 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLuting Wang
Object-Aware Distillation Pyramid for Open-Vocabulary Object Detection
Mar 10, 2023
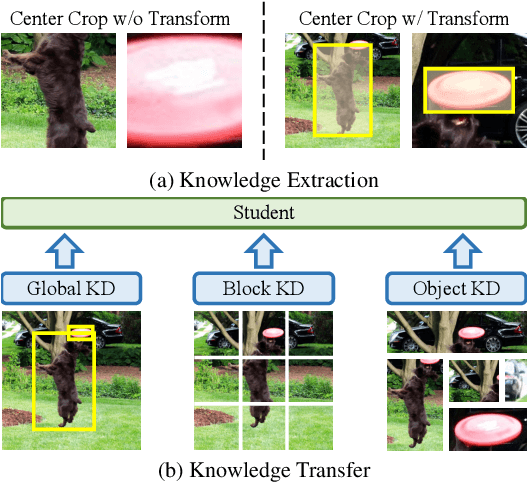
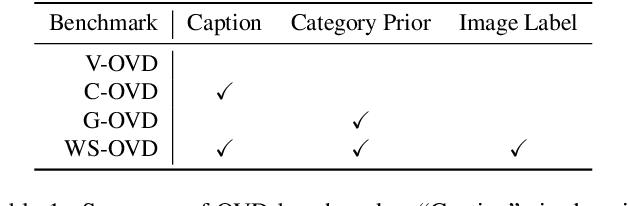

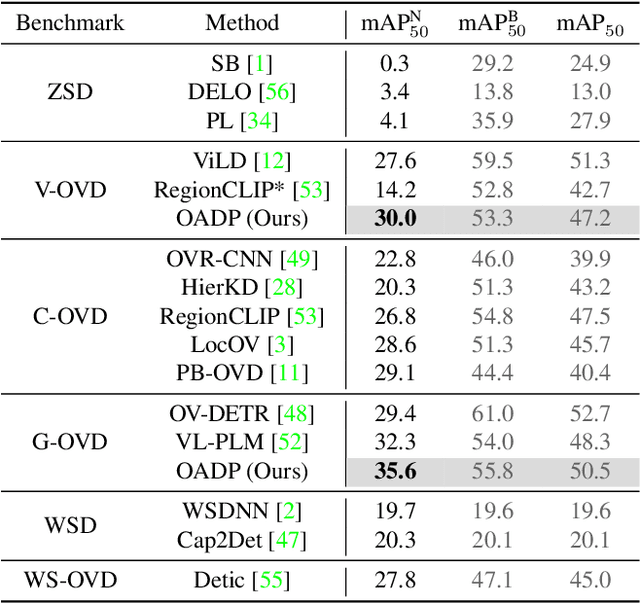
Open-vocabulary object detection aims to provide object detectors trained on a fixed set of object categories with the generalizability to detect objects described by arbitrary text queries. Previous methods adopt knowledge distillation to extract knowledge from Pretrained Vision-and-Language Models (PVLMs) and transfer it to detectors. However, due to the non-adaptive proposal cropping and single-level feature mimicking processes, they suffer from information destruction during knowledge extraction and inefficient knowledge transfer. To remedy these limitations, we propose an Object-Aware Distillation Pyramid (OADP) framework, including an Object-Aware Knowledge Extraction (OAKE) module and a Distillation Pyramid (DP) mechanism. When extracting object knowledge from PVLMs, the former adaptively transforms object proposals and adopts object-aware mask attention to obtain precise and complete knowledge of objects. The latter introduces global and block distillation for more comprehensive knowledge transfer to compensate for the missing relation information in object distillation. Extensive experiments show that our method achieves significant improvement compared to current methods. Especially on the MS-COCO dataset, our OADP framework reaches $35.6$ mAP$^{\text{N}}_{50}$, surpassing the current state-of-the-art method by $3.3$ mAP$^{\text{N}}_{50}$. Code is released at https://github.com/LutingWang/OADP.
HEAD: HEtero-Assists Distillation for Heterogeneous Object Detectors
Jul 12, 2022
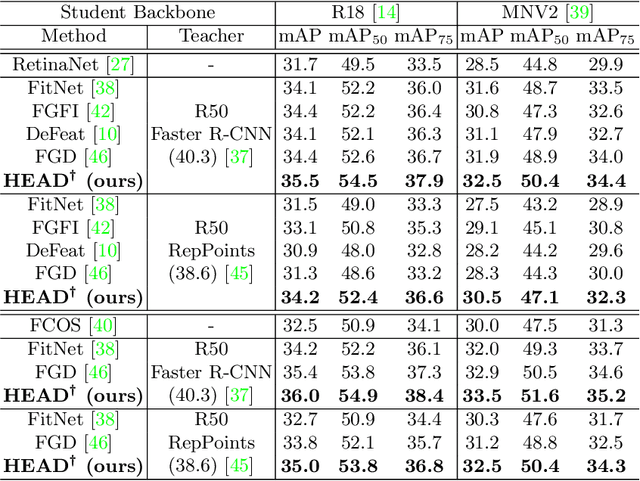
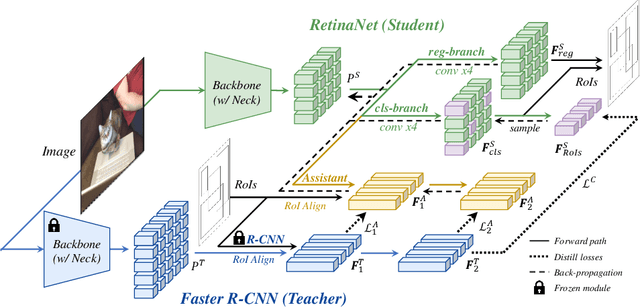
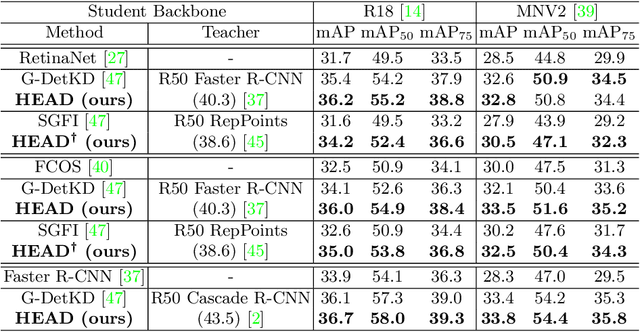
Conventional knowledge distillation (KD) methods for object detection mainly concentrate on homogeneous teacher-student detectors. However, the design of a lightweight detector for deployment is often significantly different from a high-capacity detector. Thus, we investigate KD among heterogeneous teacher-student pairs for a wide application. We observe that the core difficulty for heterogeneous KD (hetero-KD) is the significant semantic gap between the backbone features of heterogeneous detectors due to the different optimization manners. Conventional homogeneous KD (homo-KD) methods suffer from such a gap and are hard to directly obtain satisfactory performance for hetero-KD. In this paper, we propose the HEtero-Assists Distillation (HEAD) framework, leveraging heterogeneous detection heads as assistants to guide the optimization of the student detector to reduce this gap. In HEAD, the assistant is an additional detection head with the architecture homogeneous to the teacher head attached to the student backbone. Thus, a hetero-KD is transformed into a homo-KD, allowing efficient knowledge transfer from the teacher to the student. Moreover, we extend HEAD into a Teacher-Free HEAD (TF-HEAD) framework when a well-trained teacher detector is unavailable. Our method has achieved significant improvement compared to current detection KD methods. For example, on the MS-COCO dataset, TF-HEAD helps R18 RetinaNet achieve 33.9 mAP (+2.2), while HEAD further pushes the limit to 36.2 mAP (+4.5).