this gap, we developed the Text2Analysis benchmark, incorporating advanced analysis tasks that go beyond the SQL-compatible operations and require more in-depth analysis. We also develop five innovative and effective annotation methods, harnessing the capabilities of large language models to enhance data quality and quantity. Additionally, we include unclear queries that resemble real-world user questions to test how well models can understand and tackle such challenges. Finally, we collect 2249 query-result pairs with 347 tables. We evaluate five state-of-the-art models using three different metrics and the results show that our benchmark presents introduces considerable challenge in the field of tabular data analysis, paving the way for more advanced research opportunities.
Multi-Scene Generalized Trajectory Global Graph Solver with Composite Nodes for Multiple Object Tracking
Dec 14, 2023The global multi-object tracking (MOT) system can consider interaction, occlusion, and other ``visual blur'' scenarios to ensure effective object tracking in long videos. Among them, graph-based tracking-by-detection paradigms achieve surprising performance. However, their fully-connected nature poses storage space requirements that challenge algorithm handling long videos. Currently, commonly used methods are still generated trajectories by building one-forward associations across frames. Such matches produced under the guidance of first-order similarity information may not be optimal from a longer-time perspective. Moreover, they often lack an end-to-end scheme for correcting mismatches. This paper proposes the Composite Node Message Passing Network (CoNo-Link), a multi-scene generalized framework for modeling ultra-long frames information for association. CoNo-Link's solution is a low-storage overhead method for building constrained connected graphs. In addition to the previous method of treating objects as nodes, the network innovatively treats object trajectories as nodes for information interaction, improving the graph neural network's feature representation capability. Specifically, we formulate the graph-building problem as a top-k selection task for some reliable objects or trajectories. Our model can learn better predictions on longer-time scales by adding composite nodes. As a result, our method outperforms the state-of-the-art in several commonly used datasets.
Towards the Law of Capacity Gap in Distilling Language Models
Nov 13, 2023Language model (LM) distillation is a trending area that aims to distil the knowledge resided in a large teacher LM to a small student one. While various methods have been proposed to push the distillation to its limits, it is still a pain distilling LMs when a large capacity gap is exhibited between the teacher and the student LMs. The pain is mainly resulted by the curse of capacity gap, which describes that a larger teacher LM cannot always lead to a better student LM than one distilled from a smaller teacher LM due to the affect of capacity gap increment. That is, there is likely an optimal point yielding the best student LM along the scaling course of the teacher LM. Even worse, the curse of capacity gap can be only partly yet not fully lifted as indicated in previous studies. However, the tale is not ever one-sided. Although a larger teacher LM has better performance than a smaller teacher LM, it is much more resource-demanding especially in the context of recent large LMs (LLMs). Consequently, instead of sticking to lifting the curse, leaving the curse as is should be arguably fine. Even better, in this paper, we reveal that the optimal capacity gap is almost consistent across different student scales and architectures, fortunately turning the curse into the law of capacity gap. The law later guides us to distil a 3B student LM (termed MiniMA) from a 7B teacher LM (adapted LLaMA2-7B). MiniMA is demonstrated to yield a new compute-performance pareto frontier among existing 3B LMs on commonly used benchmarks, and its instruction-tuned version (termed MiniChat) outperforms a wide range of 3B competitors in GPT4 evaluation and could even compete with several 7B chat models.
A Survey on Passing-through Control of Multi-Robot Systems in Cluttered Environments
Nov 13, 2023This survey presents a comprehensive review of various methods and algorithms related to passing-through control of multi-robot systems in cluttered environments. Numerous studies have investigated this area, and we identify several avenues for enhancing existing methods. This survey describes some models of robots and commonly considered control objectives, followed by an in-depth analysis of four types of algorithms that can be employed for passing-through control: leader-follower formation control, multi-robot trajectory planning, control-based methods, and virtual tube planning and control. Furthermore, we conduct a comparative analysis of these techniques and provide some subjective and general evaluations.