 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuisheng Fan
Simple, Efficient and Scalable Structure-aware Adapter Boosts Protein Language Models
Apr 23, 2024




Fine-tuning Pre-trained protein language models (PLMs) has emerged as a prominent strategy for enhancing downstream prediction tasks, often outperforming traditional supervised learning approaches. As a widely applied powerful technique in natural language processing, employing Parameter-Efficient Fine-Tuning techniques could potentially enhance the performance of PLMs. However, the direct transfer to life science tasks is non-trivial due to the different training strategies and data forms. To address this gap, we introduce SES-Adapter, a simple, efficient, and scalable adapter method for enhancing the representation learning of PLMs. SES-Adapter incorporates PLM embeddings with structural sequence embeddings to create structure-aware representations. We show that the proposed method is compatible with different PLM architectures and across diverse tasks. Extensive evaluations are conducted on 2 types of folding structures with notable quality differences, 9 state-of-the-art baselines, and 9 benchmark datasets across distinct downstream tasks. Results show that compared to vanilla PLMs, SES-Adapter improves downstream task performance by a maximum of 11% and an average of 3%, with significantly accelerated training speed by a maximum of 1034% and an average of 362%, the convergence rate is also improved by approximately 2 times. Moreover, positive optimization is observed even with low-quality predicted structures. The source code for SES-Adapter is available at https://github.com/tyang816/SES-Adapter.
PETA: Evaluating the Impact of Protein Transfer Learning with Sub-word Tokenization on Downstream Applications
Oct 26, 2023



Large protein language models are adept at capturing the underlying evolutionary information in primary structures, offering significant practical value for protein engineering. Compared to natural language models, protein amino acid sequences have a smaller data volume and a limited combinatorial space. Choosing an appropriate vocabulary size to optimize the pre-trained model is a pivotal issue. Moreover, despite the wealth of benchmarks and studies in the natural language community, there remains a lack of a comprehensive benchmark for systematically evaluating protein language model quality. Given these challenges, PETA trained language models with 14 different vocabulary sizes under three tokenization methods. It conducted thousands of tests on 33 diverse downstream datasets to assess the models' transfer learning capabilities, incorporating two classification heads and three random seeds to mitigate potential biases. Extensive experiments indicate that vocabulary sizes between 50 and 200 optimize the model, whereas sizes exceeding 800 detrimentally affect the model's representational performance. Our code, model weights and datasets are available at https://github.com/ginnm/ProteinPretraining.
MedChatZH: a Better Medical Adviser Learns from Better Instructions
Sep 03, 2023Generative large language models (LLMs) have shown great success in various applications, including question-answering (QA) and dialogue systems. However, in specialized domains like traditional Chinese medical QA, these models may perform unsatisfactorily without fine-tuning on domain-specific datasets. To address this, we introduce MedChatZH, a dialogue model designed specifically for traditional Chinese medical QA. Our model is pre-trained on Chinese traditional medical books and fine-tuned with a carefully curated medical instruction dataset. It outperforms several solid baselines on a real-world medical dialogue dataset. We release our model, code, and dataset on https://github.com/tyang816/MedChatZH to facilitate further research in the domain of traditional Chinese medicine and LLMs.
SESNet: sequence-structure feature-integrated deep learning method for data-efficient protein engineering
Dec 29, 2022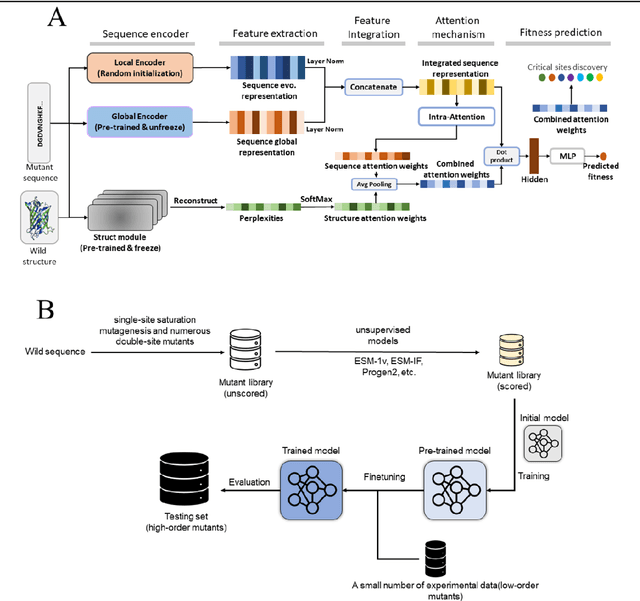
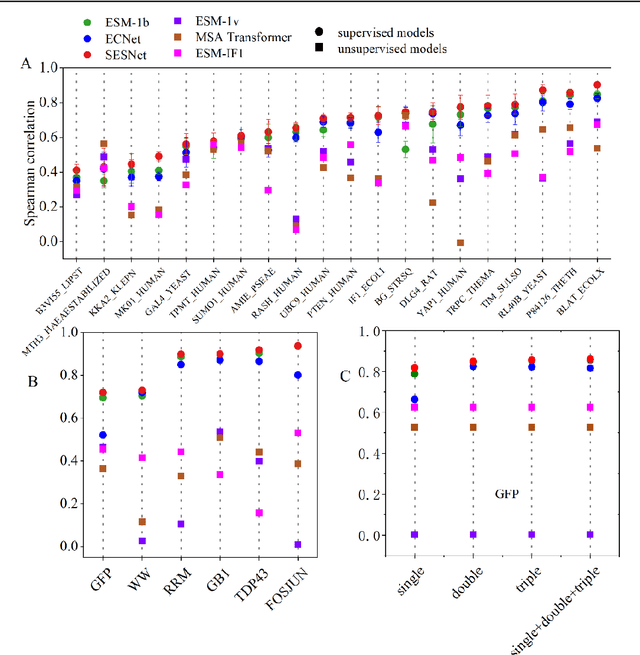
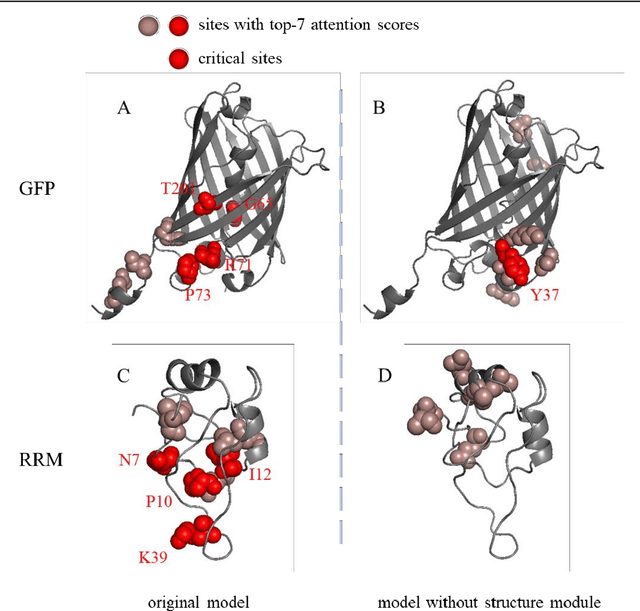
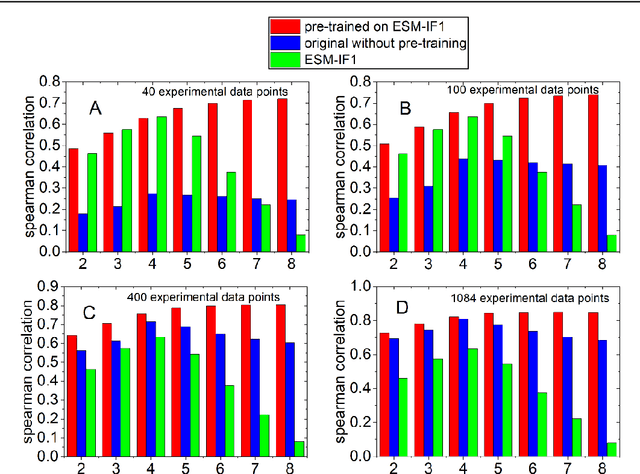
Deep learning has been widely used for protein engineering. However, it is limited by the lack of sufficient experimental data to train an accurate model for predicting the functional fitness of high-order mutants. Here, we develop SESNet, a supervised deep-learning model to predict the fitness for protein mutants by leveraging both sequence and structure information, and exploiting attention mechanism. Our model integrates local evolutionary context from homologous sequences, the global evolutionary context encoding rich semantic from the universal protein sequence space and the structure information accounting for the microenvironment around each residue in a protein. We show that SESNet outperforms state-of-the-art models for predicting the sequence-function relationship on 26 deep mutational scanning datasets. More importantly, we propose a data augmentation strategy by leveraging the data from unsupervised models to pre-train our model. After that, our model can achieve strikingly high accuracy in prediction of the fitness of protein mutants, especially for the higher order variants (> 4 mutation sites), when finetuned by using only a small number of experimental mutation data (<50). The strategy proposed is of great practical value as the required experimental effort, i.e., producing a few tens of experimental mutation data on a given protein, is generally affordable by an ordinary biochemical group and can be applied on almost any protein.