 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaofei Huang
Mask-Enhanced Segment Anything Model for Tumor Lesion Semantic Segmentation
Mar 09, 2024
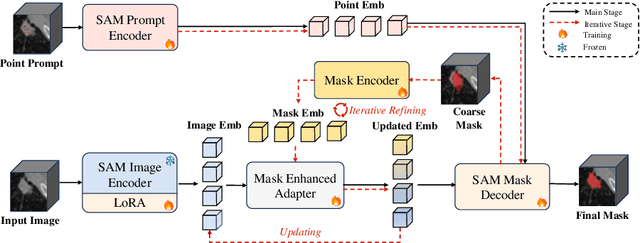
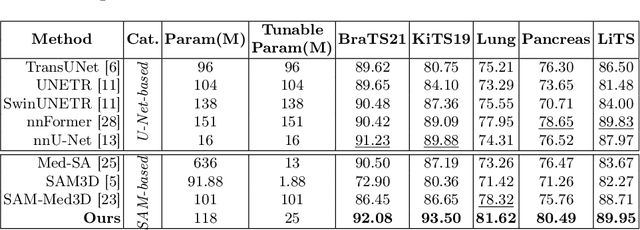
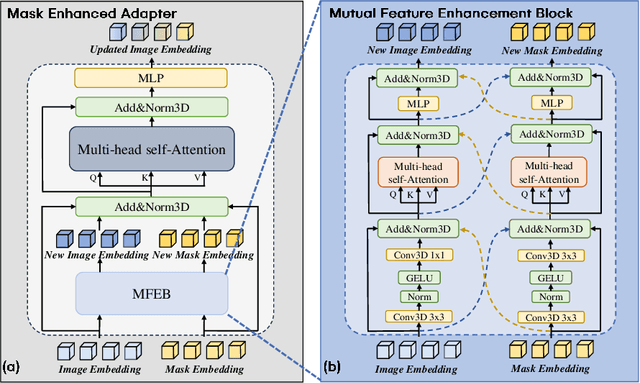
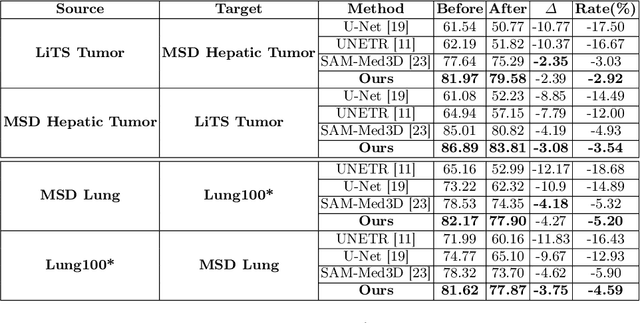
Tumor lesion segmentation on CT or MRI images plays a critical role in cancer diagnosis and treatment planning. Considering the inherent differences in tumor lesion segmentation data across various medical imaging modalities and equipment, integrating medical knowledge into the Segment Anything Model (SAM) presents promising capability due to its versatility and generalization potential. Recent studies have attempted to enhance SAM with medical expertise by pre-training on large-scale medical segmentation datasets. However, challenges still exist in 3D tumor lesion segmentation owing to tumor complexity and the imbalance in foreground and background regions. Therefore, we introduce Mask-Enhanced SAM (M-SAM), an innovative architecture tailored for 3D tumor lesion segmentation. We propose a novel Mask-Enhanced Adapter (MEA) within M-SAM that enriches the semantic information of medical images with positional data from coarse segmentation masks, facilitating the generation of more precise segmentation masks. Furthermore, an iterative refinement scheme is implemented in M-SAM to refine the segmentation masks progressively, leading to improved performance. Extensive experiments on seven tumor lesion segmentation datasets indicate that our M-SAM not only achieves high segmentation accuracy but also exhibits robust generalization.
Transferring CLIP's Knowledge into Zero-Shot Point Cloud Semantic Segmentation
Dec 12, 2023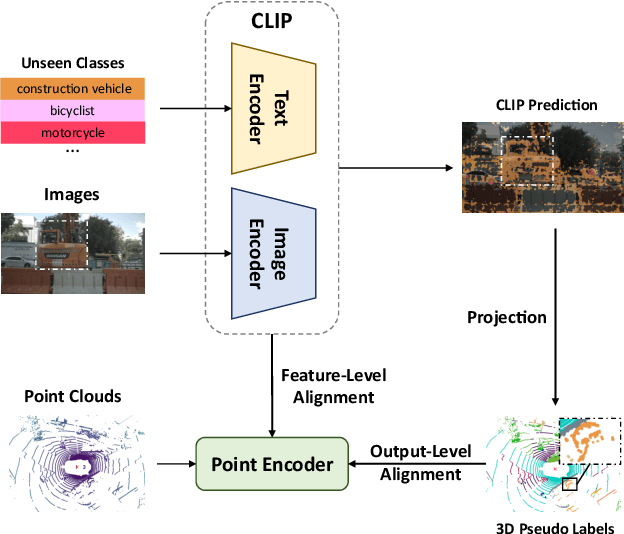
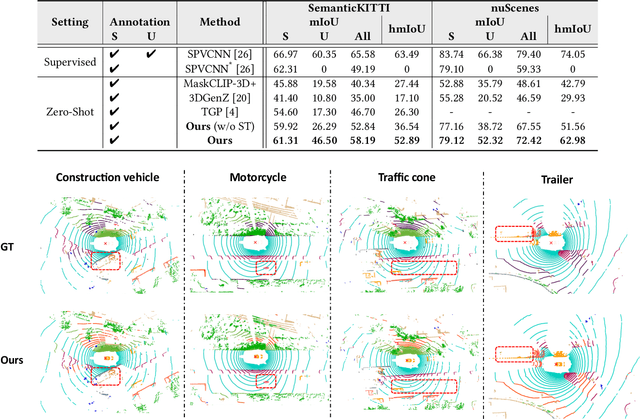
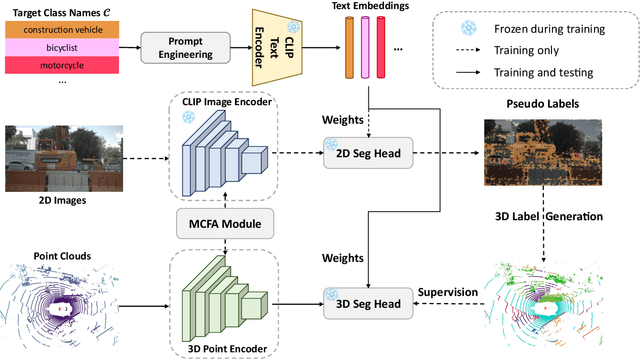
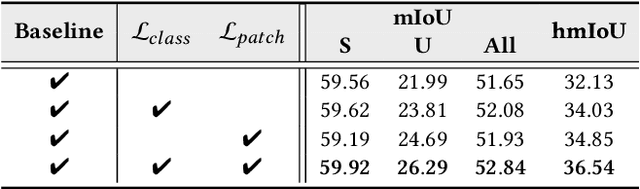
Traditional 3D segmentation methods can only recognize a fixed range of classes that appear in the training set, which limits their application in real-world scenarios due to the lack of generalization ability. Large-scale visual-language pre-trained models, such as CLIP, have shown their generalization ability in the zero-shot 2D vision tasks, but are still unable to be applied to 3D semantic segmentation directly. In this work, we focus on zero-shot point cloud semantic segmentation and propose a simple yet effective baseline to transfer the visual-linguistic knowledge implied in CLIP to point cloud encoder at both feature and output levels. Both feature-level and output-level alignments are conducted between 2D and 3D encoders for effective knowledge transfer. Concretely, a Multi-granularity Cross-modal Feature Alignment (MCFA) module is proposed to align 2D and 3D features from global semantic and local position perspectives for feature-level alignment. For the output level, per-pixel pseudo labels of unseen classes are extracted using the pre-trained CLIP model as supervision for the 3D segmentation model to mimic the behavior of the CLIP image encoder. Extensive experiments are conducted on two popular benchmarks of point cloud segmentation. Our method outperforms significantly previous state-of-the-art methods under zero-shot setting (+29.2% mIoU on SemanticKITTI and 31.8% mIoU on nuScenes), and further achieves promising results in the annotation-free point cloud semantic segmentation setting, showing its great potential for label-efficient learning.
Customize your NeRF: Adaptive Source Driven 3D Scene Editing via Local-Global Iterative Training
Dec 04, 2023In this paper, we target the adaptive source driven 3D scene editing task by proposing a CustomNeRF model that unifies a text description or a reference image as the editing prompt. However, obtaining desired editing results conformed with the editing prompt is nontrivial since there exist two significant challenges, including accurate editing of only foreground regions and multi-view consistency given a single-view reference image. To tackle the first challenge, we propose a Local-Global Iterative Editing (LGIE) training scheme that alternates between foreground region editing and full-image editing, aimed at foreground-only manipulation while preserving the background. For the second challenge, we also design a class-guided regularization that exploits class priors within the generation model to alleviate the inconsistency problem among different views in image-driven editing. Extensive experiments show that our CustomNeRF produces precise editing results under various real scenes for both text- and image-driven settings.
Discovering Sounding Objects by Audio Queries for Audio Visual Segmentation
Sep 18, 2023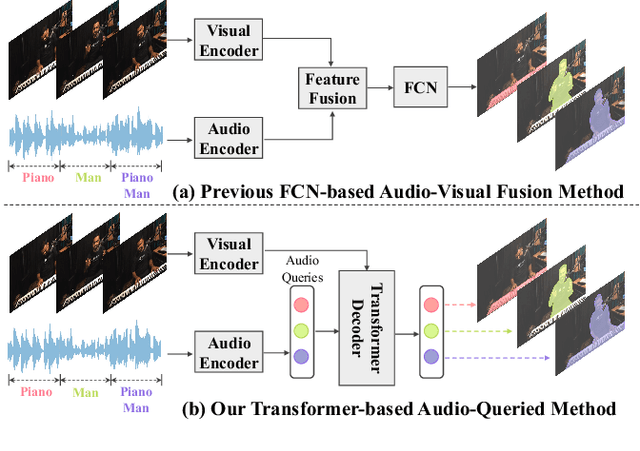
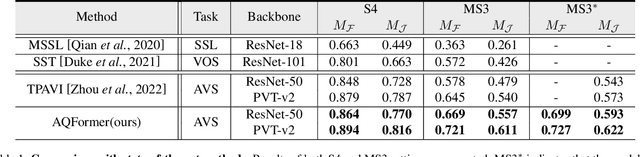
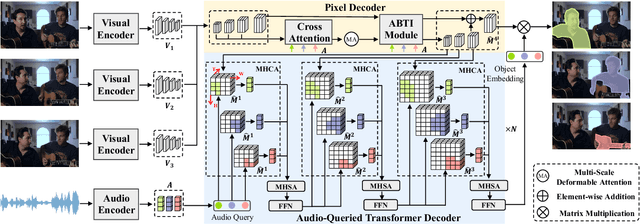

Audio visual segmentation (AVS) aims to segment the sounding objects for each frame of a given video. To distinguish the sounding objects from silent ones, both audio-visual semantic correspondence and temporal interaction are required. The previous method applies multi-frame cross-modal attention to conduct pixel-level interactions between audio features and visual features of multiple frames simultaneously, which is both redundant and implicit. In this paper, we propose an Audio-Queried Transformer architecture, AQFormer, where we define a set of object queries conditioned on audio information and associate each of them to particular sounding objects. Explicit object-level semantic correspondence between audio and visual modalities is established by gathering object information from visual features with predefined audio queries. Besides, an Audio-Bridged Temporal Interaction module is proposed to exchange sounding object-relevant information among multiple frames with the bridge of audio features. Extensive experiments are conducted on two AVS benchmarks to show that our method achieves state-of-the-art performances, especially 7.1% M_J and 7.6% M_F gains on the MS3 setting.
Anchor3DLane: Learning to Regress 3D Anchors for Monocular 3D Lane Detection
Jan 06, 2023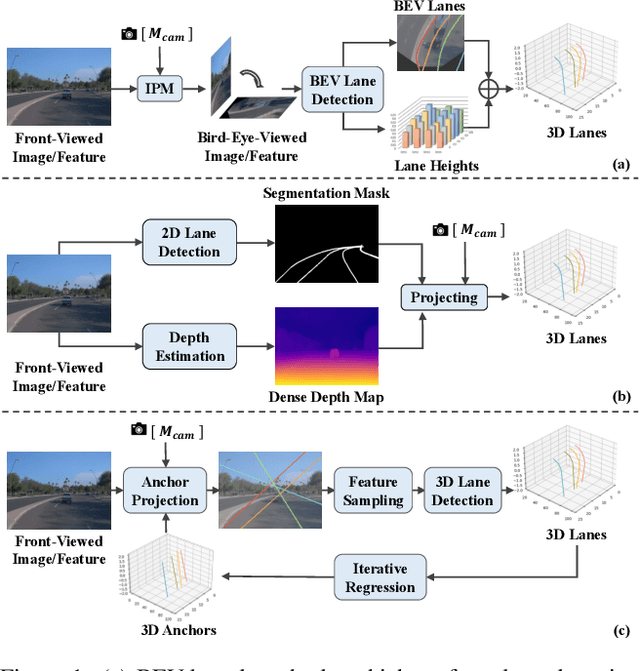
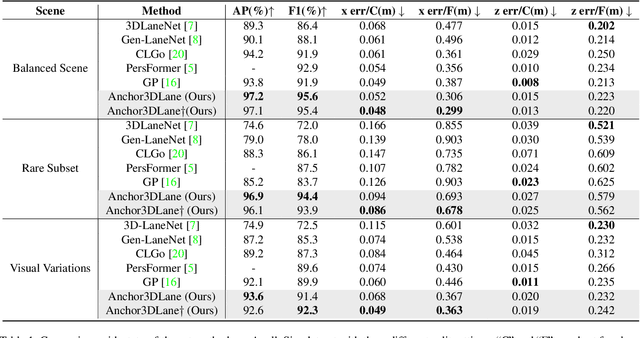
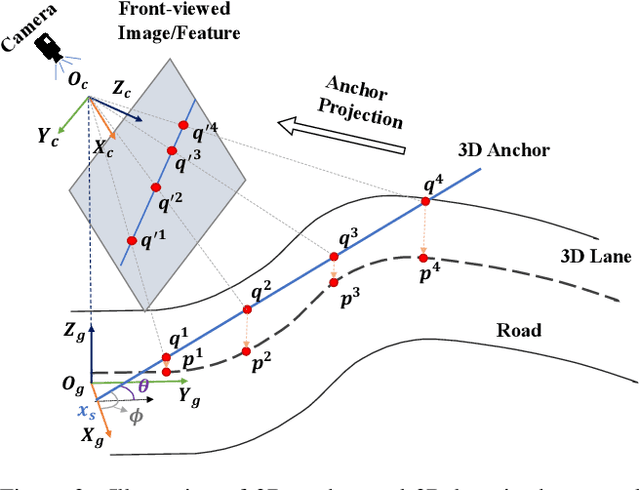
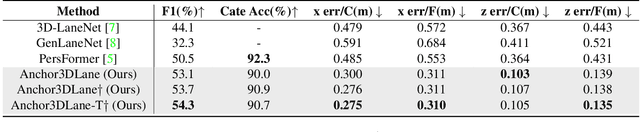
Monocular 3D lane detection is a challenging task due to its lack of depth information. A popular solution to 3D lane detection is to first transform the front-viewed (FV) images or features into the bird-eye-view (BEV) space with inverse perspective mapping (IPM) and detect lanes from BEV features. However, the reliance of IPM on flat ground assumption and loss of context information makes it inaccurate to restore 3D information from BEV representations. An attempt has been made to get rid of BEV and predict 3D lanes from FV representations directly, while it still underperforms other BEV-based methods given its lack of structured representation for 3D lanes. In this paper, we define 3D lane anchors in the 3D space and propose a BEV-free method named Anchor3DLane to predict 3D lanes directly from FV representations. 3D lane anchors are projected to the FV features to extract their features which contain both good structural and context information to make accurate predictions. We further extend Anchor3DLane to the multi-frame setting to incorporate temporal information for performance improvement. In addition, we also develop a global optimization method that makes use of the equal-width property between lanes to reduce the lateral error of predictions. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane outperforms previous BEV-based methods and achieves state-of-the-art performances.
Cross-Modality Domain Adaptation for Freespace Detection: A Simple yet Effective Baseline
Oct 06, 2022
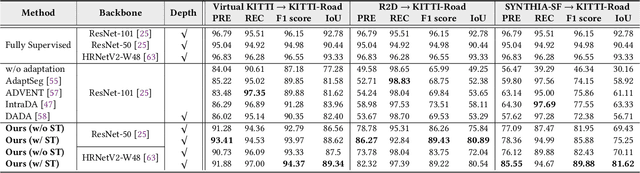
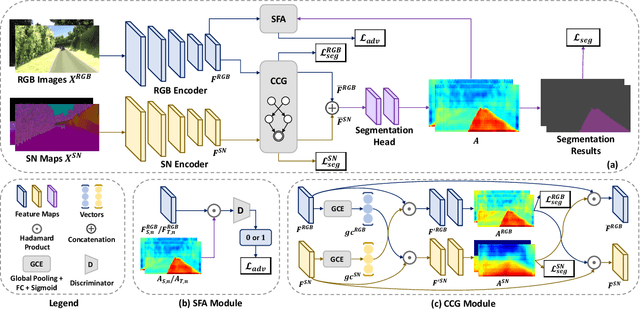
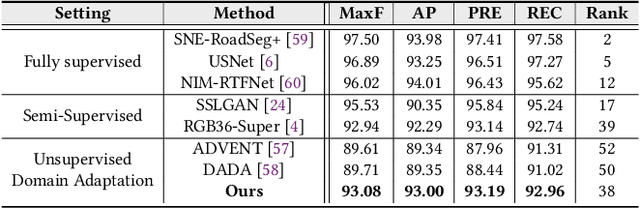
As one of the fundamental functions of autonomous driving system, freespace detection aims at classifying each pixel of the image captured by the camera as drivable or non-drivable. Current works of freespace detection heavily rely on large amount of densely labeled training data for accuracy and robustness, which is time-consuming and laborious to collect and annotate. To the best of our knowledge, we are the first work to explore unsupervised domain adaptation for freespace detection to alleviate the data limitation problem with synthetic data. We develop a cross-modality domain adaptation framework which exploits both RGB images and surface normal maps generated from depth images. A Collaborative Cross Guidance (CCG) module is proposed to leverage the context information of one modality to guide the other modality in a cross manner, thus realizing inter-modality intra-domain complement. To better bridge the domain gap between source domain (synthetic data) and target domain (real-world data), we also propose a Selective Feature Alignment (SFA) module which only aligns the features of consistent foreground area between the two domains, thus realizing inter-domain intra-modality adaptation. Extensive experiments are conducted by adapting three different synthetic datasets to one real-world dataset for freespace detection respectively. Our method performs closely to fully supervised freespace detection methods (93.08 v.s. 97.50 F1 score) and outperforms other general unsupervised domain adaptation methods for semantic segmentation with large margins, which shows the promising potential of domain adaptation for freespace detection.
A Keypoint-based Global Association Network for Lane Detection
Apr 15, 2022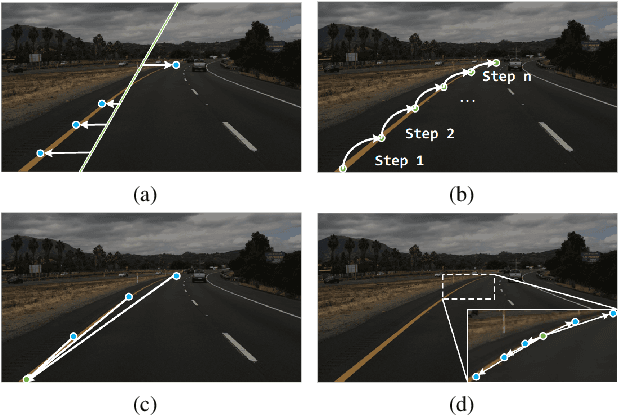

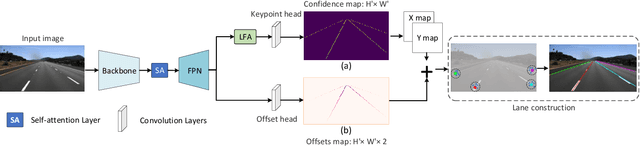
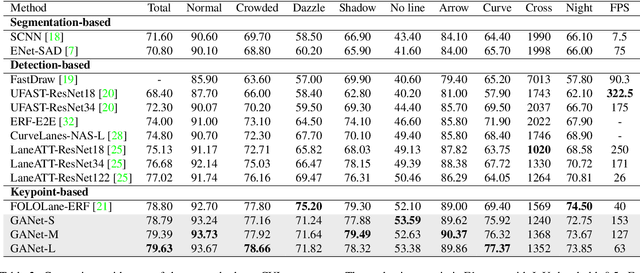
Lane detection is a challenging task that requires predicting complex topology shapes of lane lines and distinguishing different types of lanes simultaneously. Earlier works follow a top-down roadmap to regress predefined anchors into various shapes of lane lines, which lacks enough flexibility to fit complex shapes of lanes due to the fixed anchor shapes. Lately, some works propose to formulate lane detection as a keypoint estimation problem to describe the shapes of lane lines more flexibly and gradually group adjacent keypoints belonging to the same lane line in a point-by-point manner, which is inefficient and time-consuming during postprocessing. In this paper, we propose a Global Association Network (GANet) to formulate the lane detection problem from a new perspective, where each keypoint is directly regressed to the starting point of the lane line instead of point-by-point extension. Concretely, the association of keypoints to their belonged lane line is conducted by predicting their offsets to the corresponding starting points of lanes globally without dependence on each other, which could be done in parallel to greatly improve efficiency. In addition, we further propose a Lane-aware Feature Aggregator (LFA), which adaptively captures the local correlations between adjacent keypoints to supplement local information to the global association. Extensive experiments on two popular lane detection benchmarks show that our method outperforms previous methods with F1 score of 79.63% on CULane and 97.71% on Tusimple dataset with high FPS. The code will be released at https://github.com/Wolfwjs/GANet.
TransRefer3D: Entity-and-Relation Aware Transformer for Fine-Grained 3D Visual Grounding
Aug 11, 2021
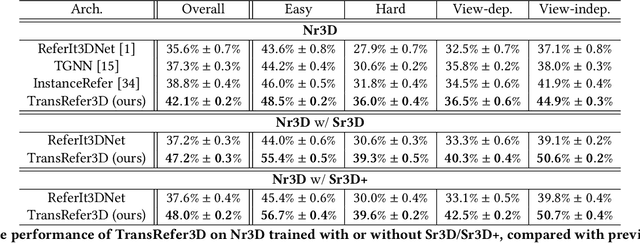


Recently proposed fine-grained 3D visual grounding is an essential and challenging task, whose goal is to identify the 3D object referred by a natural language sentence from other distractive objects of the same category. Existing works usually adopt dynamic graph networks to indirectly model the intra/inter-modal interactions, making the model difficult to distinguish the referred object from distractors due to the monolithic representations of visual and linguistic contents. In this work, we exploit Transformer for its natural suitability on permutation-invariant 3D point clouds data and propose a TransRefer3D network to extract entity-and-relation aware multimodal context among objects for more discriminative feature learning. Concretely, we devise an Entity-aware Attention (EA) module and a Relation-aware Attention (RA) module to conduct fine-grained cross-modal feature matching. Facilitated by co-attention operation, our EA module matches visual entity features with linguistic entity features while RA module matches pair-wise visual relation features with linguistic relation features, respectively. We further integrate EA and RA modules into an Entity-and-Relation aware Contextual Block (ERCB) and stack several ERCBs to form our TransRefer3D for hierarchical multimodal context modeling. Extensive experiments on both Nr3D and Sr3D datasets demonstrate that our proposed model significantly outperforms existing approaches by up to 10.6% and claims the new state-of-the-art. To the best of our knowledge, this is the first work investigating Transformer architecture for fine-grained 3D visual grounding task.
Cross-Modal Progressive Comprehension for Referring Segmentation
May 15, 2021


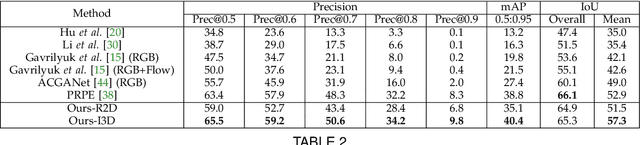
Given a natural language expression and an image/video, the goal of referring segmentation is to produce the pixel-level masks of the entities described by the subject of the expression. Previous approaches tackle this problem by implicit feature interaction and fusion between visual and linguistic modalities in a one-stage manner. However, human tends to solve the referring problem in a progressive manner based on informative words in the expression, i.e., first roughly locating candidate entities and then distinguishing the target one. In this paper, we propose a Cross-Modal Progressive Comprehension (CMPC) scheme to effectively mimic human behaviors and implement it as a CMPC-I (Image) module and a CMPC-V (Video) module to improve referring image and video segmentation models. For image data, our CMPC-I module first employs entity and attribute words to perceive all the related entities that might be considered by the expression. Then, the relational words are adopted to highlight the target entity as well as suppress other irrelevant ones by spatial graph reasoning. For video data, our CMPC-V module further exploits action words based on CMPC-I to highlight the correct entity matched with the action cues by temporal graph reasoning. In addition to the CMPC, we also introduce a simple yet effective Text-Guided Feature Exchange (TGFE) module to integrate the reasoned multimodal features corresponding to different levels in the visual backbone under the guidance of textual information. In this way, multi-level features can communicate with each other and be mutually refined based on the textual context. Combining CMPC-I or CMPC-V with TGFE can form our image or video version referring segmentation frameworks and our frameworks achieve new state-of-the-art performances on four referring image segmentation benchmarks and three referring video segmentation benchmarks respectively.
Collaborative Spatial-Temporal Modeling for Language-Queried Video Actor Segmentation
May 14, 2021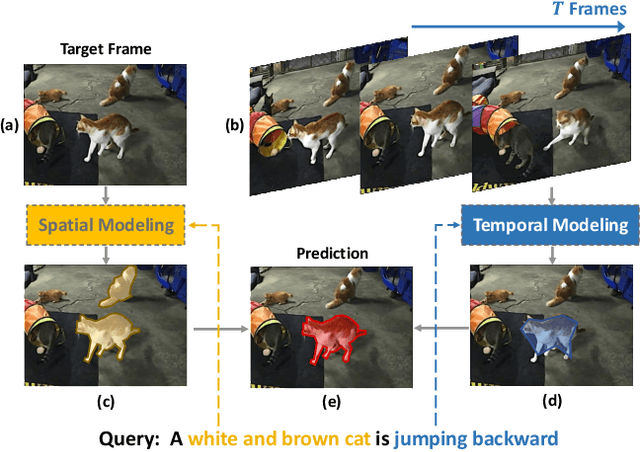
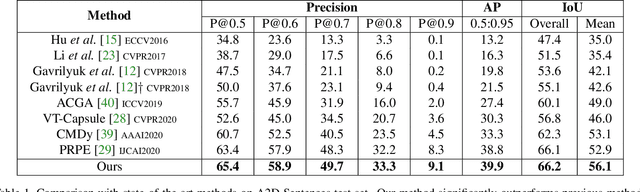
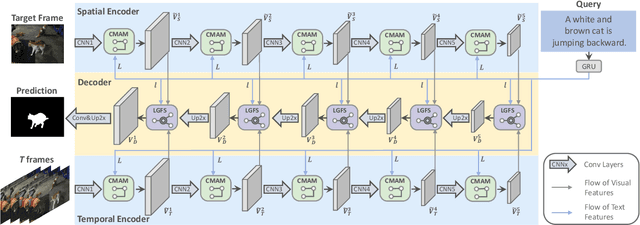
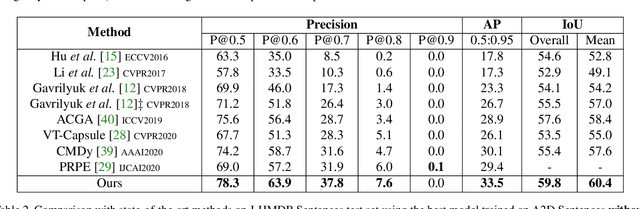
Language-queried video actor segmentation aims to predict the pixel-level mask of the actor which performs the actions described by a natural language query in the target frames. Existing methods adopt 3D CNNs over the video clip as a general encoder to extract a mixed spatio-temporal feature for the target frame. Though 3D convolutions are amenable to recognizing which actor is performing the queried actions, it also inevitably introduces misaligned spatial information from adjacent frames, which confuses features of the target frame and yields inaccurate segmentation. Therefore, we propose a collaborative spatial-temporal encoder-decoder framework which contains a 3D temporal encoder over the video clip to recognize the queried actions, and a 2D spatial encoder over the target frame to accurately segment the queried actors. In the decoder, a Language-Guided Feature Selection (LGFS) module is proposed to flexibly integrate spatial and temporal features from the two encoders. We also propose a Cross-Modal Adaptive Modulation (CMAM) module to dynamically recombine spatial- and temporal-relevant linguistic features for multimodal feature interaction in each stage of the two encoders. Our method achieves new state-of-the-art performance on two popular benchmarks with less computational overhead than previous approaches.