 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZehao Huang
SparseFusion: Efficient Sparse Multi-Modal Fusion Framework for Long-Range 3D Perception
Mar 15, 2024
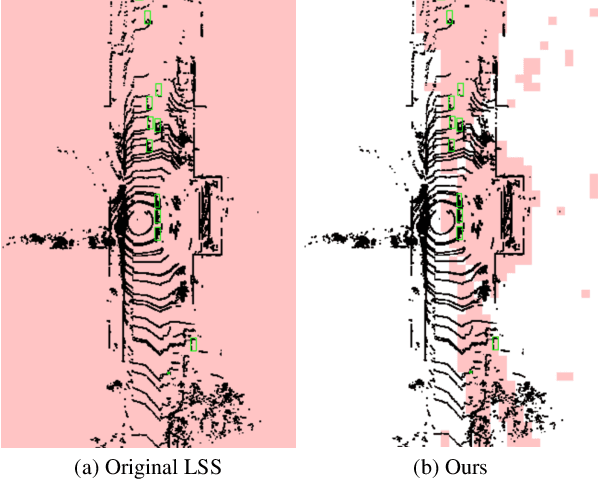

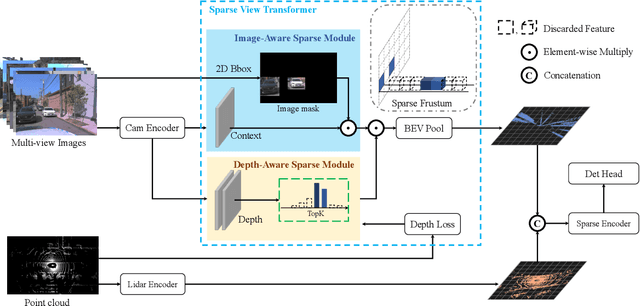
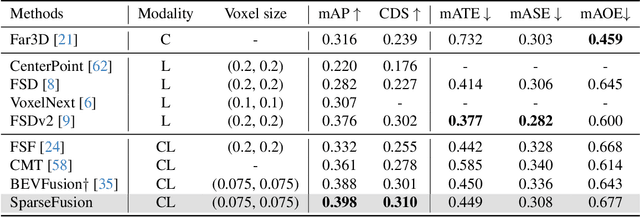
Multi-modal 3D object detection has exhibited significant progress in recent years. However, most existing methods can hardly scale to long-range scenarios due to their reliance on dense 3D features, which substantially escalate computational demands and memory usage. In this paper, we introduce SparseFusion, a novel multi-modal fusion framework fully built upon sparse 3D features to facilitate efficient long-range perception. The core of our method is the Sparse View Transformer module, which selectively lifts regions of interest in 2D image space into the unified 3D space. The proposed module introduces sparsity from both semantic and geometric aspects which only fill grids that foreground objects potentially reside in. Comprehensive experiments have verified the efficiency and effectiveness of our framework in long-range 3D perception. Remarkably, on the long-range Argoverse2 dataset, SparseFusion reduces memory footprint and accelerates the inference by about two times compared to dense detectors. It also achieves state-of-the-art performance with mAP of 41.2% and CDS of 32.1%. The versatility of SparseFusion is also validated in the temporal object detection task and 3D lane detection task. Codes will be released upon acceptance.
TSTTC: A Large-Scale Dataset for Time-to-Contact Estimation in Driving Scenarios
Sep 06, 2023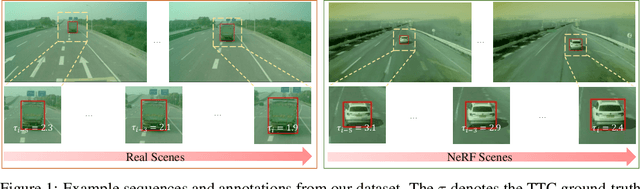
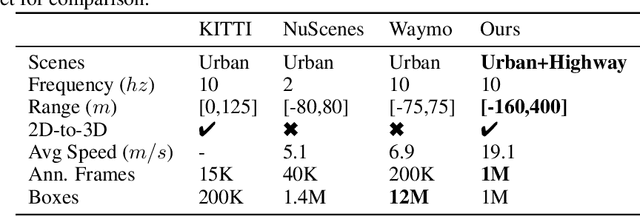
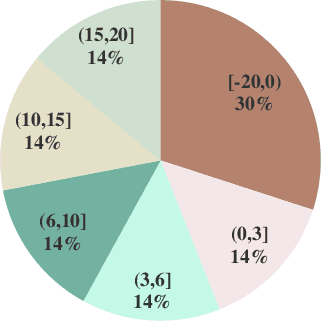
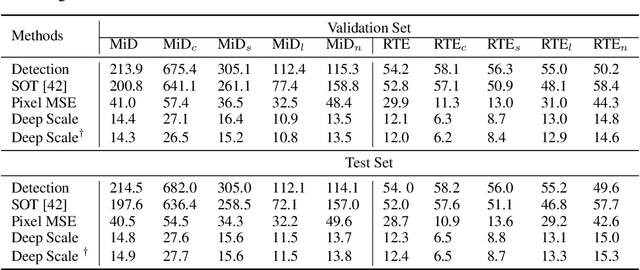
Time-to-Contact (TTC) estimation is a critical task for assessing collision risk and is widely used in various driver assistance and autonomous driving systems. The past few decades have witnessed development of related theories and algorithms. The prevalent learning-based methods call for a large-scale TTC dataset in real-world scenarios. In this work, we present a large-scale object oriented TTC dataset in the driving scene for promoting the TTC estimation by a monocular camera. To collect valuable samples and make data with different TTC values relatively balanced, we go through thousands of hours of driving data and select over 200K sequences with a preset data distribution. To augment the quantity of small TTC cases, we also generate clips using the latest Neural rendering methods. Additionally, we provide several simple yet effective TTC estimation baselines and evaluate them extensively on the proposed dataset to demonstrate their effectiveness. The proposed dataset is publicly available at https://open-dataset.tusen.ai/TSTTC.
Tracking Objects with 3D Representation from Videos
Jun 08, 2023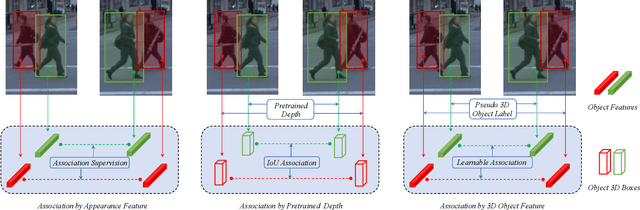

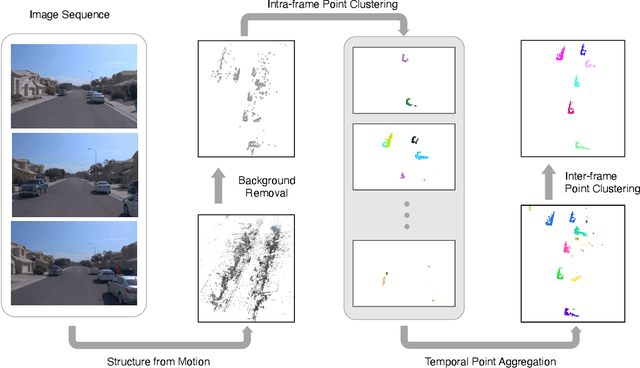
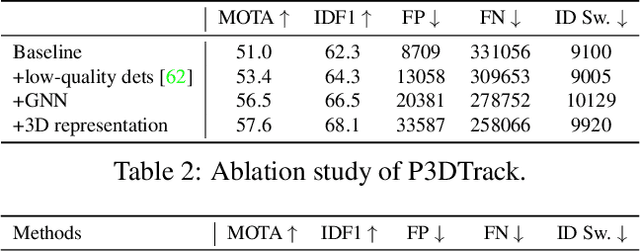
Data association is a knotty problem for 2D Multiple Object Tracking due to the object occlusion. However, in 3D space, data association is not so hard. Only with a 3D Kalman Filter, the online object tracker can associate the detections from LiDAR. In this paper, we rethink the data association in 2D MOT and utilize the 3D object representation to separate each object in the feature space. Unlike the existing depth-based MOT methods, the 3D object representation can be jointly learned with the object association module. Besides, the object's 3D representation is learned from the video and supervised by the 2D tracking labels without additional manual annotations from LiDAR or pretrained depth estimator. With 3D object representation learning from Pseudo 3D object labels in monocular videos, we propose a new 2D MOT paradigm, called P3DTrack. Extensive experiments show the effectiveness of our method. We achieve new state-of-the-art performance on the large-scale Waymo Open Dataset.
Fully Sparse Fusion for 3D Object Detection
Apr 25, 2023
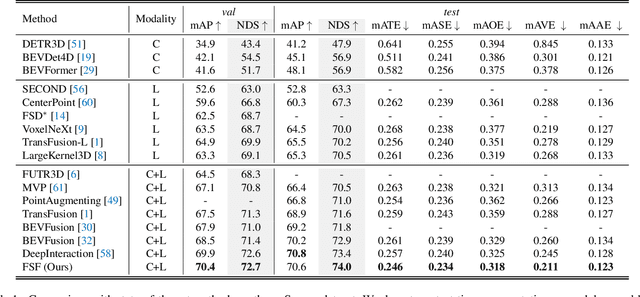
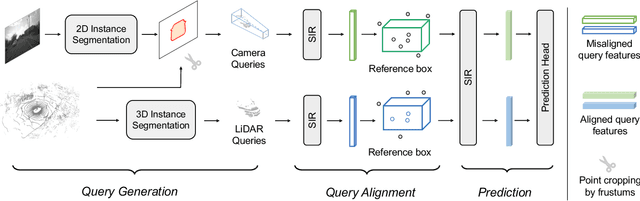
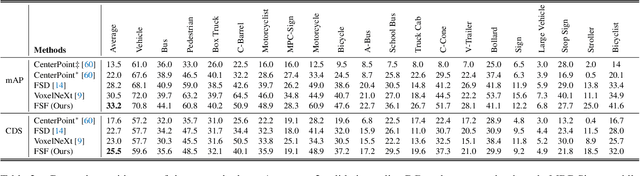
Currently prevalent multimodal 3D detection methods are built upon LiDAR-based detectors that usually use dense Bird's-Eye-View (BEV) feature maps. However, the cost of such BEV feature maps is quadratic to the detection range, making it not suitable for long-range detection. Fully sparse architecture is gaining attention as they are highly efficient in long-range perception. In this paper, we study how to effectively leverage image modality in the emerging fully sparse architecture. Particularly, utilizing instance queries, our framework integrates the well-studied 2D instance segmentation into the LiDAR side, which is parallel to the 3D instance segmentation part in the fully sparse detector. This design achieves a uniform query-based fusion framework in both the 2D and 3D sides while maintaining the fully sparse characteristic. Extensive experiments showcase state-of-the-art results on the widely used nuScenes dataset and the long-range Argoverse 2 dataset. Notably, the inference speed of the proposed method under the long-range LiDAR perception setting is 2.7 $\times$ faster than that of other state-of-the-art multimodal 3D detection methods. Code will be released at \url{https://github.com/BraveGroup/FullySparseFusion}.
Learnable Graph Matching: A Practical Paradigm for Data Association
Mar 27, 2023
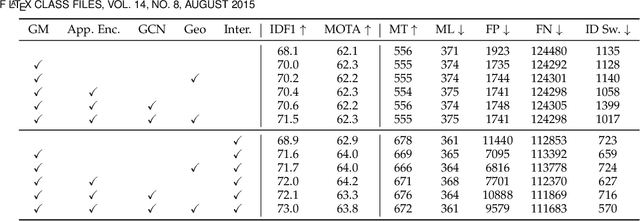
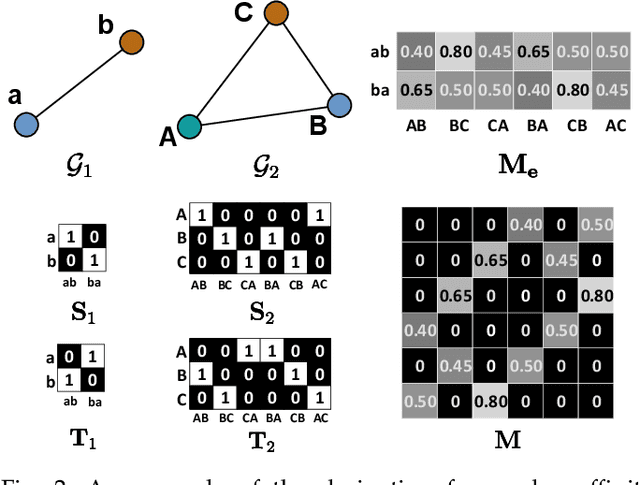

Data association is at the core of many computer vision tasks, e.g., multiple object tracking, image matching, and point cloud registration. Existing methods usually solve the data association problem by network flow optimization, bipartite matching, or end-to-end learning directly. Despite their popularity, we find some defects of the current solutions: they mostly ignore the intra-view context information; besides, they either train deep association models in an end-to-end way and hardly utilize the advantage of optimization-based assignment methods, or only use an off-the-shelf neural network to extract features. In this paper, we propose a general learnable graph matching method to address these issues. Especially, we model the intra-view relationships as an undirected graph. Then data association turns into a general graph matching problem between graphs. Furthermore, to make optimization end-to-end differentiable, we relax the original graph matching problem into continuous quadratic programming and then incorporate training into a deep graph neural network with KKT conditions and implicit function theorem. In MOT task, our method achieves state-of-the-art performance on several MOT datasets. For image matching, our method outperforms state-of-the-art methods with half training data and iterations on a popular indoor dataset, ScanNet. Code will be available at https://github.com/jiaweihe1996/GMTracker.
Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability
Jan 06, 2023
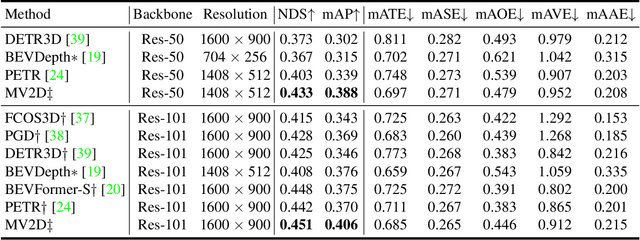
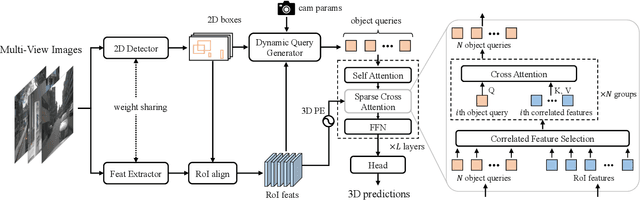
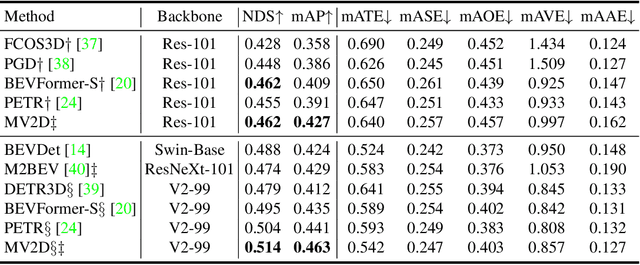
3D object detection from multi-view images has drawn much attention over the past few years. Existing methods mainly establish 3D representations from multi-view images and adopt a dense detection head for object detection, or employ object queries distributed in 3D space to localize objects. In this paper, we design Multi-View 2D Objects guided 3D Object Detector (MV2D), which can be equipped with any 2D object detector to promote multi-view 3D object detection. Since 2D detections can provide valuable priors for object existence, MV2D exploits 2D detector to generate object queries conditioned on the rich image semantics. These dynamically generated queries enable MV2D to detect objects in larger 3D space without increased computational costs and shows a strong capability of localizing 3D objects. For the generated queries, we design a sparse cross attention module to force them to focus on the features of specific objects, which reduces the computational cost and suppresses interference from noises. The evaluation results on the nuScenes dataset demonstrate that dynamic object queries and sparse feature aggregation do not harm 3D detection capability. MV2D also exhibits a state-of-the-art performance among existing methods. We hope MV2D can serve as a new baseline for future research.
Anchor3DLane: Learning to Regress 3D Anchors for Monocular 3D Lane Detection
Jan 06, 2023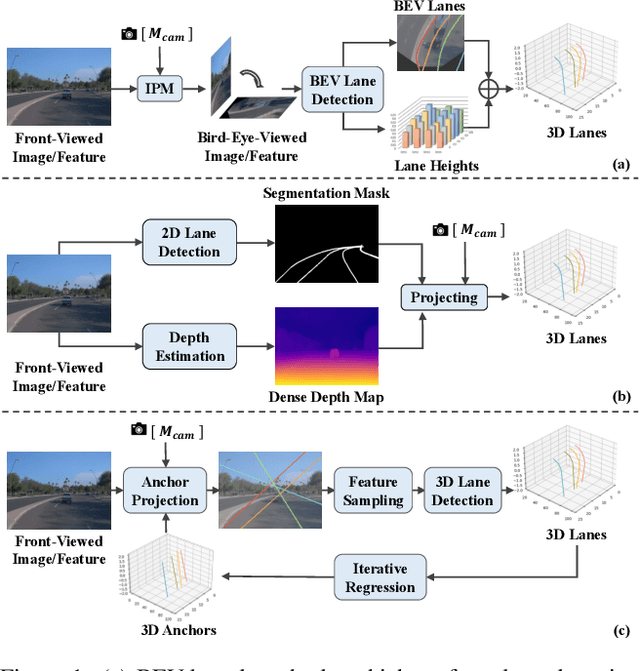
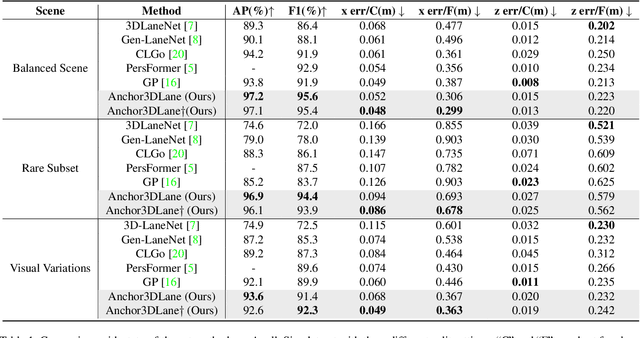
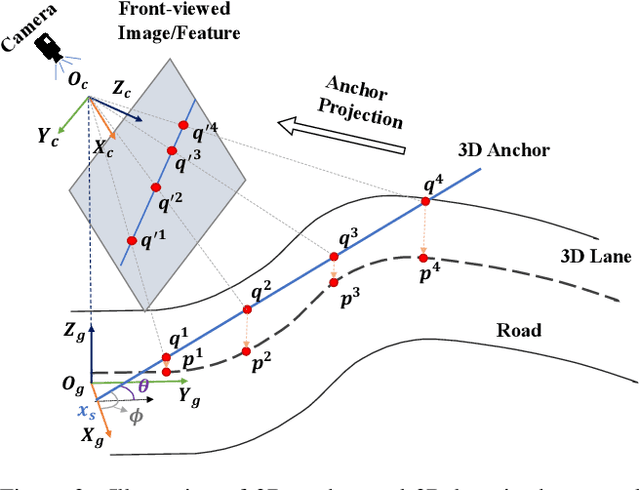
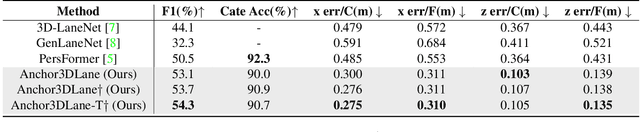
Monocular 3D lane detection is a challenging task due to its lack of depth information. A popular solution to 3D lane detection is to first transform the front-viewed (FV) images or features into the bird-eye-view (BEV) space with inverse perspective mapping (IPM) and detect lanes from BEV features. However, the reliance of IPM on flat ground assumption and loss of context information makes it inaccurate to restore 3D information from BEV representations. An attempt has been made to get rid of BEV and predict 3D lanes from FV representations directly, while it still underperforms other BEV-based methods given its lack of structured representation for 3D lanes. In this paper, we define 3D lane anchors in the 3D space and propose a BEV-free method named Anchor3DLane to predict 3D lanes directly from FV representations. 3D lane anchors are projected to the FV features to extract their features which contain both good structural and context information to make accurate predictions. We further extend Anchor3DLane to the multi-frame setting to incorporate temporal information for performance improvement. In addition, we also develop a global optimization method that makes use of the equal-width property between lanes to reduce the lateral error of predictions. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane outperforms previous BEV-based methods and achieves state-of-the-art performances.
PredNAS: A Universal and Sample Efficient Neural Architecture Search Framework
Oct 26, 2022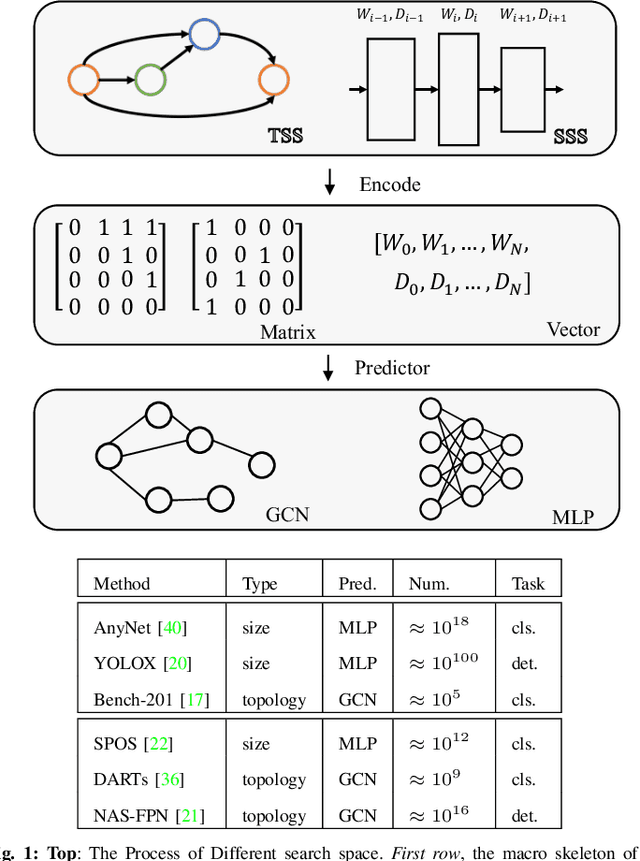
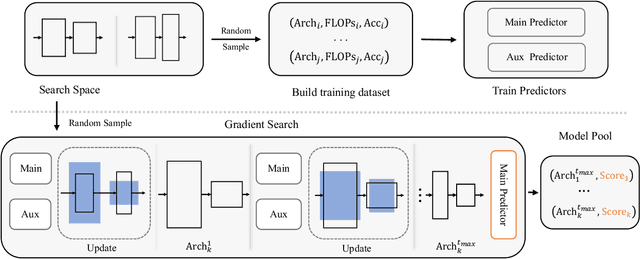
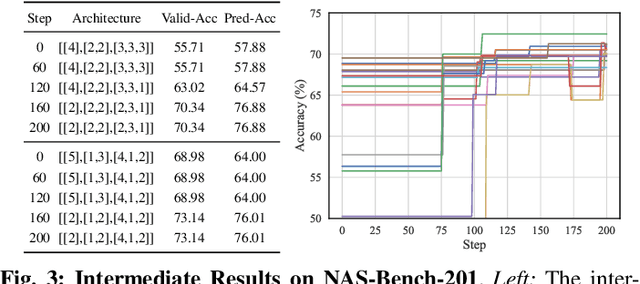
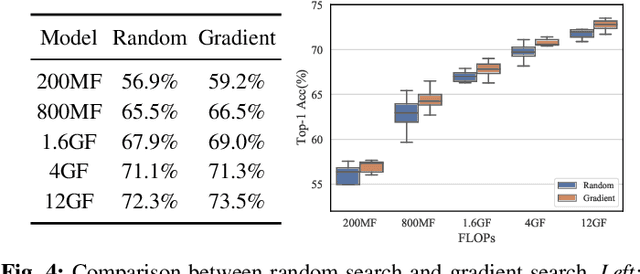
In this paper, we present a general and effective framework for Neural Architecture Search (NAS), named PredNAS. The motivation is that given a differentiable performance estimation function, we can directly optimize the architecture towards higher performance by simple gradient ascent. Specifically, we adopt a neural predictor as the performance predictor. Surprisingly, PredNAS can achieve state-of-the-art performances on NAS benchmarks with only a few training samples (less than 100). To validate the universality of our method, we also apply our method on large-scale tasks and compare our method with RegNet on ImageNet and YOLOX on MSCOCO. The results demonstrate that our PredNAS can explore novel architectures with competitive performances under specific computational complexity constraints.
Direct Differentiable Augmentation Search
Apr 09, 2021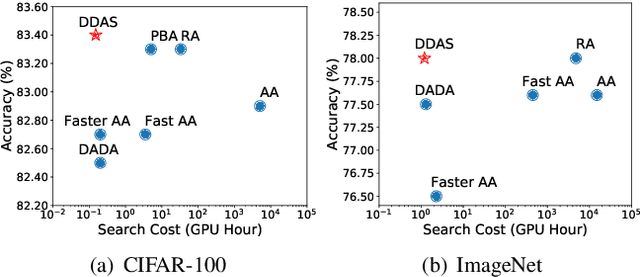

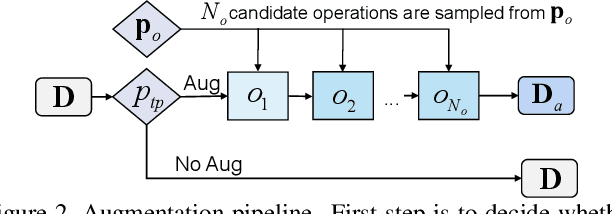
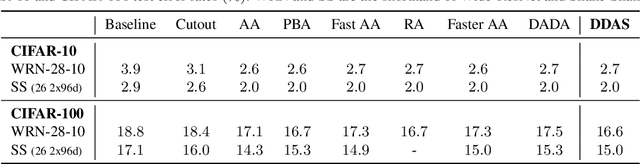
Data augmentation has been an indispensable tool to improve the performance of deep neural networks, however the augmentation can hardly transfer among different tasks and datasets. Consequently, a recent trend is to adopt AutoML technique to learn proper augmentation policy without extensive hand-crafted tuning. In this paper, we propose an efficient differentiable search algorithm called Direct Differentiable Augmentation Search (DDAS). It exploits meta-learning with one-step gradient update and continuous relaxation to the expected training loss for efficient search. Our DDAS can achieve efficient augmentation search without relying on approximations such as Gumbel Softmax or second order gradient approximation. To further reduce the adverse effect of improper augmentations, we organize the search space into a two level hierarchy, in which we first decide whether to apply augmentation, and then determine the specific augmentation policy. On standard image classification benchmarks, our DDAS achieves state-of-the-art performance and efficiency tradeoff while reducing the search cost dramatically, e.g. 0.15 GPU hours for CIFAR-10. In addition, we also use DDAS to search augmentation for object detection task and achieve comparable performance with AutoAugment, while being 1000x faster.
Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking
Mar 30, 2021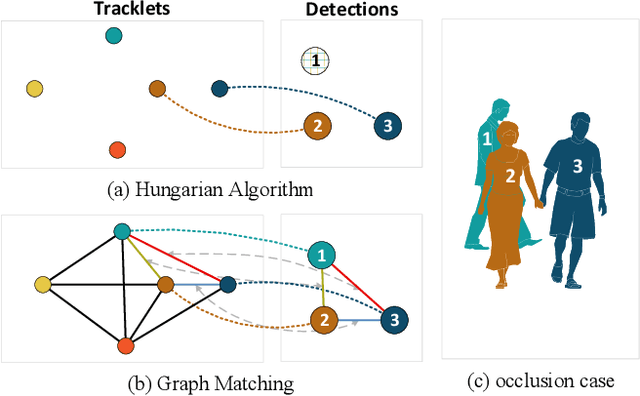
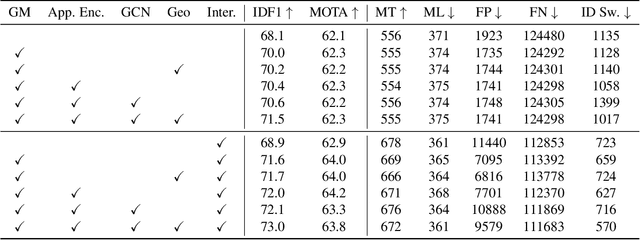


Data association across frames is at the core of Multiple Object Tracking (MOT) task. This problem is usually solved by a traditional graph-based optimization or directly learned via deep learning. Despite their popularity, we find some points worth studying in current paradigm: 1) Existing methods mostly ignore the context information among tracklets and intra-frame detections, which makes the tracker hard to survive in challenging cases like severe occlusion. 2) The end-to-end association methods solely rely on the data fitting power of deep neural networks, while they hardly utilize the advantage of optimization-based assignment methods. 3) The graph-based optimization methods mostly utilize a separate neural network to extract features, which brings the inconsistency between training and inference. Therefore, in this paper we propose a novel learnable graph matching method to address these issues. Briefly speaking, we model the relationships between tracklets and the intra-frame detections as a general undirected graph. Then the association problem turns into a general graph matching between tracklet graph and detection graph. Furthermore, to make the optimization end-to-end differentiable, we relax the original graph matching into continuous quadratic programming and then incorporate the training of it into a deep graph network with the help of the implicit function theorem. Lastly, our method GMTracker, achieves state-of-the-art performance on several standard MOT datasets. Our code will be available at https://github.com/jiaweihe1996/GMTracker .