 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinjie Xu
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024
The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Mildly Constrained Evaluation Policy for Offline Reinforcement Learning
Jun 06, 2023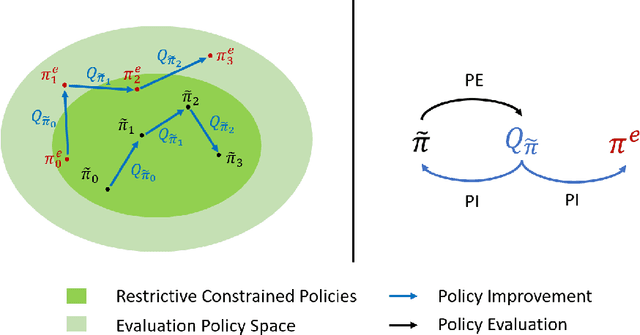


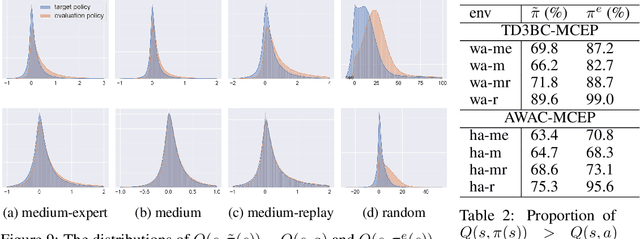
Offline reinforcement learning (RL) methodologies enforce constraints on the policy to adhere closely to the behavior policy, thereby stabilizing value learning and mitigating the selection of out-of-distribution (OOD) actions during test time. Conventional approaches apply identical constraints for both value learning and test time inference. However, our findings indicate that the constraints suitable for value estimation may in fact be excessively restrictive for action selection during test time. To address this issue, we propose a Mildly Constrained Evaluation Policy (MCEP) for test time inference with a more constrained target policy for value estimation. Since the target policy has been adopted in various prior approaches, MCEP can be seamlessly integrated with them as a plug-in. We instantiate MCEP based on TD3-BC [Fujimoto and Gu, 2021] and AWAC [Nair et al., 2020] algorithms. The empirical results on MuJoCo locomotion tasks show that the MCEP significantly outperforms the target policy and achieves competitive results to state-of-the-art offline RL methods. The codes are open-sourced at https://github.com/egg-west/MCEP.git.
Elastic Monte Carlo Tree Search with State Abstraction for Strategy Game Playing
May 30, 2022



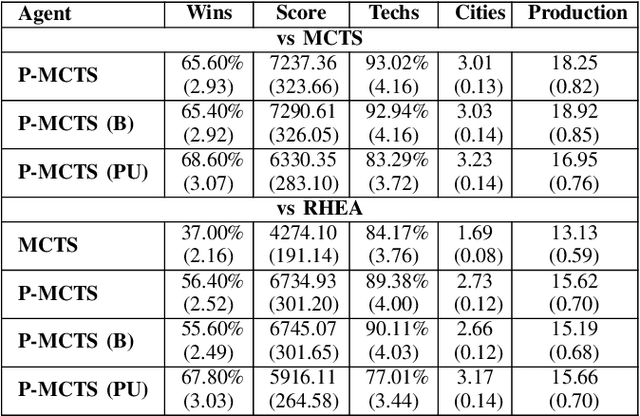
Strategy video games challenge AI agents with their combinatorial search space caused by complex game elements. State abstraction is a popular technique that reduces the state space complexity. However, current state abstraction methods for games depend on domain knowledge, making their application to new games expensive. State abstraction methods that require no domain knowledge are studied extensively in the planning domain. However, no evidence shows they scale well with the complexity of strategy games. In this paper, we propose Elastic MCTS, an algorithm that uses state abstraction to play strategy games. In Elastic MCTS, the nodes of the tree are clustered dynamically, first grouped together progressively by state abstraction, and then separated when an iteration threshold is reached. The elastic changes benefit from efficient searching brought by state abstraction but avoid the negative influence of using state abstraction for the whole search. To evaluate our method, we make use of the general strategy games platform Stratega to generate scenarios of varying complexity. Results show that Elastic MCTS outperforms MCTS baselines with a large margin, while reducing the tree size by a factor of $10$. Code can be found at: https://github.com/egg-west/Stratega
Portfolio Search and Optimization for General Strategy Game-Playing
Apr 21, 2021

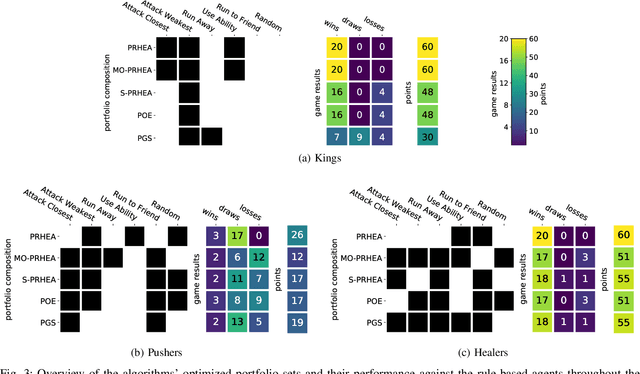
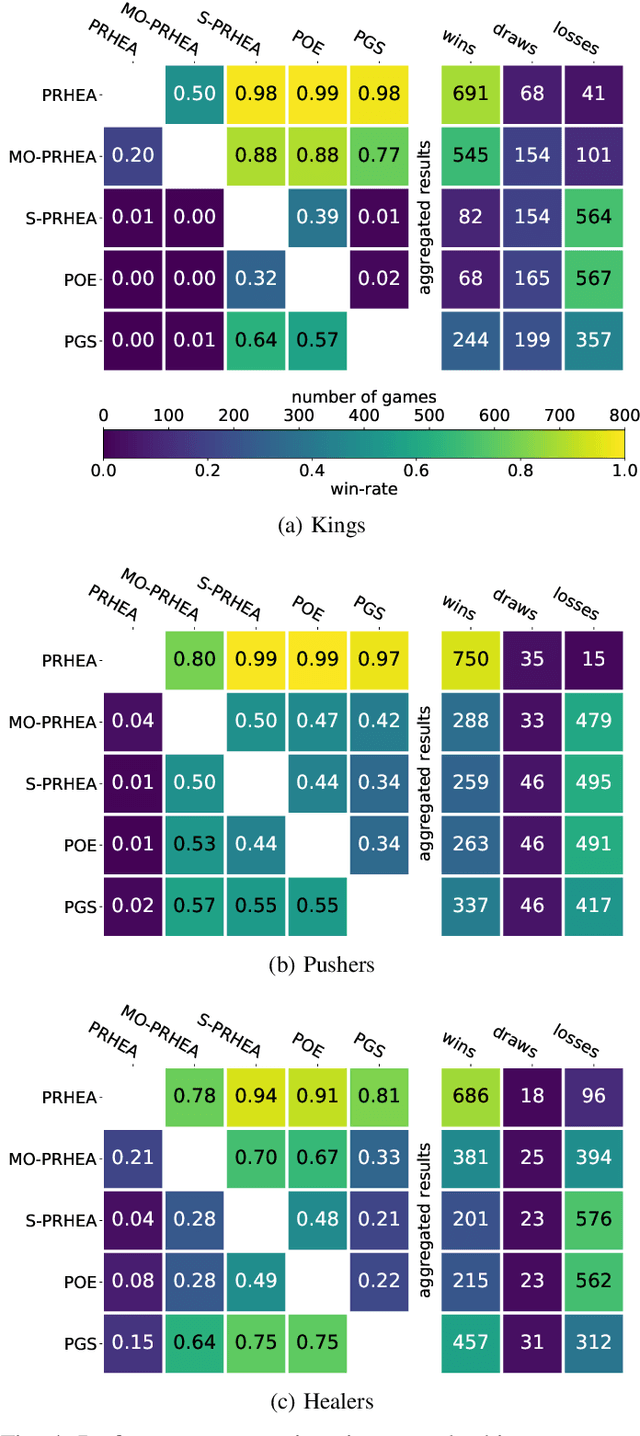
Portfolio methods represent a simple but efficient type of action abstraction which has shown to improve the performance of search-based agents in a range of strategy games. We first review existing portfolio techniques and propose a new algorithm for optimization and action-selection based on the Rolling Horizon Evolutionary Algorithm. Moreover, a series of variants are developed to solve problems in different aspects. We further analyze the performance of discussed agents in a general strategy game-playing task. For this purpose, we run experiments on three different game-modes of the Stratega framework. For the optimization of the agents' parameters and portfolio sets we study the use of the N-tuple Bandit Evolutionary Algorithm. The resulting portfolio sets suggest a high diversity in play-styles while being able to consistently beat the sample agents. An analysis of the agents' performance shows that the proposed algorithm generalizes well to all game-modes and is able to outperform other portfolio methods.
Generating Diverse and Competitive Play-Styles for Strategy Games
Apr 17, 2021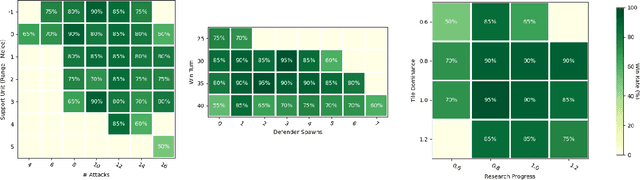

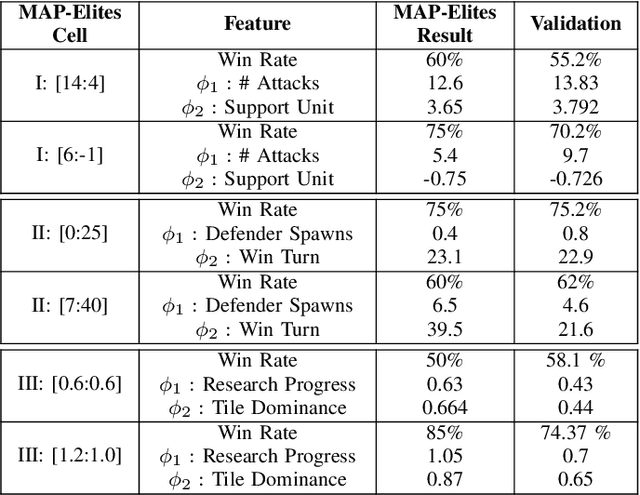
Designing agents that are able to achieve different play-styles while maintaining a competitive level of play is a difficult task, especially for games for which the research community has not found super-human performance yet, like strategy games. These require the AI to deal with large action spaces, long-term planning and partial observability, among other well-known factors that make decision-making a hard problem. On top of this, achieving distinct play-styles using a general algorithm without reducing playing strength is not trivial. In this paper, we propose Portfolio Monte Carlo Tree Search with Progressive Unpruning for playing a turn-based strategy game (Tribes) and show how it can be parameterized so a quality-diversity algorithm (MAP-Elites) is used to achieve different play-styles while keeping a competitive level of play. Our results show that this algorithm is capable of achieving these goals even for an extensive collection of game levels beyond those used for training.
Deep Multi-Task Augmented Feature Learning via Hierarchical Graph Neural Network
Feb 12, 2020



Deep multi-task learning attracts much attention in recent years as it achieves good performance in many applications. Feature learning is important to deep multi-task learning for sharing common information among tasks. In this paper, we propose a Hierarchical Graph Neural Network (HGNN) to learn augmented features for deep multi-task learning. The HGNN consists of two-level graph neural networks. In the low level, an intra-task graph neural network is responsible of learning a powerful representation for each data point in a task by aggregating its neighbors. Based on the learned representation, a task embedding can be generated for each task in a similar way to max pooling. In the second level, an inter-task graph neural network updates task embeddings of all the tasks based on the attention mechanism to model task relations. Then the task embedding of one task is used to augment the feature representation of data points in this task. Moreover, for classification tasks, an inter-class graph neural network is introduced to conduct similar operations on a finer granularity, i.e., the class level, to generate class embeddings for each class in all the tasks use class embeddings to augment the feature representation. The proposed feature augmentation strategy can be used in many deep multi-task learning models. we analyze the HGNN in terms of training and generalization losses. Experiments on real-world datastes show the significant performance improvement when using this strategy.