 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZichuan Liu
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024
The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.
RCAgent: Cloud Root Cause Analysis by Autonomous Agents with Tool-Augmented Large Language Models
Oct 25, 2023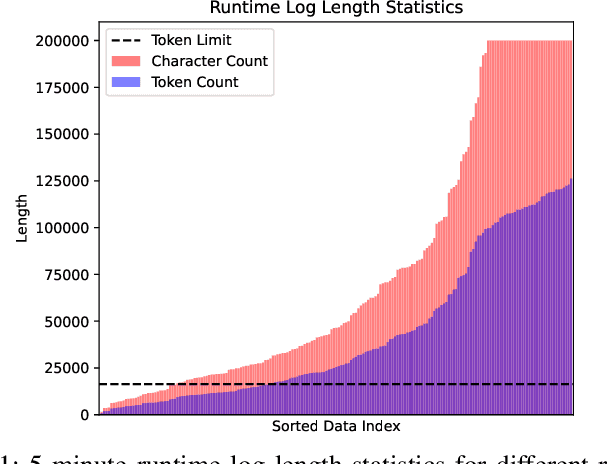
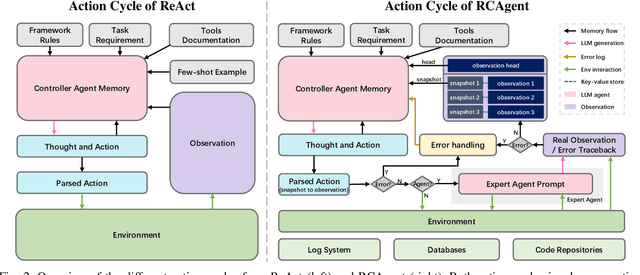

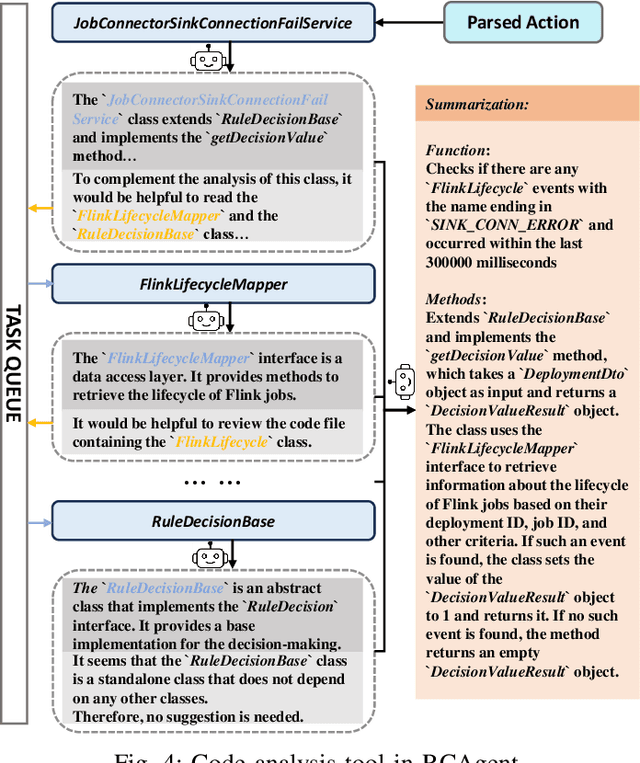
Large language model (LLM) applications in cloud root cause analysis (RCA) have been actively explored recently. However, current methods are still reliant on manual workflow settings and do not unleash LLMs' decision-making and environment interaction capabilities. We present RCAgent, a tool-augmented LLM autonomous agent framework for practical and privacy-aware industrial RCA usage. Running on an internally deployed model rather than GPT families, RCAgent is capable of free-form data collection and comprehensive analysis with tools. Our framework combines a variety of enhancements, including a unique Self-Consistency for action trajectories, and a suite of methods for context management, stabilization, and importing domain knowledge. Our experiments show RCAgent's evident and consistent superiority over ReAct across all aspects of RCA -- predicting root causes, solutions, evidence, and responsibilities -- and tasks covered or uncovered by current rules, as validated by both automated metrics and human evaluations. Furthermore, RCAgent has already been integrated into the diagnosis and issue discovery workflow of the Real-time Compute Platform for Apache Flink of Alibaba Cloud.
Boosting Value Decomposition via Unit-Wise Attentive State Representation for Cooperative Multi-Agent Reinforcement Learning
May 12, 2023



In cooperative multi-agent reinforcement learning (MARL), the environmental stochasticity and uncertainties will increase exponentially when the number of agents increases, which puts hard pressure on how to come up with a compact latent representation from partial observation for boosting value decomposition. To tackle these issues, we propose a simple yet powerful method that alleviates partial observability and efficiently promotes coordination by introducing the UNit-wise attentive State Representation (UNSR). In UNSR, each agent learns a compact and disentangled unit-wise state representation outputted from transformer blocks, and produces its local action-value function. The proposed UNSR is used to boost the value decomposition with a multi-head attention mechanism for producing efficient credit assignment in the mixing network, providing an efficient reasoning path between the individual value function and joint value function. Experimental results demonstrate that our method achieves superior performance and data efficiency compared to solid baselines on the StarCraft II micromanagement challenge. Additional ablation experiments also help identify the key factors contributing to the performance of UNSR.
Reinforcement Learning for Self-exploration in Narrow Spaces
Sep 17, 2022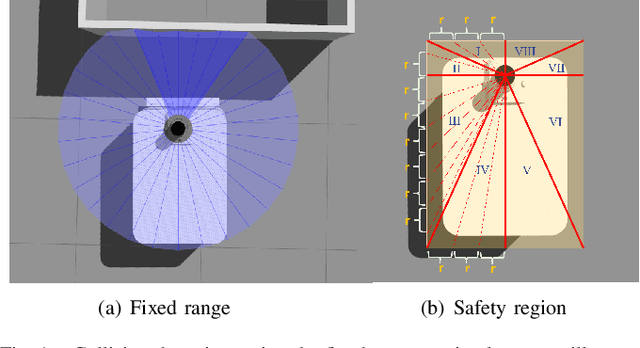
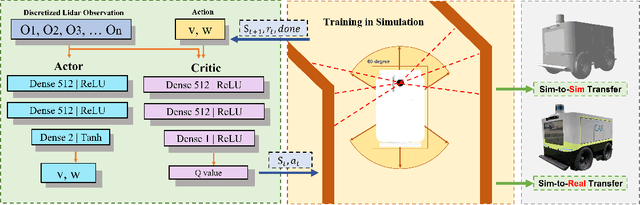

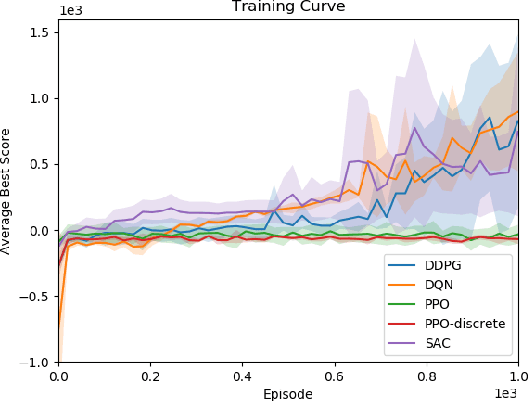
In narrow spaces, motion planning based on the traditional hierarchical autonomous system could cause collisions due to mapping, localization, and control noises. Additionally, it is disabled when mapless. To tackle these problems, we leverage deep reinforcement learning which is verified to be effective in self-decision-making, to self-explore in narrow spaces without a map while avoiding collisions. Specifically, based on our Ackermann-steering rectangular-shaped ZebraT robot and its Gazebo simulator, we propose the rectangular safety region to represent states and detect collisions for rectangular-shaped robots, and a carefully crafted reward function for reinforcement learning that does not require the destination information. Then we benchmark five reinforcement learning algorithms including DDPG, DQN, SAC, PPO, and PPO-discrete, in a simulated narrow track. After training, the well-performed DDPG and DQN models can be transferred to three brand new simulated tracks, and furthermore to three real-world tracks.
MIXRTs: Toward Interpretable Multi-Agent Reinforcement Learning via Mixing Recurrent Soft Decision Trees
Sep 15, 2022



Multi-agent reinforcement learning (MARL) recently has achieved tremendous success in a wide range of fields. However, with a black-box neural network architecture, existing MARL methods make decisions in an opaque fashion that hinders humans from understanding the learned knowledge and how input observations influence decisions. Our solution is MIXing Recurrent soft decision Trees (MIXRTs), a novel interpretable architecture that can represent explicit decision processes via the root-to-leaf path of decision trees. We introduce a novel recurrent structure in soft decision trees to address partial observability, and estimate joint action values via linearly mixing outputs of recurrent trees based on local observations only. Theoretical analysis shows that MIXRTs guarantees the structural constraint with additivity and monotonicity in factorization. We evaluate MIXRTs on a range of challenging StarCraft II tasks. Experimental results show that our interpretable learning framework obtains competitive performance compared to widely investigated baselines, and delivers more straightforward explanations and domain knowledge of the decision processes.
Simulators for Mobile Social Robots:State-of-the-Art and Challenges
Feb 08, 2022



The future robots are expected to work in a shared physical space with humans [1], however, the presence of humans leads to a dynamic environment that is challenging for mobile robots to navigate. The path planning algorithms designed to navigate a collision free path in complex human environments are often tested in real environments due to the lack of simulation frameworks. This paper identifies key requirements for an ideal simulator for this task, evaluates existing simulation frameworks and most importantly, it identifies the challenges and limitations of the existing simulation techniques. First and foremost, we recognize that the simulators needed for the purpose of testing mobile robots designed for human environments are unique as they must model realistic pedestrian behavior in addition to the modelling of mobile robots. Our study finds that Pedsim_ros [2] and a more recent SocNavBench framework [3] are the only two 3D simulation frameworks that meet most of the key requirements defined in our paper. In summary, we identify the need for developing more simulators that offer an ability to create realistic 3D pedestrian rich virtual environments along with the flexibility of designing complex robots and their sensor models from scratch.
Spatial-Temporal Conv-sequence Learning with Accident Encoding for Traffic Flow Prediction
May 21, 2021



In intelligent transportation system, the key problem of traffic forecasting is how to extract the periodic temporal dependencies and complex spatial correlation. Current state-of-the-art methods for traffic flow prediction are based on graph architectures and sequence learning models, but they do not fully exploit spatial-temporal dynamic information in traffic system. Specifically, the temporal dependence of short-range is diluted by recurrent neural networks, and existing sequence model ignores local spatial information because the convolution operation uses global average pooling. Besides, there will be some traffic accidents during the transitions of objects causing congestion in the real world that trigger increased prediction deviation. To overcome these challenges, we propose the Spatial-Temporal Conv-sequence Learning (STCL), in which a focused temporal block uses unidirectional convolution to effectively capture short-term periodic temporal dependence, and a spatial-temporal fusion module is able to extract the dependencies of both interactions and decrease the feature dimensions. Moreover, the accidents features impact on local traffic congestion and position encoding is employed to detect anomalies in complex traffic situations. We conduct extensive experiments on large-scale real-world tasks and verify the effectiveness of our proposed method.
Progressive Self-Guided Loss for Salient Object Detection
Jan 07, 2021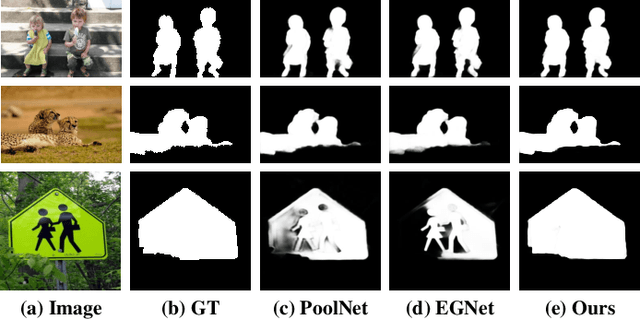
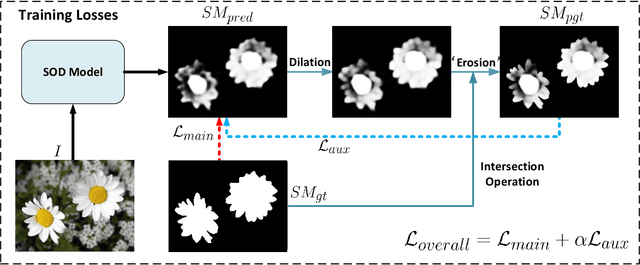
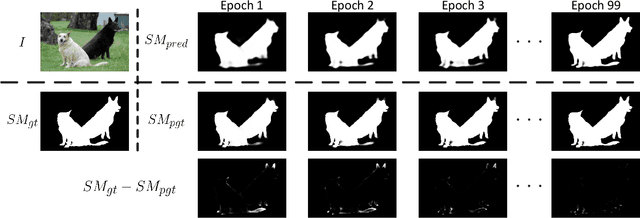
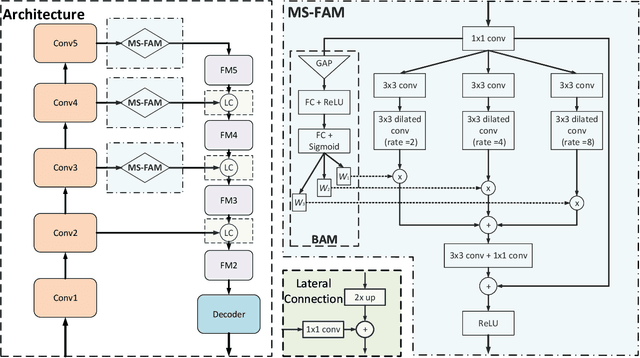
We present a simple yet effective progressive self-guided loss function to facilitate deep learning-based salient object detection (SOD) in images. The saliency maps produced by the most relevant works still suffer from incomplete predictions due to the internal complexity of salient objects. Our proposed progressive self-guided loss simulates a morphological closing operation on the model predictions for epoch-wisely creating progressive and auxiliary training supervisions to step-wisely guide the training process. We demonstrate that this new loss function can guide the SOD model to highlight more complete salient objects step-by-step and meanwhile help to uncover the spatial dependencies of the salient object pixels in a region growing manner. Moreover, a new feature aggregation module is proposed to capture multi-scale features and aggregate them adaptively by a branch-wise attention mechanism. Benefiting from this module, our SOD framework takes advantage of adaptively aggregated multi-scale features to locate and detect salient objects effectively. Experimental results on several benchmark datasets show that our loss function not only advances the performance of existing SOD models without architecture modification but also helps our proposed framework to achieve state-of-the-art performance.