 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Cheng
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024
The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
InfuserKI: Enhancing Large Language Models with Knowledge Graphs via Infuser-Guided Knowledge Integration
Feb 18, 2024Though Large Language Models (LLMs) have shown remarkable open-generation capabilities across diverse domains, they struggle with knowledge-intensive tasks. To alleviate this issue, knowledge integration methods have been proposed to enhance LLMs with domain-specific knowledge graphs using external modules. However, they suffer from data inefficiency as they require both known and unknown knowledge for fine-tuning. Thus, we study a novel problem of integrating unknown knowledge into LLMs efficiently without unnecessary overlap of known knowledge. Injecting new knowledge poses the risk of forgetting previously acquired knowledge. To tackle this, we propose a novel Infuser-Guided Knowledge Integration (InfuserKI) framework that utilizes transformer internal states to determine whether to enhance the original LLM output with additional information, thereby effectively mitigating knowledge forgetting. Evaluations on the UMLS-2.5k and MetaQA domain knowledge graphs demonstrate that InfuserKI can effectively acquire new knowledge and outperform state-of-the-art baselines by 9% and 6%, respectively, in reducing knowledge forgetting.
Parametric Augmentation for Time Series Contrastive Learning
Feb 16, 2024Modern techniques like contrastive learning have been effectively used in many areas, including computer vision, natural language processing, and graph-structured data. Creating positive examples that assist the model in learning robust and discriminative representations is a crucial stage in contrastive learning approaches. Usually, preset human intuition directs the selection of relevant data augmentations. Due to patterns that are easily recognized by humans, this rule of thumb works well in the vision and language domains. However, it is impractical to visually inspect the temporal structures in time series. The diversity of time series augmentations at both the dataset and instance levels makes it difficult to choose meaningful augmentations on the fly. In this study, we address this gap by analyzing time series data augmentation using information theory and summarizing the most commonly adopted augmentations in a unified format. We then propose a contrastive learning framework with parametric augmentation, AutoTCL, which can be adaptively employed to support time series representation learning. The proposed approach is encoder-agnostic, allowing it to be seamlessly integrated with different backbone encoders. Experiments on univariate forecasting tasks demonstrate the highly competitive results of our method, with an average 6.5\% reduction in MSE and 4.7\% in MAE over the leading baselines. In classification tasks, AutoTCL achieves a $1.2\%$ increase in average accuracy.
Uncertainty Decomposition and Quantification for In-Context Learning of Large Language Models
Feb 15, 2024In-context learning has emerged as a groundbreaking ability of Large Language Models (LLMs) and revolutionized various fields by providing a few task-relevant demonstrations in the prompt. However, trustworthy issues with LLM's response, such as hallucination, have also been actively discussed. Existing works have been devoted to quantifying the uncertainty in LLM's response, but they often overlook the complex nature of LLMs and the uniqueness of in-context learning. In this work, we delve into the predictive uncertainty of LLMs associated with in-context learning, highlighting that such uncertainties may stem from both the provided demonstrations (aleatoric uncertainty) and ambiguities tied to the model's configurations (epistemic uncertainty). We propose a novel formulation and corresponding estimation method to quantify both types of uncertainties. The proposed method offers an unsupervised way to understand the prediction of in-context learning in a plug-and-play fashion. Extensive experiments are conducted to demonstrate the effectiveness of the decomposition. The code and data are available at: \url{https://github.com/lingchen0331/UQ_ICL}.
PAC Learnability under Explanation-Preserving Graph Perturbations
Feb 07, 2024Graphical models capture relations between entities in a wide range of applications including social networks, biology, and natural language processing, among others. Graph neural networks (GNN) are neural models that operate over graphs, enabling the model to leverage the complex relationships and dependencies in graph-structured data. A graph explanation is a subgraph which is an `almost sufficient' statistic of the input graph with respect to its classification label. Consequently, the classification label is invariant, with high probability, to perturbations of graph edges not belonging to its explanation subgraph. This work considers two methods for leveraging such perturbation invariances in the design and training of GNNs. First, explanation-assisted learning rules are considered. It is shown that the sample complexity of explanation-assisted learning can be arbitrarily smaller than explanation-agnostic learning. Next, explanation-assisted data augmentation is considered, where the training set is enlarged by artificially producing new training samples via perturbation of the non-explanation edges in the original training set. It is shown that such data augmentation methods may improve performance if the augmented data is in-distribution, however, it may also lead to worse sample complexity compared to explanation-agnostic learning rules if the augmented data is out-of-distribution. Extensive empirical evaluations are provided to verify the theoretical analysis.
Chatbot Meets Pipeline: Augment Large Language Model with Definite Finite Automaton
Feb 06, 2024This paper introduces the Definite Finite Automaton augmented large language model (DFA-LLM), a novel framework designed to enhance the capabilities of conversational agents using large language models (LLMs). Traditional LLMs face challenges in generating regulated and compliant responses in special scenarios with predetermined response guidelines, like emotional support and customer service. Our framework addresses these challenges by embedding a Definite Finite Automaton (DFA), learned from training dialogues, within the LLM. This structured approach enables the LLM to adhere to a deterministic response pathway, guided by the DFA. The advantages of DFA-LLM include an interpretable structure through human-readable DFA, context-aware retrieval for responses in conversations, and plug-and-play compatibility with existing LLMs. Extensive benchmarks validate DFA-LLM's effectiveness, indicating its potential as a valuable contribution to the conversational agent.
Prompt-based Domain Discrimination for Multi-source Time Series Domain Adaptation
Dec 19, 2023Time series domain adaptation stands as a pivotal and intricate challenge with diverse applications, including but not limited to human activity recognition, sleep stage classification, and machine fault diagnosis. Despite the numerous domain adaptation techniques proposed to tackle this complex problem, their primary focus has been on the common representations of time series data. This concentration might inadvertently lead to the oversight of valuable domain-specific information originating from different source domains. To bridge this gap, we introduce POND, a novel prompt-based deep learning model designed explicitly for multi-source time series domain adaptation. POND is tailored to address significant challenges, notably: 1) The unavailability of a quantitative relationship between meta-data information and time series distributions, and 2) The dearth of exploration into extracting domain-specific meta-data information. In this paper, we present an instance-level prompt generator and a fidelity loss mechanism to facilitate the faithful learning of meta-data information. Additionally, we propose a domain discrimination technique to discern domain-specific meta-data information from multiple source domains. Our approach involves a simple yet effective meta-learning algorithm to optimize the objective efficiently. Furthermore, we augment the model's performance by incorporating the Mixture of Expert (MoE) technique. The efficacy and robustness of our proposed POND model are extensively validated through experiments across 50 scenarios encompassing five datasets, which demonstrates that our proposed POND model outperforms the state-of-the-art methods by up to $66\%$ on the F1-score.
Open-ended Commonsense Reasoning with Unrestricted Answer Scope
Oct 27, 2023Open-ended Commonsense Reasoning is defined as solving a commonsense question without providing 1) a short list of answer candidates and 2) a pre-defined answer scope. Conventional ways of formulating the commonsense question into a question-answering form or utilizing external knowledge to learn retrieval-based methods are less applicable in the open-ended setting due to an inherent challenge. Without pre-defining an answer scope or a few candidates, open-ended commonsense reasoning entails predicting answers by searching over an extremely large searching space. Moreover, most questions require implicit multi-hop reasoning, which presents even more challenges to our problem. In this work, we leverage pre-trained language models to iteratively retrieve reasoning paths on the external knowledge base, which does not require task-specific supervision. The reasoning paths can help to identify the most precise answer to the commonsense question. We conduct experiments on two commonsense benchmark datasets. Compared to other approaches, our proposed method achieves better performance both quantitatively and qualitatively.
DyExplainer: Explainable Dynamic Graph Neural Networks
Oct 25, 2023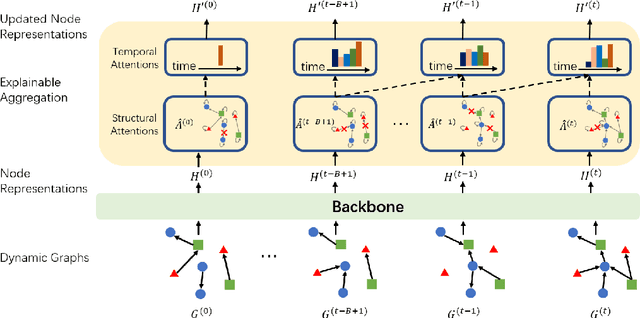

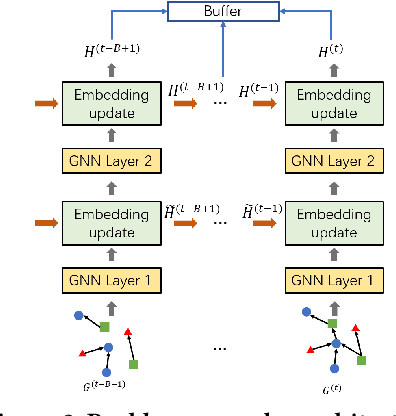
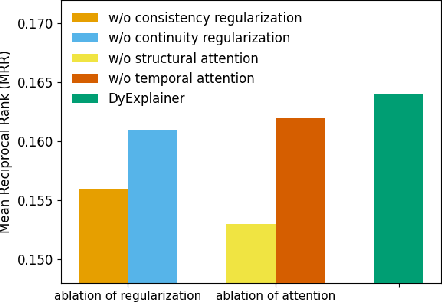
Graph Neural Networks (GNNs) resurge as a trending research subject owing to their impressive ability to capture representations from graph-structured data. However, the black-box nature of GNNs presents a significant challenge in terms of comprehending and trusting these models, thereby limiting their practical applications in mission-critical scenarios. Although there has been substantial progress in the field of explaining GNNs in recent years, the majority of these studies are centered on static graphs, leaving the explanation of dynamic GNNs largely unexplored. Dynamic GNNs, with their ever-evolving graph structures, pose a unique challenge and require additional efforts to effectively capture temporal dependencies and structural relationships. To address this challenge, we present DyExplainer, a novel approach to explaining dynamic GNNs on the fly. DyExplainer trains a dynamic GNN backbone to extract representations of the graph at each snapshot, while simultaneously exploring structural relationships and temporal dependencies through a sparse attention technique. To preserve the desired properties of the explanation, such as structural consistency and temporal continuity, we augment our approach with contrastive learning techniques to provide priori-guided regularization. To model longer-term temporal dependencies, we develop a buffer-based live-updating scheme for training. The results of our extensive experiments on various datasets demonstrate the superiority of DyExplainer, not only providing faithful explainability of the model predictions but also significantly improving the model prediction accuracy, as evidenced in the link prediction task.
A Survey on Detection of LLMs-Generated Content
Oct 24, 2023
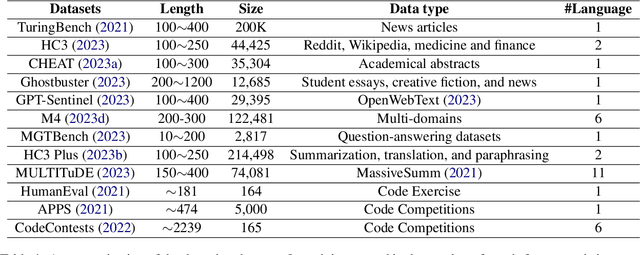
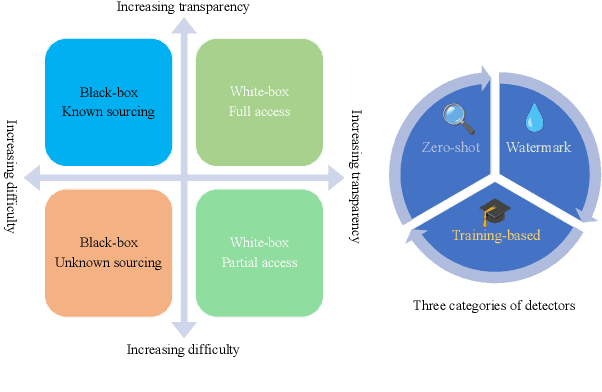

The burgeoning capabilities of advanced large language models (LLMs) such as ChatGPT have led to an increase in synthetic content generation with implications across a variety of sectors, including media, cybersecurity, public discourse, and education. As such, the ability to detect LLMs-generated content has become of paramount importance. We aim to provide a detailed overview of existing detection strategies and benchmarks, scrutinizing their differences and identifying key challenges and prospects in the field, advocating for more adaptable and robust models to enhance detection accuracy. We also posit the necessity for a multi-faceted approach to defend against various attacks to counter the rapidly advancing capabilities of LLMs. To the best of our knowledge, this work is the first comprehensive survey on the detection in the era of LLMs. We hope it will provide a broad understanding of the current landscape of LLMs-generated content detection, offering a guiding reference for researchers and practitioners striving to uphold the integrity of digital information in an era increasingly dominated by synthetic content. The relevant papers are summarized and will be consistently updated at https://github.com/Xianjun-Yang/Awesome_papers_on_LLMs_detection.git.