 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingchen Li
BiomedRAG: A Retrieval Augmented Large Language Model for Biomedicine
May 02, 2024
Large Language Models (LLMs) have swiftly emerged as vital resources for different applications in the biomedical and healthcare domains; however, these models encounter issues such as generating inaccurate information or hallucinations. Retrieval-augmented generation provided a solution for these models to update knowledge and enhance their performance. In contrast to previous retrieval-augmented LMs, which utilize specialized cross-attention mechanisms to help LLM encode retrieved text, BiomedRAG adopts a simpler approach by directly inputting the retrieved chunk-based documents into the LLM. This straightforward design is easily applicable to existing retrieval and language models, effectively bypassing noise information in retrieved documents, particularly in noise-intensive tasks. Moreover, we demonstrate the potential for utilizing the LLM to supervise the retrieval model in the biomedical domain, enabling it to retrieve the document that assists the LM in improving its predictions. Our experiments reveal that with the tuned scorer,\textsc{ BiomedRAG} attains superior performance across 5 biomedical NLP tasks, encompassing information extraction (triple extraction, relation extraction), text classification, link prediction, and question-answering, leveraging over 9 datasets. For instance, in the triple extraction task, \textsc{BiomedRAG} outperforms other triple extraction systems with micro-F1 scores of 81.42 and 88.83 on GIT and ChemProt corpora, respectively.
Simple, Efficient and Scalable Structure-aware Adapter Boosts Protein Language Models
Apr 23, 2024Fine-tuning Pre-trained protein language models (PLMs) has emerged as a prominent strategy for enhancing downstream prediction tasks, often outperforming traditional supervised learning approaches. As a widely applied powerful technique in natural language processing, employing Parameter-Efficient Fine-Tuning techniques could potentially enhance the performance of PLMs. However, the direct transfer to life science tasks is non-trivial due to the different training strategies and data forms. To address this gap, we introduce SES-Adapter, a simple, efficient, and scalable adapter method for enhancing the representation learning of PLMs. SES-Adapter incorporates PLM embeddings with structural sequence embeddings to create structure-aware representations. We show that the proposed method is compatible with different PLM architectures and across diverse tasks. Extensive evaluations are conducted on 2 types of folding structures with notable quality differences, 9 state-of-the-art baselines, and 9 benchmark datasets across distinct downstream tasks. Results show that compared to vanilla PLMs, SES-Adapter improves downstream task performance by a maximum of 11% and an average of 3%, with significantly accelerated training speed by a maximum of 1034% and an average of 362%, the convergence rate is also improved by approximately 2 times. Moreover, positive optimization is observed even with low-quality predicted structures. The source code for SES-Adapter is available at https://github.com/tyang816/SES-Adapter.
A Condensed Transition Graph Framework for Zero-shot Link Prediction with Large Language Models
Feb 16, 2024Zero-shot link prediction (ZSLP) on knowledge graphs aims at automatically identifying relations between given entities. Existing methods primarily employ auxiliary information to predict tail entity given head entity and its relation, yet face challenges due to the occasional unavailability of such detailed information and the inherent simplicity of predicting tail entities based on semantic similarities. Even though Large Language Models (LLMs) offer a promising solution to predict unobserved relations between the head and tail entity in a zero-shot manner, their performance is still restricted due to the inability to leverage all the (exponentially many) paths' information between two entities, which are critical in collectively indicating their relation types. To address this, in this work, we introduce a Condensed Transition Graph Framework for Zero-Shot Link Prediction (CTLP), which encodes all the paths' information in linear time complexity to predict unseen relations between entities, attaining both efficiency and information preservation. Specifically, we design a condensed transition graph encoder with theoretical guarantees on its coverage, expressiveness, and efficiency. It is learned by a transition graph contrastive learning strategy. Subsequently, we design a soft instruction tuning to learn and map the all-path embedding to the input of LLMs. Experimental results show that our proposed CTLP method achieves state-of-the-art performance on three standard ZSLP datasets
Class-attribute Priors: Adapting Optimization to Heterogeneity and Fairness Objective
Jan 25, 2024Modern classification problems exhibit heterogeneities across individual classes: Each class may have unique attributes, such as sample size, label quality, or predictability (easy vs difficult), and variable importance at test-time. Without care, these heterogeneities impede the learning process, most notably, when optimizing fairness objectives. Confirming this, under a gaussian mixture setting, we show that the optimal SVM classifier for balanced accuracy needs to be adaptive to the class attributes. This motivates us to propose CAP: An effective and general method that generates a class-specific learning strategy (e.g. hyperparameter) based on the attributes of that class. This way, optimization process better adapts to heterogeneities. CAP leads to substantial improvements over the naive approach of assigning separate hyperparameters to each class. We instantiate CAP for loss function design and post-hoc logit adjustment, with emphasis on label-imbalanced problems. We show that CAP is competitive with prior art and its flexibility unlocks clear benefits for fairness objectives beyond balanced accuracy. Finally, we evaluate CAP on problems with label noise as well as weighted test objectives to showcase how CAP can jointly adapt to different heterogeneities.
PeTailor: Improving Large Language Model by Tailored Chunk Scorer in Biomedical Triple Extraction
Oct 27, 2023The automatic extraction of biomedical entities and their interaction from unstructured data remains a challenging task due to the limited availability of expert-labeled standard datasets. In this paper, we introduce PETAI-LOR, a retrieval-based language framework that is augmented by tailored chunk scorer. Unlike previous retrieval-augmented language models (LM) that retrieve relevant documents by calculating the similarity between the input sentence and the candidate document set, PETAILOR segments the sentence into chunks and retrieves the relevant chunk from our pre-computed chunk-based relational key-value memory. Moreover, in order to comprehend the specific requirements of the LM, PETAI-LOR adapt the tailored chunk scorer to the LM. We also introduce GM-CIHT, an expert annotated biomedical triple extraction dataset with more relation types. This dataset is centered on the non-drug treatment and general biomedical domain. Additionally, we investigate the efficacy of triple extraction models trained on general domains when applied to the biomedical domain. Our experiments reveal that PETAI-LOR achieves state-of-the-art performance on GM-CIHT
PETA: Evaluating the Impact of Protein Transfer Learning with Sub-word Tokenization on Downstream Applications
Oct 26, 2023Large protein language models are adept at capturing the underlying evolutionary information in primary structures, offering significant practical value for protein engineering. Compared to natural language models, protein amino acid sequences have a smaller data volume and a limited combinatorial space. Choosing an appropriate vocabulary size to optimize the pre-trained model is a pivotal issue. Moreover, despite the wealth of benchmarks and studies in the natural language community, there remains a lack of a comprehensive benchmark for systematically evaluating protein language model quality. Given these challenges, PETA trained language models with 14 different vocabulary sizes under three tokenization methods. It conducted thousands of tests on 33 diverse downstream datasets to assess the models' transfer learning capabilities, incorporating two classification heads and three random seeds to mitigate potential biases. Extensive experiments indicate that vocabulary sizes between 50 and 200 optimize the model, whereas sizes exceeding 800 detrimentally affect the model's representational performance. Our code, model weights and datasets are available at https://github.com/ginnm/ProteinPretraining.
A Review of Reinforcement Learning for Natural Language Processing, and Applications in Healthcare
Oct 23, 2023Reinforcement learning (RL) has emerged as a powerful approach for tackling complex medical decision-making problems such as treatment planning, personalized medicine, and optimizing the scheduling of surgeries and appointments. It has gained significant attention in the field of Natural Language Processing (NLP) due to its ability to learn optimal strategies for tasks such as dialogue systems, machine translation, and question-answering. This paper presents a review of the RL techniques in NLP, highlighting key advancements, challenges, and applications in healthcare. The review begins by visualizing a roadmap of machine learning and its applications in healthcare. And then it explores the integration of RL with NLP tasks. We examined dialogue systems where RL enables the learning of conversational strategies, RL-based machine translation models, question-answering systems, text summarization, and information extraction. Additionally, ethical considerations and biases in RL-NLP systems are addressed.
Epi-Curriculum: Episodic Curriculum Learning for Low-Resource Domain Adaptation in Neural Machine Translation
Sep 06, 2023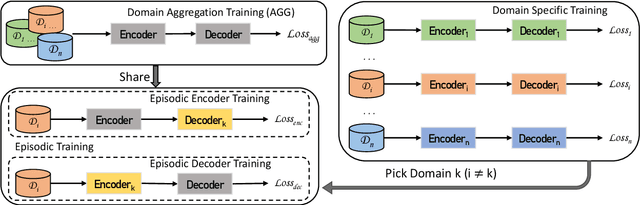
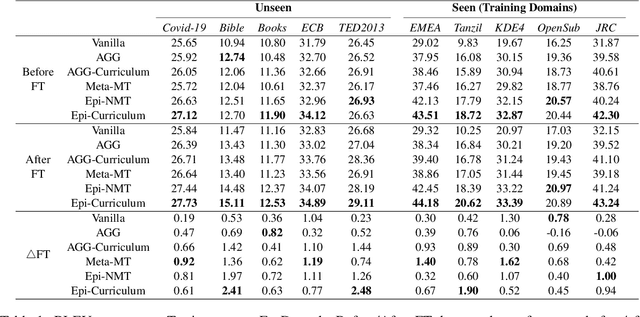
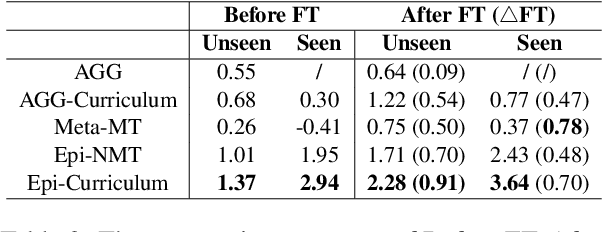
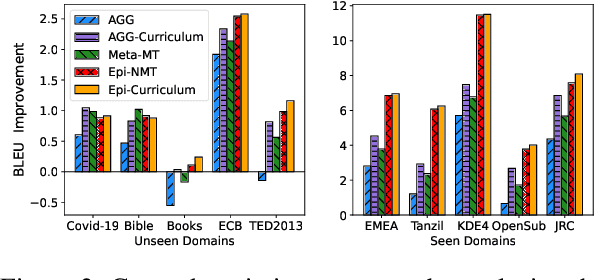
Neural Machine Translation (NMT) models have become successful, but their performance remains poor when translating on new domains with a limited number of data. In this paper, we present a novel approach Epi-Curriculum to address low-resource domain adaptation (DA), which contains a new episodic training framework along with denoised curriculum learning. Our episodic training framework enhances the model's robustness to domain shift by episodically exposing the encoder/decoder to an inexperienced decoder/encoder. The denoised curriculum learning filters the noised data and further improves the model's adaptability by gradually guiding the learning process from easy to more difficult tasks. Experiments on English-German and English-Romanian translation show that: (i) Epi-Curriculum improves both model's robustness and adaptability in seen and unseen domains; (ii) Our episodic training framework enhances the encoder and decoder's robustness to domain shift.
MedChatZH: a Better Medical Adviser Learns from Better Instructions
Sep 03, 2023Generative large language models (LLMs) have shown great success in various applications, including question-answering (QA) and dialogue systems. However, in specialized domains like traditional Chinese medical QA, these models may perform unsatisfactorily without fine-tuning on domain-specific datasets. To address this, we introduce MedChatZH, a dialogue model designed specifically for traditional Chinese medical QA. Our model is pre-trained on Chinese traditional medical books and fine-tuned with a carefully curated medical instruction dataset. It outperforms several solid baselines on a real-world medical dialogue dataset. We release our model, code, and dataset on https://github.com/tyang816/MedChatZH to facilitate further research in the domain of traditional Chinese medicine and LLMs.
FedYolo: Augmenting Federated Learning with Pretrained Transformers
Jul 10, 2023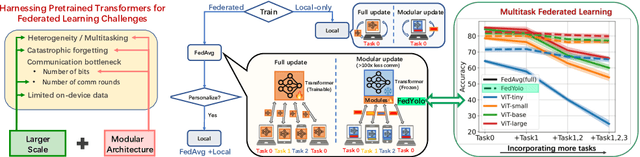
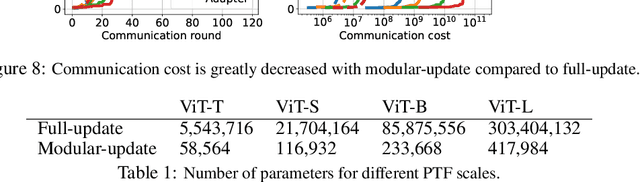
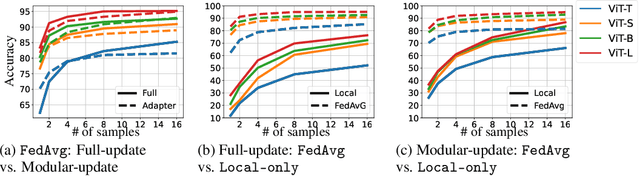
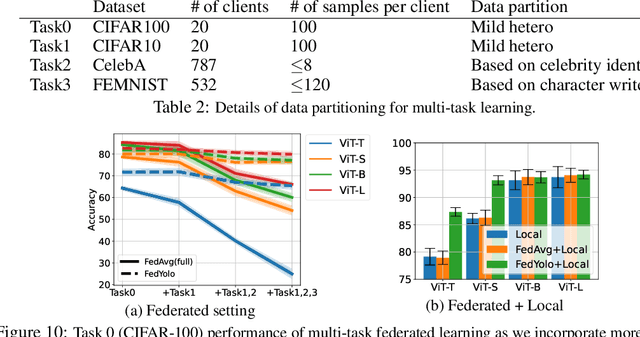
The growth and diversity of machine learning applications motivate a rethinking of learning with mobile and edge devices. How can we address diverse client goals and learn with scarce heterogeneous data? While federated learning aims to address these issues, it has challenges hindering a unified solution. Large transformer models have been shown to work across a variety of tasks achieving remarkable few-shot adaptation. This raises the question: Can clients use a single general-purpose model, rather than custom models for each task, while obeying device and network constraints? In this work, we investigate pretrained transformers (PTF) to achieve these on-device learning goals and thoroughly explore the roles of model size and modularity, where the latter refers to adaptation through modules such as prompts or adapters. Focusing on federated learning, we demonstrate that: (1) Larger scale shrinks the accuracy gaps between alternative approaches and improves heterogeneity robustness. Scale allows clients to run more local SGD epochs which can significantly reduce the number of communication rounds. At the extreme, clients can achieve respectable accuracy locally highlighting the potential of fully-local learning. (2) Modularity, by design, enables $>$100$\times$ less communication in bits. Surprisingly, it also boosts the generalization capability of local adaptation methods and the robustness of smaller PTFs. Finally, it enables clients to solve multiple unrelated tasks simultaneously using a single PTF, whereas full updates are prone to catastrophic forgetting. These insights on scale and modularity motivate a new federated learning approach we call "You Only Load Once" (FedYolo): The clients load a full PTF model once and all future updates are accomplished through communication-efficient modules with limited catastrophic-forgetting, where each task is assigned to its own module.