 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZihan Ding
V2X-PC: Vehicle-to-everything Collaborative Perception via Point Cluster
Mar 25, 2024

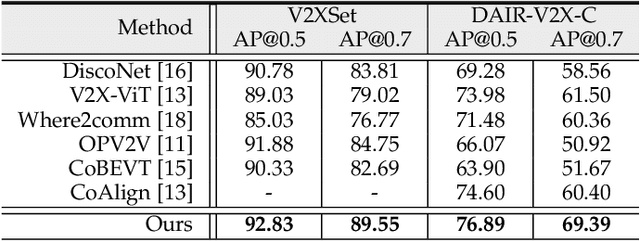
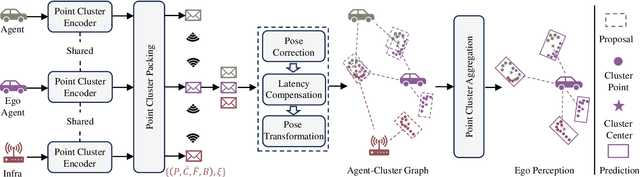

The objective of the collaborative vehicle-to-everything perception task is to enhance the individual vehicle's perception capability through message communication among neighboring traffic agents. Previous methods focus on achieving optimal performance within bandwidth limitations and typically adopt BEV maps as the basic collaborative message units. However, we demonstrate that collaboration with dense representations is plagued by object feature destruction during message packing, inefficient message aggregation for long-range collaboration, and implicit structure representation communication. To tackle these issues, we introduce a brand new message unit, namely point cluster, designed to represent the scene sparsely with a combination of low-level structure information and high-level semantic information. The point cluster inherently preserves object information while packing messages, with weak relevance to the collaboration range, and supports explicit structure modeling. Building upon this representation, we propose a novel framework V2X-PC for collaborative perception. This framework includes a Point Cluster Packing (PCP) module to keep object feature and manage bandwidth through the manipulation of cluster point numbers. As for effective message aggregation, we propose a Point Cluster Aggregation (PCA) module to match and merge point clusters associated with the same object. To further handle time latency and pose errors encountered in real-world scenarios, we propose parameter-free solutions that can adapt to different noisy levels without finetuning. Experiments on two widely recognized collaborative perception benchmarks showcase the superior performance of our method compared to the previous state-of-the-art approaches relying on BEV maps.
Efficient and Guaranteed-Safe Non-Convex Trajectory Optimization with Constrained Diffusion Model
Feb 22, 2024
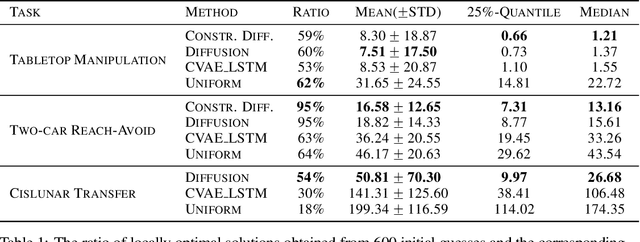
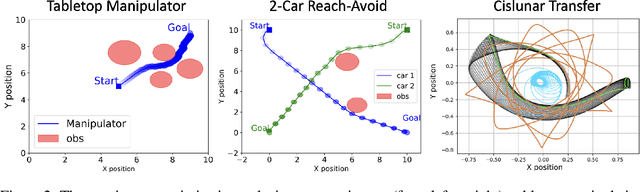

Trajectory optimization in robotics poses a challenging non-convex problem due to complex dynamics and environmental settings. Traditional numerical optimization methods are time-consuming in finding feasible solutions, whereas data-driven approaches lack safety guarantees for the output trajectories. In this paper, we introduce a general and fully parallelizable framework that combines diffusion models and numerical solvers for non-convex trajectory optimization, ensuring both computational efficiency and constraint satisfaction. A novel constrained diffusion model is proposed with an additional constraint violation loss for training. It aims to approximate the distribution of locally optimal solutions while minimizing constraint violations during sampling. The samples are then used as initial guesses for a numerical solver to refine and derive final solutions with formal verification of feasibility and optimality. Experimental evaluations on three tasks over different robotics domains verify the improved constraint satisfaction and computational efficiency with 4$\times$ to 22$\times$ acceleration using our proposed method, which generalizes across trajectory optimization problems and scales well with problem complexity.
Diffusion World Model
Feb 11, 2024We introduce Diffusion World Model (DWM), a conditional diffusion model capable of predicting multistep future states and rewards concurrently. As opposed to traditional one-step dynamics models, DWM offers long-horizon predictions in a single forward pass, eliminating the need for recursive queries. We integrate DWM into model-based value estimation, where the short-term return is simulated by future trajectories sampled from DWM. In the context of offline reinforcement learning, DWM can be viewed as a conservative value regularization through generative modeling. Alternatively, it can be seen as a data source that enables offline Q-learning with synthetic data. Our experiments on the D4RL dataset confirm the robustness of DWM to long-horizon simulation. In terms of absolute performance, DWM significantly surpasses one-step dynamics models with a $44\%$ performance gain, and achieves state-of-the-art performance.
Enriching Phrases with Coupled Pixel and Object Contexts for Panoptic Narrative Grounding
Nov 02, 2023Panoptic narrative grounding (PNG) aims to segment things and stuff objects in an image described by noun phrases of a narrative caption. As a multimodal task, an essential aspect of PNG is the visual-linguistic interaction between image and caption. The previous two-stage method aggregates visual contexts from offline-generated mask proposals to phrase features, which tend to be noisy and fragmentary. The recent one-stage method aggregates only pixel contexts from image features to phrase features, which may incur semantic misalignment due to lacking object priors. To realize more comprehensive visual-linguistic interaction, we propose to enrich phrases with coupled pixel and object contexts by designing a Phrase-Pixel-Object Transformer Decoder (PPO-TD), where both fine-grained part details and coarse-grained entity clues are aggregated to phrase features. In addition, we also propose a PhraseObject Contrastive Loss (POCL) to pull closer the matched phrase-object pairs and push away unmatched ones for aggregating more precise object contexts from more phrase-relevant object tokens. Extensive experiments on the PNG benchmark show our method achieves new state-of-the-art performance with large margins.
Consistency Models as a Rich and Efficient Policy Class for Reinforcement Learning
Sep 29, 2023Score-based generative models like the diffusion model have been testified to be effective in modeling multi-modal data from image generation to reinforcement learning (RL). However, the inference process of diffusion model can be slow, which hinders its usage in RL with iterative sampling. We propose to apply the consistency model as an efficient yet expressive policy representation, namely consistency policy, with an actor-critic style algorithm for three typical RL settings: offline, offline-to-online and online. For offline RL, we demonstrate the expressiveness of generative models as policies from multi-modal data. For offline-to-online RL, the consistency policy is shown to be more computational efficient than diffusion policy, with a comparable performance. For online RL, the consistency policy demonstrates significant speedup and even higher average performances than the diffusion policy.
Survey of Consciousness Theory from Computational Perspective
Sep 18, 2023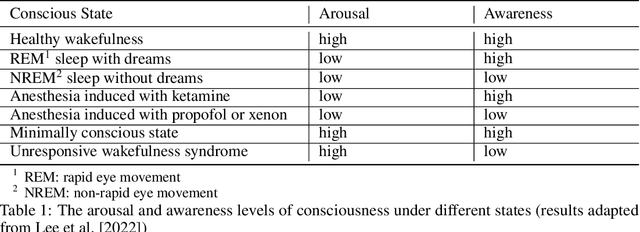


Human consciousness has been a long-lasting mystery for centuries, while machine intelligence and consciousness is an arduous pursuit. Researchers have developed diverse theories for interpreting the consciousness phenomenon in human brains from different perspectives and levels. This paper surveys several main branches of consciousness theories originating from different subjects including information theory, quantum physics, cognitive psychology, physiology and computer science, with the aim of bridging these theories from a computational perspective. It also discusses the existing evaluation metrics of consciousness and possibility for current computational models to be conscious. Breaking the mystery of consciousness can be an essential step in building general artificial intelligence with computing machines.
Learning a Universal Human Prior for Dexterous Manipulation from Human Preference
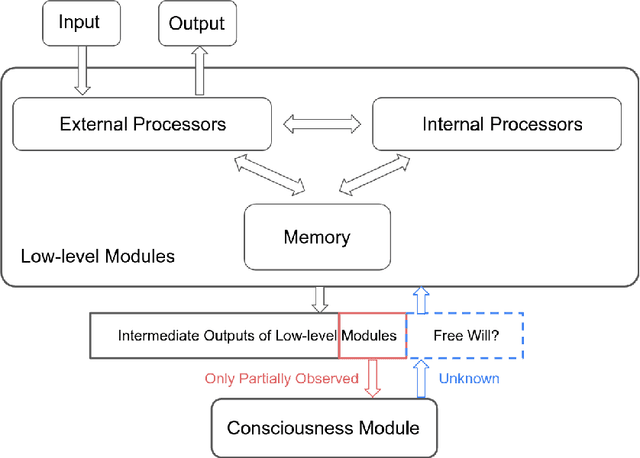
Apr 10, 2023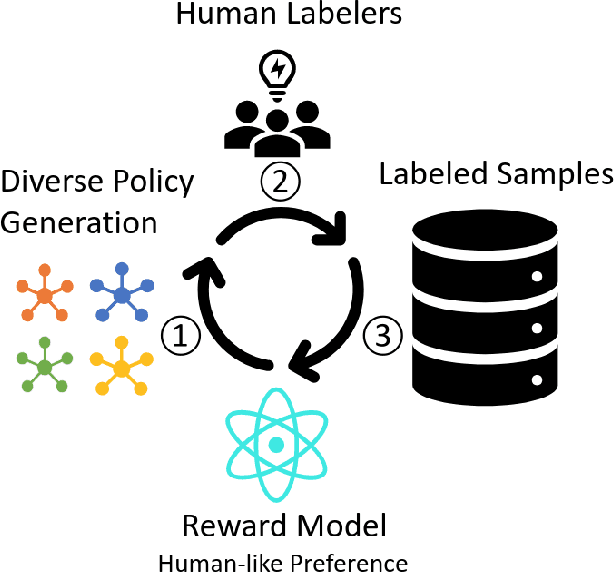

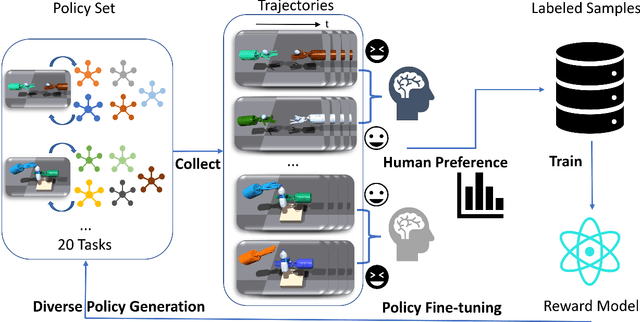
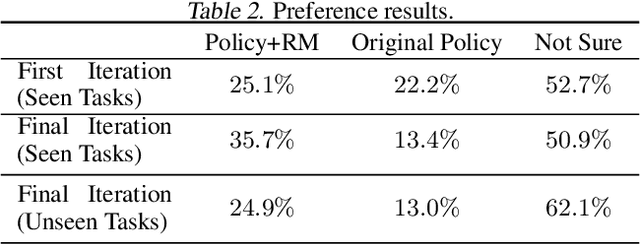
Generating human-like behavior on robots is a great challenge especially in dexterous manipulation tasks with robotic hands. Even in simulation with no sample constraints, scripting controllers is intractable due to high degrees of freedom, and manual reward engineering can also be hard and lead to non-realistic motions. Leveraging the recent progress on Reinforcement Learning from Human Feedback (RLHF), we propose a framework to learn a universal human prior using direct human preference feedback over videos, for efficiently tuning the RL policy on 20 dual-hand robot manipulation tasks in simulation, without a single human demonstration. One task-agnostic reward model is trained through iteratively generating diverse polices and collecting human preference over the trajectories; it is then applied for regularizing the behavior of polices in the fine-tuning stage. Our method empirically demonstrates more human-like behaviors on robot hands in diverse tasks including even unseen tasks, indicating its generalization capability.
Object-Aware Distillation Pyramid for Open-Vocabulary Object Detection
Mar 10, 2023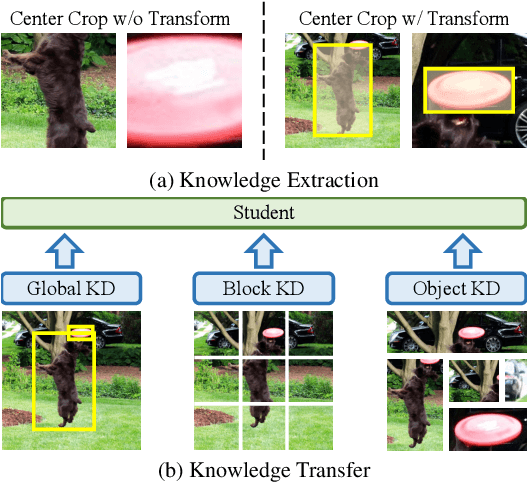

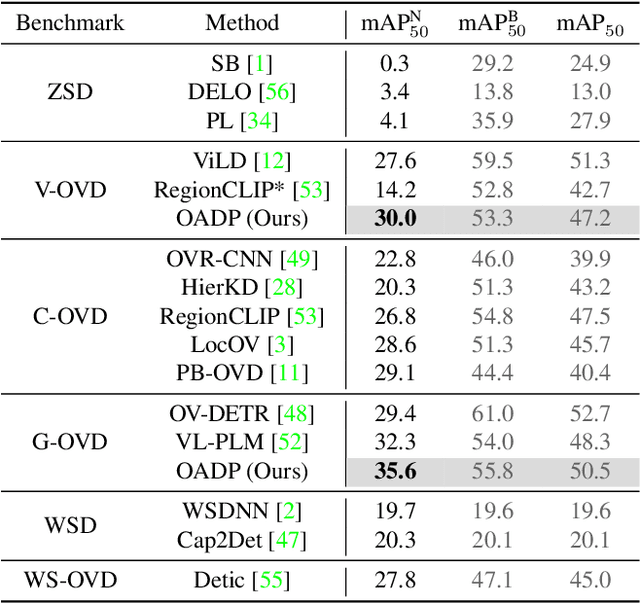
Open-vocabulary object detection aims to provide object detectors trained on a fixed set of object categories with the generalizability to detect objects described by arbitrary text queries. Previous methods adopt knowledge distillation to extract knowledge from Pretrained Vision-and-Language Models (PVLMs) and transfer it to detectors. However, due to the non-adaptive proposal cropping and single-level feature mimicking processes, they suffer from information destruction during knowledge extraction and inefficient knowledge transfer. To remedy these limitations, we propose an Object-Aware Distillation Pyramid (OADP) framework, including an Object-Aware Knowledge Extraction (OAKE) module and a Distillation Pyramid (DP) mechanism. When extracting object knowledge from PVLMs, the former adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects. The latter introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation. Extensive experiments show that our method achieves significant improvement compared to current methods. Especially on the MS-COCO dataset, our OADP framework reaches $35.6$ mAP$^{\text{N}}_{50}$, surpassing the current state-of-the-art method by $3.3$ mAP$^{\text{N}}_{50}$. Code is released at https://github.com/LutingWang/OADP.
Anchor3DLane: Learning to Regress 3D Anchors for Monocular 3D Lane Detection
Jan 06, 2023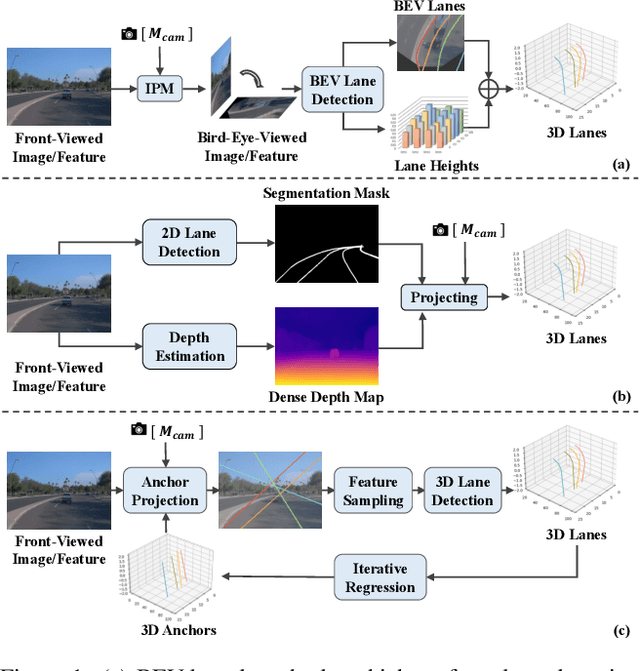
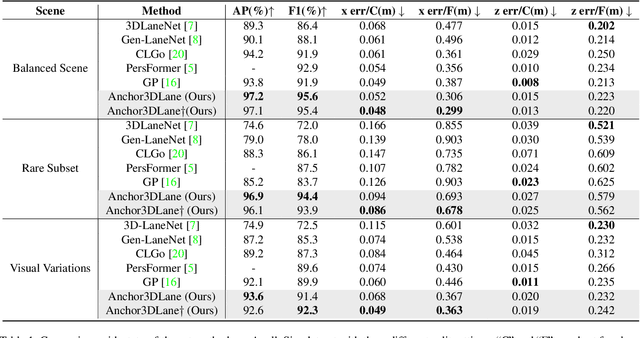
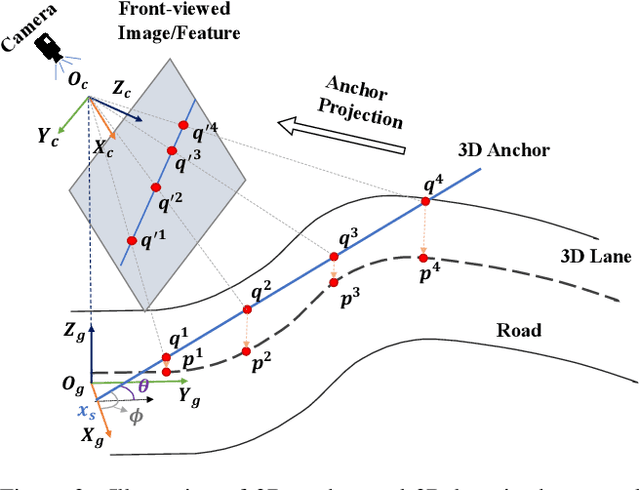
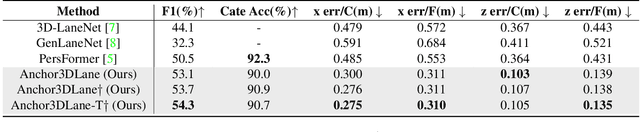
Monocular 3D lane detection is a challenging task due to its lack of depth information. A popular solution to 3D lane detection is to first transform the front-viewed (FV) images or features into the bird-eye-view (BEV) space with inverse perspective mapping (IPM) and detect lanes from BEV features. However, the reliance of IPM on flat ground assumption and loss of context information makes it inaccurate to restore 3D information from BEV representations. An attempt has been made to get rid of BEV and predict 3D lanes from FV representations directly, while it still underperforms other BEV-based methods given its lack of structured representation for 3D lanes. In this paper, we define 3D lane anchors in the 3D space and propose a BEV-free method named Anchor3DLane to predict 3D lanes directly from FV representations. 3D lane anchors are projected to the FV features to extract their features which contain both good structural and context information to make accurate predictions. We further extend Anchor3DLane to the multi-frame setting to incorporate temporal information for performance improvement. In addition, we also develop a global optimization method that makes use of the equal-width property between lanes to reduce the lateral error of predictions. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane outperforms previous BEV-based methods and achieves state-of-the-art performances.
PPMN: Pixel-Phrase Matching Network for One-Stage Panoptic Narrative Grounding
Aug 11, 2022

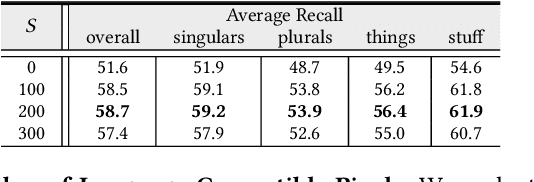
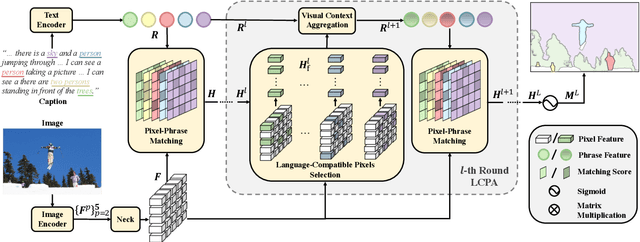
Panoptic Narrative Grounding (PNG) is an emerging task whose goal is to segment visual objects of things and stuff categories described by dense narrative captions of a still image. The previous two-stage approach first extracts segmentation region proposals by an off-the-shelf panoptic segmentation model, then conducts coarse region-phrase matching to ground the candidate regions for each noun phrase. However, the two-stage pipeline usually suffers from the performance limitation of low-quality proposals in the first stage and the loss of spatial details caused by region feature pooling, as well as complicated strategies designed for things and stuff categories separately. To alleviate these drawbacks, we propose a one-stage end-to-end Pixel-Phrase Matching Network (PPMN), which directly matches each phrase to its corresponding pixels instead of region proposals and outputs panoptic segmentation by simple combination. Thus, our model can exploit sufficient and finer cross-modal semantic correspondence from the supervision of densely annotated pixel-phrase pairs rather than sparse region-phrase pairs. In addition, we also propose a Language-Compatible Pixel Aggregation (LCPA) module to further enhance the discriminative ability of phrase features through multi-round refinement, which selects the most compatible pixels for each phrase to adaptively aggregate the corresponding visual context. Extensive experiments show that our method achieves new state-of-the-art performance on the PNG benchmark with 4.0 absolute Average Recall gains.