 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuheng Shi
TSTTC: A Large-Scale Dataset for Time-to-Contact Estimation in Driving Scenarios
Sep 06, 2023
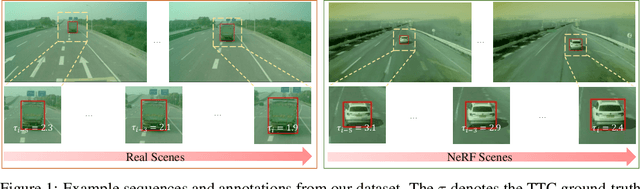
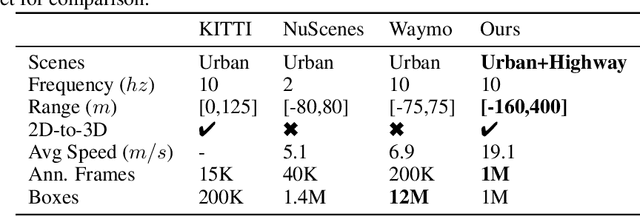
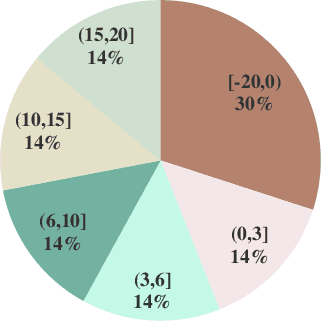
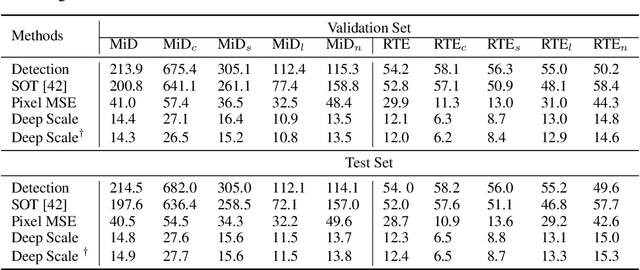
Time-to-Contact (TTC) estimation is a critical task for assessing collision risk and is widely used in various driver assistance and autonomous driving systems. The past few decades have witnessed development of related theories and algorithms. The prevalent learning-based methods call for a large-scale TTC dataset in real-world scenarios. In this work, we present a large-scale object oriented TTC dataset in the driving scene for promoting the TTC estimation by a monocular camera. To collect valuable samples and make data with different TTC values relatively balanced, we go through thousands of hours of driving data and select over 200K sequences with a preset data distribution. To augment the quantity of small TTC cases, we also generate clips using the latest Neural rendering methods. Additionally, we provide several simple yet effective TTC estimation baselines and evaluate them extensively on the proposed dataset to demonstrate their effectiveness. The proposed dataset is publicly available at https://open-dataset.tusen.ai/TSTTC.
Knowledge Prompting for Few-shot Action Recognition
Nov 22, 2022
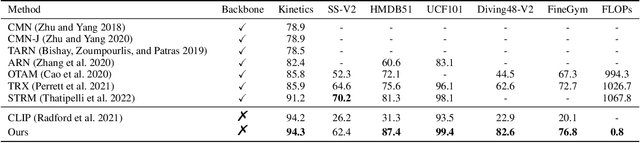
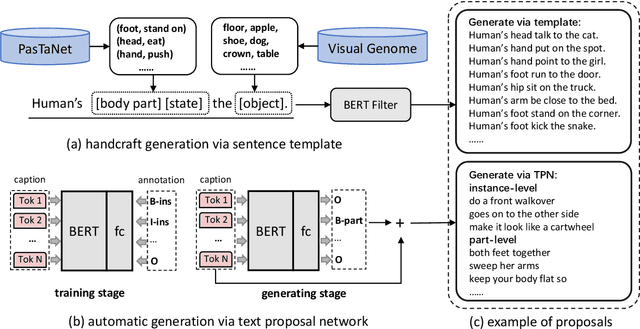
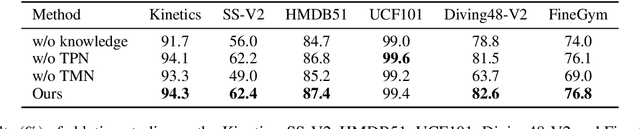
Few-shot action recognition in videos is challenging for its lack of supervision and difficulty in generalizing to unseen actions. To address this task, we propose a simple yet effective method, called knowledge prompting, which leverages commonsense knowledge of actions from external resources to prompt a powerful pre-trained vision-language model for few-shot classification. We first collect large-scale language descriptions of actions, defined as text proposals, to build an action knowledge base. The collection of text proposals is done by filling in handcraft sentence templates with external action-related corpus or by extracting action-related phrases from captions of Web instruction videos.Then we feed these text proposals into the pre-trained vision-language model along with video frames to generate matching scores of the proposals to each frame, and the scores can be treated as action semantics with strong generalization. Finally, we design a lightweight temporal modeling network to capture the temporal evolution of action semantics for classification.Extensive experiments on six benchmark datasets demonstrate that our method generally achieves the state-of-the-art performance while reducing the training overhead to 0.001 of existing methods.
YOLOV: Making Still Image Object Detectors Great at Video Object Detection
Aug 20, 2022
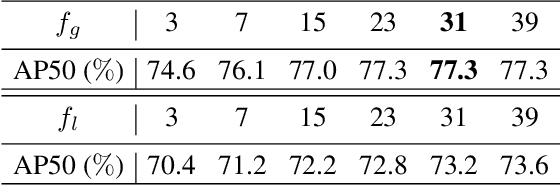
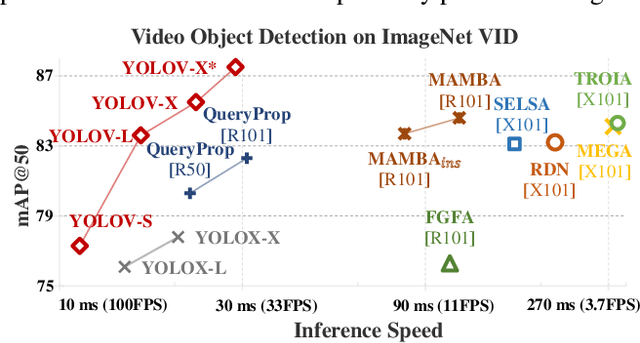

Video object detection (VID) is challenging because of the high variation of object appearance as well as the diverse deterioration in some frames. On the positive side, the detection in a certain frame of a video, compared with in a still image, can draw support from other frames. Hence, how to aggregate features across different frames is pivotal to the VID problem. Most of existing aggregation algorithms are customized for two-stage detectors. But, the detectors in this category are usually computationally expensive due to the two-stage nature. This work proposes a simple yet effective strategy to address the above concerns, which spends marginal overheads with significant gains in accuracy. Concretely, different from the traditional two-stage pipeline, we advocate putting the region-level selection after the one-stage detection to avoid processing massive low-quality candidates. Besides, a novel module is constructed to evaluate the relationship between a target frame and its reference ones, and guide the aggregation. Extensive experiments and ablation studies are conducted to verify the efficacy of our design, and reveal its superiority over other state-of-the-art VID approaches in both effectiveness and efficiency. Our YOLOX-based model can achieve promising performance (e.g., 87.5\% AP50 at over 30 FPS on the ImageNet VID dataset on a single 2080Ti GPU), making it attractive for large-scale or real-time applications. The implementation is simple, the demo code and models have been made available at https://github.com/YuHengsss/YOLOV .