 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifei Zhang
FlashFace: Human Image Personalization with High-fidelity Identity Preservation
Mar 25, 2024
This work presents FlashFace, a practical tool with which users can easily personalize their own photos on the fly by providing one or a few reference face images and a text prompt. Our approach is distinguishable from existing human photo customization methods by higher-fidelity identity preservation and better instruction following, benefiting from two subtle designs. First, we encode the face identity into a series of feature maps instead of one image token as in prior arts, allowing the model to retain more details of the reference faces (e.g., scars, tattoos, and face shape ). Second, we introduce a disentangled integration strategy to balance the text and image guidance during the text-to-image generation process, alleviating the conflict between the reference faces and the text prompts (e.g., personalizing an adult into a "child" or an "elder"). Extensive experimental results demonstrate the effectiveness of our method on various applications, including human image personalization, face swapping under language prompts, making virtual characters into real people, etc. Project Page: https://jshilong.github.io/flashface-page.
DreamLIP: Language-Image Pre-training with Long Captions
Mar 25, 2024Language-image pre-training largely relies on how precisely and thoroughly a text describes its paired image. In practice, however, the contents of an image can be so rich that well describing them requires lengthy captions (e.g., with 10 sentences), which are usually missing in existing datasets. Consequently, there are currently no clear evidences on whether and how language-image pre-training could benefit from long captions. To figure this out, we first re-caption 30M images with detailed descriptions using a pre-trained Multi-modality Large Language Model (MLLM), and then study the usage of the resulting captions under a contrastive learning framework. We observe that, each sentence within a long caption is very likely to describe the image partially (e.g., an object). Motivated by this, we propose to dynamically sample sub-captions from the text label to construct multiple positive pairs, and introduce a grouping loss to match the embeddings of each sub-caption with its corresponding local image patches in a self-supervised manner. Experimental results on a wide rage of downstream tasks demonstrate the consistent superiority of our method, termed DreamLIP, over previous alternatives, highlighting its fine-grained representational capacity. It is noteworthy that, on the tasks of image-text retrieval and semantic segmentation, our model trained with 30M image-text pairs achieves on par or even better performance than CLIP trained with 400M pairs. Project page is available at https://zyf0619sjtu.github.io/dream-lip.
Is Mamba Effective for Time Series Forecasting?
Mar 17, 2024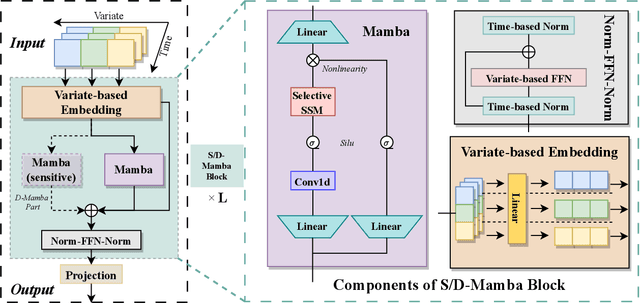
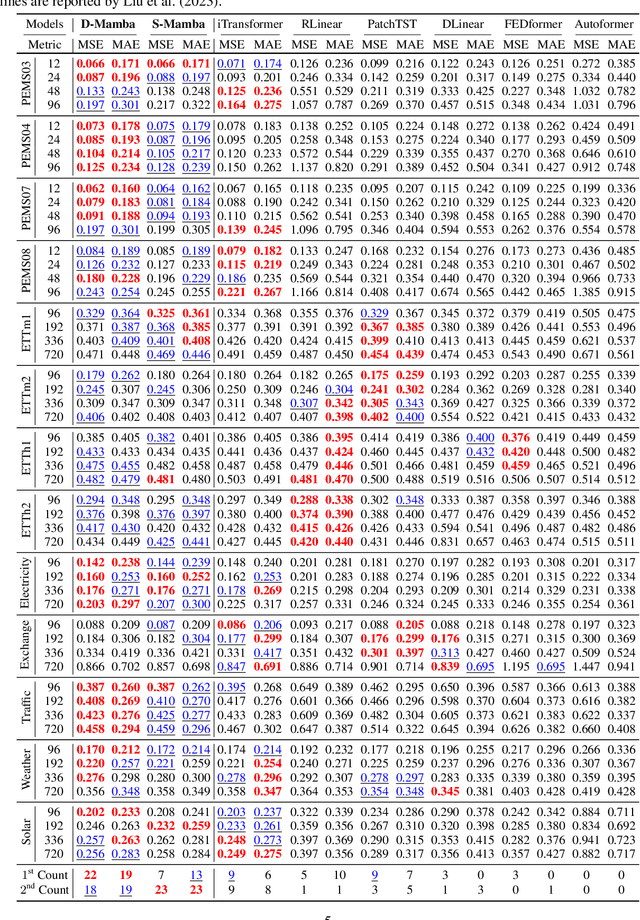
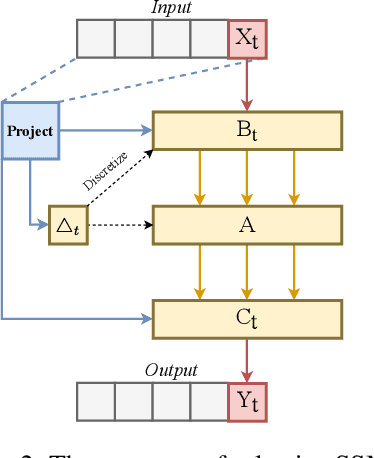
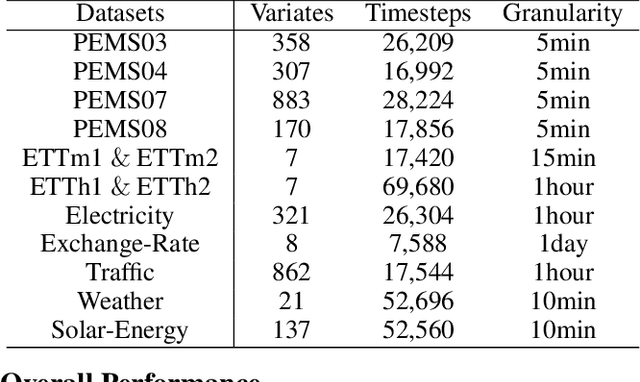
In the realm of time series forecasting (TSF), the Transformer has consistently demonstrated robust performance due to its ability to focus on the global context and effectively capture long-range dependencies within time, as well as discern correlations between multiple variables. However, due to the inefficiencies of the Transformer model and questions surrounding its ability to capture dependencies, ongoing efforts to refine the Transformer architecture persist. Recently, state space models (SSMs), e.g. Mamba, have gained traction due to their ability to capture complex dependencies in sequences, similar to the Transformer, while maintaining near-linear complexity. In text and image tasks, Mamba-based models can improve performance and cost savings, creating a win-win situation. This has piqued our interest in exploring SSM's potential in TSF tasks. In this paper, we introduce two straightforward SSM-based models for TSF, S-Mamba and D-Mamba, both employing the Mamba Block to extract variate correlations. Remarkably, S-Mamba and D-Mamba achieve superior performance while saving GPU memory and training time. Furthermore, we conduct extensive experiments to delve deeper into the potential of Mamba compared to the Transformer in the TSF, aiming to explore a new research direction for this field. Our code is available at https://github.com/wzhwzhwzh0921/S-D-Mamba.
DUE: Dynamic Uncertainty-Aware Explanation Supervision via 3D Imputation
Mar 16, 2024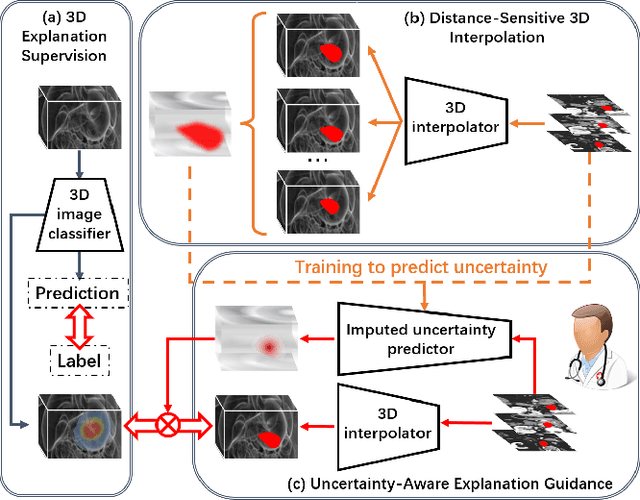
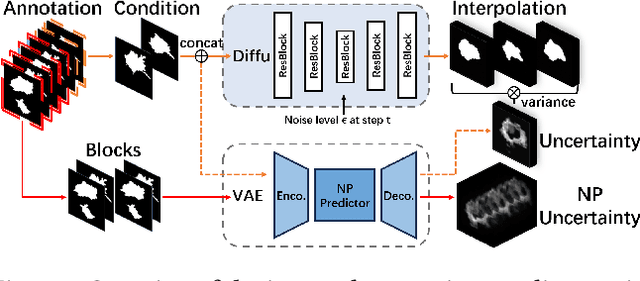
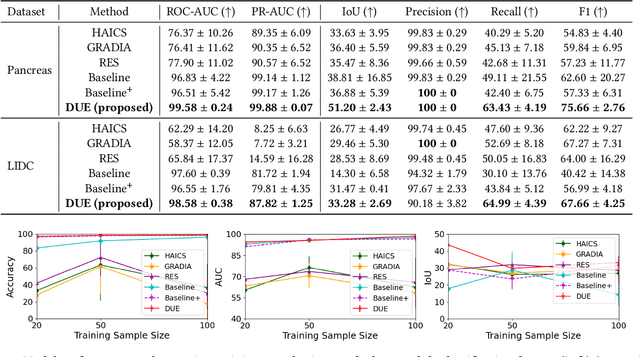
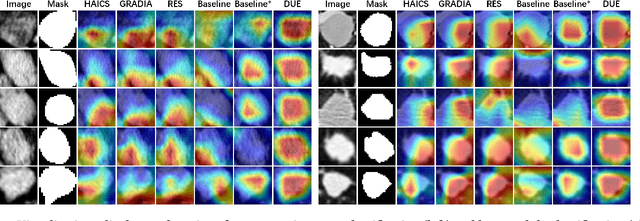
Explanation supervision aims to enhance deep learning models by integrating additional signals to guide the generation of model explanations, showcasing notable improvements in both the predictability and explainability of the model. However, the application of explanation supervision to higher-dimensional data, such as 3D medical images, remains an under-explored domain. Challenges associated with supervising visual explanations in the presence of an additional dimension include: 1) spatial correlation changed, 2) lack of direct 3D annotations, and 3) uncertainty varies across different parts of the explanation. To address these challenges, we propose a Dynamic Uncertainty-aware Explanation supervision (DUE) framework for 3D explanation supervision that ensures uncertainty-aware explanation guidance when dealing with sparsely annotated 3D data with diffusion-based 3D interpolation. Our proposed framework is validated through comprehensive experiments on diverse real-world medical imaging datasets. The results demonstrate the effectiveness of our framework in enhancing the predictability and explainability of deep learning models in the context of medical imaging diagnosis applications.
FastMAC: Stochastic Spectral Sampling of Correspondence Graph
Mar 13, 2024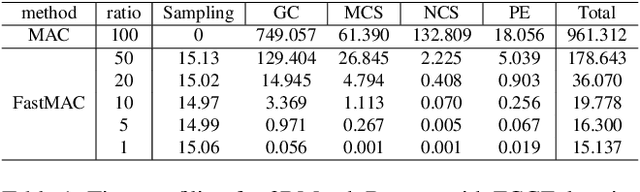
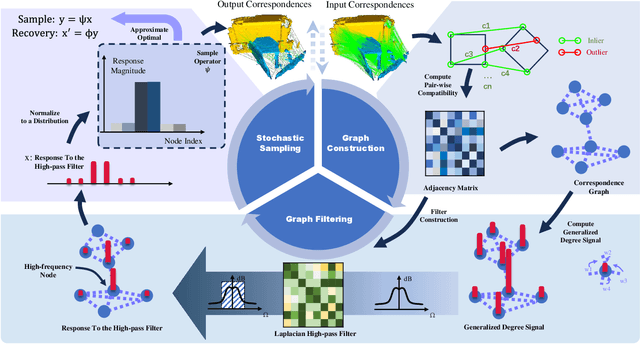
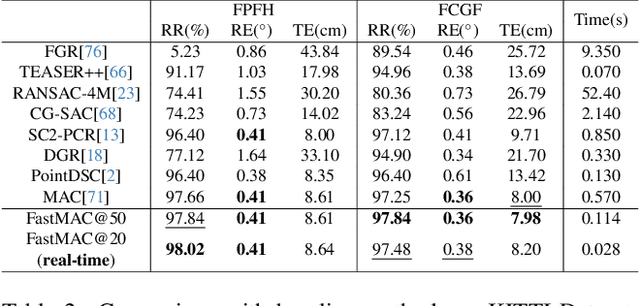
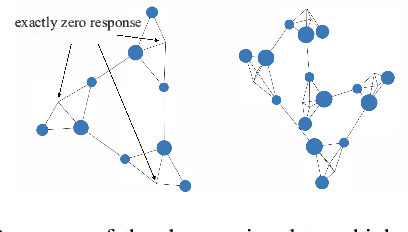
3D correspondence, i.e., a pair of 3D points, is a fundamental concept in computer vision. A set of 3D correspondences, when equipped with compatibility edges, forms a correspondence graph. This graph is a critical component in several state-of-the-art 3D point cloud registration approaches, e.g., the one based on maximal cliques (MAC). However, its properties have not been well understood. So we present the first study that introduces graph signal processing into the domain of correspondence graph. We exploit the generalized degree signal on correspondence graph and pursue sampling strategies that preserve high-frequency components of this signal. To address time-consuming singular value decomposition in deterministic sampling, we resort to a stochastic approximate sampling strategy. As such, the core of our method is the stochastic spectral sampling of correspondence graph. As an application, we build a complete 3D registration algorithm termed as FastMAC, that reaches real-time speed while leading to little to none performance drop. Through extensive experiments, we validate that FastMAC works for both indoor and outdoor benchmarks. For example, FastMAC can accelerate MAC by 80 times while maintaining high registration success rate on KITTI. Codes are publicly available at https://github.com/Forrest-110/FastMAC.
ELAD: Explanation-Guided Large Language Models Active Distillation
Feb 20, 2024The deployment and application of Large Language Models (LLMs) is hindered by their memory inefficiency, computational demands, and the high costs of API inferences. Traditional distillation methods, which transfer the capabilities of LLMs to smaller models, often fail to determine whether the knowledge has been sufficiently transferred, potentially resulting in high costs or incomplete distillation. In this paper, we propose an Explanation-Guided LLMs Active Distillation (ELAD) framework that employs an active learning strategy to optimize the balance between annotation costs and model performance. To improve efficient sample selection, we introduce an explanation-guided sample selection method that identifies samples challenging its reasoning by exploiting uncertainties in explanation steps. Additionally, we present a customized LLM-annotated explanation revision technique where the teacher model detects and corrects flaws in the student model's reasoning. Our experiments across various reasoning datasets demonstrate that our framework significantly enhances the efficiency of LLM knowledge distillation.
Distilling Large Language Models for Text-Attributed Graph Learning
Feb 19, 2024Text-Attributed Graphs (TAGs) are graphs of connected textual documents. Graph models can efficiently learn TAGs, but their training heavily relies on human-annotated labels, which are scarce or even unavailable in many applications. Large language models (LLMs) have recently demonstrated remarkable capabilities in few-shot and zero-shot TAG learning, but they suffer from scalability, cost, and privacy issues. Therefore, in this work, we focus on synergizing LLMs and graph models with their complementary strengths by distilling the power of LLMs to a local graph model on TAG learning. To address the inherent gaps between LLMs (generative models for texts) and graph models (discriminative models for graphs), we propose first to let LLMs teach an interpreter with rich textual rationale and then let a student model mimic the interpreter's reasoning without LLMs' textual rationale. Extensive experiments validate the efficacy of our proposed framework.
HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy
Jan 26, 2024Full-parameter fine-tuning has become the go-to choice for adapting language models (LMs) to downstream tasks due to its excellent performance. As LMs grow in size, fine-tuning the full parameters of LMs requires a prohibitively large amount of GPU memory. Existing approaches utilize zeroth-order optimizer to conserve GPU memory, which can potentially compromise the performance of LMs as non-zero order optimizers tend to converge more readily on most downstream tasks. In this paper, we propose a novel optimizer-independent end-to-end hierarchical fine-tuning strategy, HiFT, which only updates a subset of parameters at each training step. HiFT can significantly reduce the amount of gradients and optimizer state parameters residing in GPU memory at the same time, thereby reducing GPU memory usage. Our results demonstrate that: (1) HiFT achieves comparable performance to parameter-efficient fine-tuning and standard full parameter fine-tuning. (2) HiFT supports various optimizers including AdamW, AdaGrad, SGD, etc. (3) HiFT can save more than 60\% GPU memory compared with standard full-parameter fine-tuning for 7B model. (4) HiFT enables full-parameter fine-tuning of a 7B model on single 48G A6000 with a precision of 32 using the AdamW optimizer, without using any memory saving techniques.
StickerConv: Generating Multimodal Empathetic Responses from Scratch
Jan 20, 2024Stickers, while widely recognized for enhancing empathetic communication in online interactions, remain underexplored in current empathetic dialogue research. In this paper, we introduce the Agent for StickerConv (Agent4SC), which uses collaborative agent interactions to realistically simulate human behavior with sticker usage, thereby enhancing multimodal empathetic communication. Building on this foundation, we develop a multimodal empathetic dialogue dataset, StickerConv, which includes 12.9K dialogue sessions, 5.8K unique stickers, and 2K diverse conversational scenarios, specifically designs to augment the generation of empathetic responses in a multimodal context. To leverage the richness of this dataset, we propose PErceive and Generate Stickers (PEGS), a multimodal empathetic response generation model, complemented by a comprehensive set of empathy evaluation metrics based on LLM. Our experiments demonstrate PEGS's effectiveness in generating contextually relevant and emotionally resonant multimodal empathetic responses, contributing to the advancement of more nuanced and engaging empathetic dialogue systems. Our project page is available at https://neu-datamining.github.io/StickerConv .
AI Empowered Channel Semantic Acquisition for 6G Integrated Sensing and Communication Networks
Jan 17, 2024Motivated by the need for increased spectral efficiency and the proliferation of intelligent applications, the sixth-generation (6G) mobile network is anticipated to integrate the dual-functions of communication and sensing (C&S). Although the millimeter wave (mmWave) communication and mmWave radar share similar multiple-input multiple-output (MIMO) architecture for integration, the full potential of dual-function synergy remains to be exploited. In this paper, we commence by overviewing state-of-the-art schemes from the aspects of waveform design and signal processing. Nevertheless, these approaches face the dilemma of mutual compromise between C&S performance. To this end, we reveal and exploit the synergy between C&S. In the proposed framework, we introduce a two-stage frame structure and resort artificial intelligence (AI) to achieve the synergistic gain by designing a joint C&S channel semantic extraction and reconstruction network (JCASCasterNet). With just a cost-effective and energy-efficient single sensing antenna, the proposed scheme achieves enhanced overall performance while requiring only limited pilot and feedback signaling overhead. In the end, we outline the challenges that lie ahead in the future development of integrated sensing and communication networks, along with promising directions for further research.