 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Ling
MIM-Reasoner: Learning with Theoretical Guarantees for Multiplex Influence Maximization
Mar 10, 2024
Multiplex influence maximization (MIM) asks us to identify a set of seed users such as to maximize the expected number of influenced users in a multiplex network. MIM has been one of central research topics, especially in nowadays social networking landscape where users participate in multiple online social networks (OSNs) and their influences can propagate among several OSNs simultaneously. Although there exist a couple combinatorial algorithms to MIM, learning-based solutions have been desired due to its generalization ability to heterogeneous networks and their diversified propagation characteristics. In this paper, we introduce MIM-Reasoner, coupling reinforcement learning with probabilistic graphical model, which effectively captures the complex propagation process within and between layers of a given multiplex network, thereby tackling the most challenging problem in MIM. We establish a theoretical guarantee for MIM-Reasoner as well as conduct extensive analyses on both synthetic and real-world datasets to validate our MIM-Reasoner's performance.
Gradient-Free Adaptive Global Pruning for Pre-trained Language Models
Feb 28, 2024The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose Adaptive Global Pruning (AdaGP), a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. AdaGP's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
ELAD: Explanation-Guided Large Language Models Active Distillation
Feb 20, 2024The deployment and application of Large Language Models (LLMs) is hindered by their memory inefficiency, computational demands, and the high costs of API inferences. Traditional distillation methods, which transfer the capabilities of LLMs to smaller models, often fail to determine whether the knowledge has been sufficiently transferred, potentially resulting in high costs or incomplete distillation. In this paper, we propose an Explanation-Guided LLMs Active Distillation (ELAD) framework that employs an active learning strategy to optimize the balance between annotation costs and model performance. To improve efficient sample selection, we introduce an explanation-guided sample selection method that identifies samples challenging its reasoning by exploiting uncertainties in explanation steps. Additionally, we present a customized LLM-annotated explanation revision technique where the teacher model detects and corrects flaws in the student model's reasoning. Our experiments across various reasoning datasets demonstrate that our framework significantly enhances the efficiency of LLM knowledge distillation.
A Condensed Transition Graph Framework for Zero-shot Link Prediction with Large Language Models
Feb 16, 2024Zero-shot link prediction (ZSLP) on knowledge graphs aims at automatically identifying relations between given entities. Existing methods primarily employ auxiliary information to predict tail entity given head entity and its relation, yet face challenges due to the occasional unavailability of such detailed information and the inherent simplicity of predicting tail entities based on semantic similarities. Even though Large Language Models (LLMs) offer a promising solution to predict unobserved relations between the head and tail entity in a zero-shot manner, their performance is still restricted due to the inability to leverage all the (exponentially many) paths' information between two entities, which are critical in collectively indicating their relation types. To address this, in this work, we introduce a Condensed Transition Graph Framework for Zero-Shot Link Prediction (CTLP), which encodes all the paths' information in linear time complexity to predict unseen relations between entities, attaining both efficiency and information preservation. Specifically, we design a condensed transition graph encoder with theoretical guarantees on its coverage, expressiveness, and efficiency. It is learned by a transition graph contrastive learning strategy. Subsequently, we design a soft instruction tuning to learn and map the all-path embedding to the input of LLMs. Experimental results show that our proposed CTLP method achieves state-of-the-art performance on three standard ZSLP datasets
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
Gene-associated Disease Discovery Powered by Large Language Models
Jan 16, 2024The intricate relationship between genetic variation and human diseases has been a focal point of medical research, evidenced by the identification of risk genes regarding specific diseases. The advent of advanced genome sequencing techniques has significantly improved the efficiency and cost-effectiveness of detecting these genetic markers, playing a crucial role in disease diagnosis and forming the basis for clinical decision-making and early risk assessment. To overcome the limitations of existing databases that record disease-gene associations from existing literature, which often lack real-time updates, we propose a novel framework employing Large Language Models (LLMs) for the discovery of diseases associated with specific genes. This framework aims to automate the labor-intensive process of sifting through medical literature for evidence linking genetic variations to diseases, thereby enhancing the efficiency of disease identification. Our approach involves using LLMs to conduct literature searches, summarize relevant findings, and pinpoint diseases related to specific genes. This paper details the development and application of our LLM-powered framework, demonstrating its potential in streamlining the complex process of literature retrieval and summarization to identify diseases associated with specific genetic variations.
Beyond Efficiency: A Systematic Survey of Resource-Efficient Large Language Models
Jan 04, 2024The burgeoning field of Large Language Models (LLMs), exemplified by sophisticated models like OpenAI's ChatGPT, represents a significant advancement in artificial intelligence. These models, however, bring forth substantial challenges in the high consumption of computational, memory, energy, and financial resources, especially in environments with limited resource capabilities. This survey aims to systematically address these challenges by reviewing a broad spectrum of techniques designed to enhance the resource efficiency of LLMs. We categorize methods based on their optimization focus: computational, memory, energy, financial, and network resources and their applicability across various stages of an LLM's lifecycle, including architecture design, pretraining, finetuning, and system design. Additionally, the survey introduces a nuanced categorization of resource efficiency techniques by their specific resource types, which uncovers the intricate relationships and mappings between various resources and corresponding optimization techniques. A standardized set of evaluation metrics and datasets is also presented to facilitate consistent and fair comparisons across different models and techniques. By offering a comprehensive overview of the current sota and identifying open research avenues, this survey serves as a foundational reference for researchers and practitioners, aiding them in developing more sustainable and efficient LLMs in a rapidly evolving landscape.
Open-ended Commonsense Reasoning with Unrestricted Answer Scope
Oct 27, 2023Open-ended Commonsense Reasoning is defined as solving a commonsense question without providing 1) a short list of answer candidates and 2) a pre-defined answer scope. Conventional ways of formulating the commonsense question into a question-answering form or utilizing external knowledge to learn retrieval-based methods are less applicable in the open-ended setting due to an inherent challenge. Without pre-defining an answer scope or a few candidates, open-ended commonsense reasoning entails predicting answers by searching over an extremely large searching space. Moreover, most questions require implicit multi-hop reasoning, which presents even more challenges to our problem. In this work, we leverage pre-trained language models to iteratively retrieve reasoning paths on the external knowledge base, which does not require task-specific supervision. The reasoning paths can help to identify the most precise answer to the commonsense question. We conduct experiments on two commonsense benchmark datasets. Compared to other approaches, our proposed method achieves better performance both quantitatively and qualitatively.
Improving Open Information Extraction with Large Language Models: A Study on Demonstration Uncertainty
Sep 07, 2023
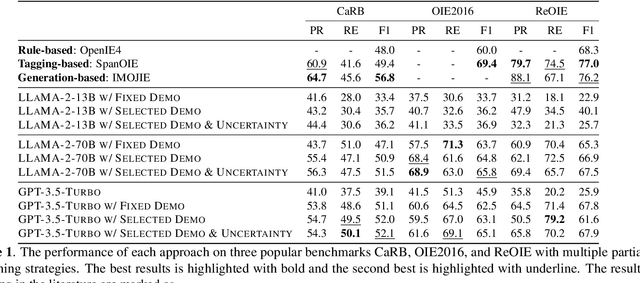

Open Information Extraction (OIE) task aims at extracting structured facts from unstructured text, typically in the form of (subject, relation, object) triples. Despite the potential of large language models (LLMs) like ChatGPT as a general task solver, they lag behind state-of-the-art (supervised) methods in OIE tasks due to two key issues. First, LLMs struggle to distinguish irrelevant context from relevant relations and generate structured output due to the restrictions on fine-tuning the model. Second, LLMs generates responses autoregressively based on probability, which makes the predicted relations lack confidence. In this paper, we assess the capabilities of LLMs in improving the OIE task. Particularly, we propose various in-context learning strategies to enhance LLM's instruction-following ability and a demonstration uncertainty quantification module to enhance the confidence of the generated relations. Our experiments on three OIE benchmark datasets show that our approach holds its own against established supervised methods, both quantitatively and qualitatively.
Helper Recommendation with seniority control in Online Health Community
Sep 06, 2023



Online health communities (OHCs) are forums where patients with similar conditions communicate their experiences and provide moral support. Social support in OHCs plays a crucial role in easing and rehabilitating patients. However, many time-sensitive questions from patients often remain unanswered due to the multitude of threads and the random nature of patient visits in OHCs. To address this issue, it is imperative to propose a recommender system that assists solution seekers in finding appropriate problem helpers. Nevertheless, developing a recommendation algorithm to enhance social support in OHCs remains an under-explored area. Traditional recommender systems cannot be directly adapted due to the following obstacles. First, unlike user-item links in traditional recommender systems, it is hard to model the social support behind helper-seeker links in OHCs since they are formed based on various heterogeneous reasons. Second, it is difficult to distinguish the impact of historical activities in characterizing patients. Third, it is significantly challenging to ensure that the recommended helpers possess sufficient expertise to assist the seekers. To tackle the aforementioned challenges, we develop a Monotonically regularIzed diseNTangled Variational Autoencoders (MINT) model to strengthen social support in OHCs.