 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Song
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024
The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Reinforced In-Context Black-Box Optimization
Feb 27, 2024Black-Box Optimization (BBO) has found successful applications in many fields of science and engineering. Recently, there has been a growing interest in meta-learning particular components of BBO algorithms to speed up optimization and get rid of tedious hand-crafted heuristics. As an extension, learning the entire algorithm from data requires the least labor from experts and can provide the most flexibility. In this paper, we propose RIBBO, a method to reinforce-learn a BBO algorithm from offline data in an end-to-end fashion. RIBBO employs expressive sequence models to learn the optimization histories produced by multiple behavior algorithms and tasks, leveraging the in-context learning ability of large models to extract task information and make decisions accordingly. Central to our method is to augment the optimization histories with regret-to-go tokens, which are designed to represent the performance of an algorithm based on cumulative regret of the histories. The integration of regret-to-go tokens enables RIBBO to automatically generate sequences of query points that satisfy the user-desired regret, which is verified by its universally good empirical performance on diverse problems, including BBOB functions, hyper-parameter optimization and robot control problems.
Stochastic Bayesian Optimization with Unknown Continuous Context Distribution via Kernel Density Estimation
Dec 21, 2023Bayesian optimization (BO) is a sample-efficient method and has been widely used for optimizing expensive black-box functions. Recently, there has been a considerable interest in BO literature in optimizing functions that are affected by context variable in the environment, which is uncontrollable by decision makers. In this paper, we focus on the optimization of functions' expectations over continuous context variable, subject to an unknown distribution. To address this problem, we propose two algorithms that employ kernel density estimation to learn the probability density function (PDF) of continuous context variable online. The first algorithm is simpler, which directly optimizes the expectation under the estimated PDF. Considering that the estimated PDF may have high estimation error when the true distribution is complicated, we further propose the second algorithm that optimizes the distributionally robust objective. Theoretical results demonstrate that both algorithms have sub-linear Bayesian cumulative regret on the expectation objective. Furthermore, we conduct numerical experiments to empirically demonstrate the effectiveness of our algorithms.
Pre-Trained Large Language Models for Industrial Control
Aug 06, 2023For industrial control, developing high-performance controllers with few samples and low technical debt is appealing. Foundation models, possessing rich prior knowledge obtained from pre-training with Internet-scale corpus, have the potential to be a good controller with proper prompts. In this paper, we take HVAC (Heating, Ventilation, and Air Conditioning) building control as an example to examine the ability of GPT-4 (one of the first-tier foundation models) as the controller. To control HVAC, we wrap the task as a language game by providing text including a short description for the task, several selected demonstrations, and the current observation to GPT-4 on each step and execute the actions responded by GPT-4. We conduct series of experiments to answer the following questions: 1)~How well can GPT-4 control HVAC? 2)~How well can GPT-4 generalize to different scenarios for HVAC control? 3) How different parts of the text context affect the performance? In general, we found GPT-4 achieves the performance comparable to RL methods with few samples and low technical debt, indicating the potential of directly applying foundation models to industrial control tasks.
Macro Placement by Wire-Mask-Guided Black-Box Optimization
Jul 18, 2023The development of very large-scale integration (VLSI) technology has posed new challenges for electronic design automation (EDA) techniques in chip floorplanning. During this process, macro placement is an important subproblem, which tries to determine the positions of all macros with the aim of minimizing half-perimeter wirelength (HPWL) and avoiding overlapping. Previous methods include packing-based, analytical and reinforcement learning methods. In this paper, we propose a new black-box optimization (BBO) framework (called WireMask-BBO) for macro placement, by using a wire-mask-guided greedy procedure for objective evaluation. Equipped with different BBO algorithms, WireMask-BBO empirically achieves significant improvements over previous methods, i.e., achieves significantly shorter HPWL by using much less time. Furthermore, it can fine-tune existing placements by treating them as initial solutions, which can bring up to 50% improvement in HPWL. WireMask-BBO has the potential to significantly improve the quality and efficiency of chip floorplanning, which makes it appealing to researchers and practitioners in EDA and will also promote the application of BBO.
A Versatile Multi-Agent Reinforcement Learning Benchmark for Inventory Management
Jun 13, 2023
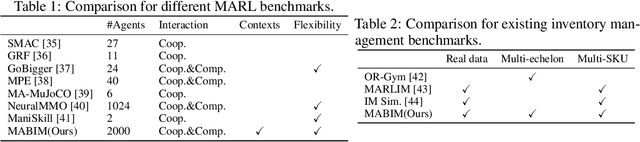

Multi-agent reinforcement learning (MARL) models multiple agents that interact and learn within a shared environment. This paradigm is applicable to various industrial scenarios such as autonomous driving, quantitative trading, and inventory management. However, applying MARL to these real-world scenarios is impeded by many challenges such as scaling up, complex agent interactions, and non-stationary dynamics. To incentivize the research of MARL on these challenges, we develop MABIM (Multi-Agent Benchmark for Inventory Management) which is a multi-echelon, multi-commodity inventory management simulator that can generate versatile tasks with these different challenging properties. Based on MABIM, we evaluate the performance of classic operations research (OR) methods and popular MARL algorithms on these challenging tasks to highlight their weaknesses and potential.
Mildly Constrained Evaluation Policy for Offline Reinforcement Learning
Jun 06, 2023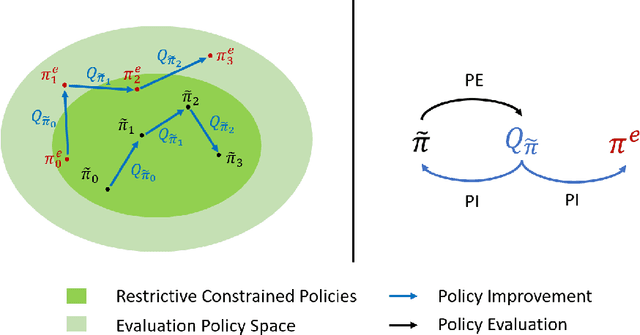


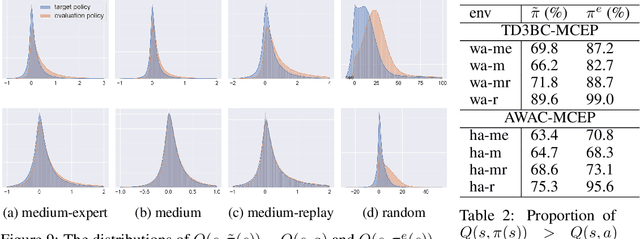
Offline reinforcement learning (RL) methodologies enforce constraints on the policy to adhere closely to the behavior policy, thereby stabilizing value learning and mitigating the selection of out-of-distribution (OOD) actions during test time. Conventional approaches apply identical constraints for both value learning and test time inference. However, our findings indicate that the constraints suitable for value estimation may in fact be excessively restrictive for action selection during test time. To address this issue, we propose a Mildly Constrained Evaluation Policy (MCEP) for test time inference with a more constrained target policy for value estimation. Since the target policy has been adopted in various prior approaches, MCEP can be seamlessly integrated with them as a plug-in. We instantiate MCEP based on TD3-BC [Fujimoto and Gu, 2021] and AWAC [Nair et al., 2020] algorithms. The empirical results on MuJoCo locomotion tasks show that the MCEP significantly outperforms the target policy and achieves competitive results to state-of-the-art offline RL methods. The codes are open-sourced at https://github.com/egg-west/MCEP.git.
RFR-WWANet: Weighted Window Attention-Based Recovery Feature Resolution Network for Unsupervised Image Registration
May 07, 2023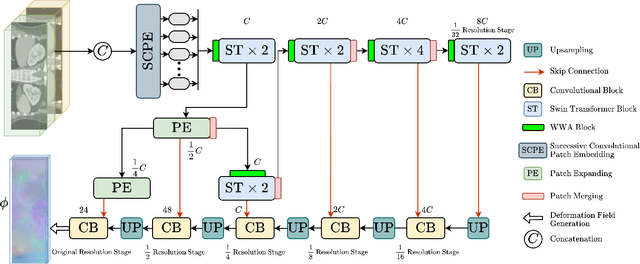
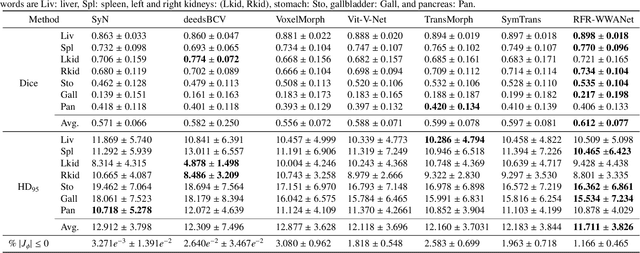


The Swin transformer has recently attracted attention in medical image analysis due to its computational efficiency and long-range modeling capability, which enables the establishment of more distant relationships between corresponding voxels. However, transformer-based models split images into tokens, which results in transformers that can only model and output coarse-grained spatial information representations. To address this issue, we propose Recovery Feature Resolution Network (RFRNet), which enables the transformer to contribute with fine-grained spatial information and rich semantic correspondences. Furthermore, shifted window partitioning operations are inflexible, indicating that they cannot perceive the semantic information over uncertain distances and automatically bridge the global connections between windows. Therefore, we present a Weighted Window Attention (WWA) to automatically build global interactions between windows after the regular and cyclic shifted window partitioning operations for Swin transformer blocks. The proposed unsupervised deformable image registration model, named RFR-WWANet, senses the long-range correlations, thereby facilitating meaningful semantic relevance of anatomical structures. Qualitative and quantitative results show that RFR-WWANet achieves significant performance improvements over baseline methods. Ablation experiments demonstrate the effectiveness of the RFRNet and WWA designs.
Pointerformer: Deep Reinforced Multi-Pointer Transformer for the Traveling Salesman Problem
Apr 19, 2023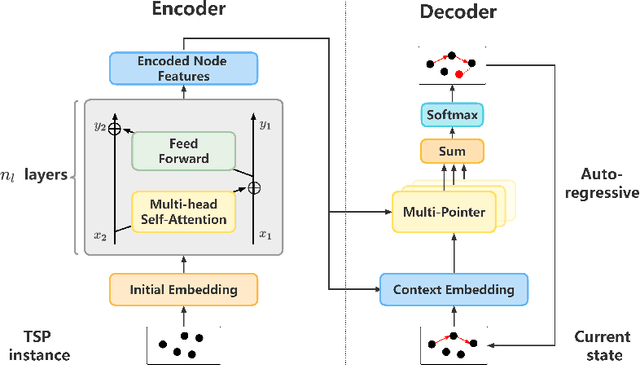
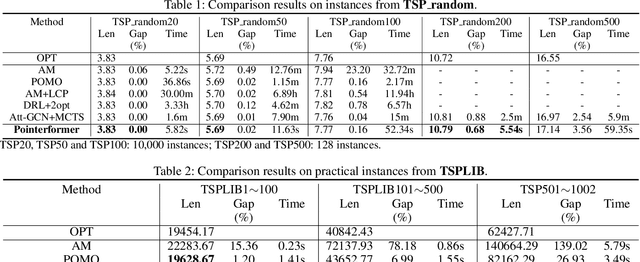
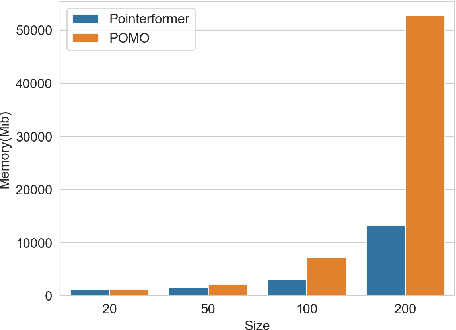
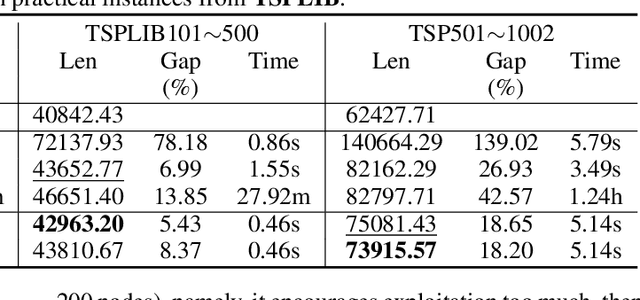
Traveling Salesman Problem (TSP), as a classic routing optimization problem originally arising in the domain of transportation and logistics, has become a critical task in broader domains, such as manufacturing and biology. Recently, Deep Reinforcement Learning (DRL) has been increasingly employed to solve TSP due to its high inference efficiency. Nevertheless, most of existing end-to-end DRL algorithms only perform well on small TSP instances and can hardly generalize to large scale because of the drastically soaring memory consumption and computation time along with the enlarging problem scale. In this paper, we propose a novel end-to-end DRL approach, referred to as Pointerformer, based on multi-pointer Transformer. Particularly, Pointerformer adopts both reversible residual network in the encoder and multi-pointer network in the decoder to effectively contain memory consumption of the encoder-decoder architecture. To further improve the performance of TSP solutions, Pointerformer employs both a feature augmentation method to explore the symmetries of TSP at both training and inference stages as well as an enhanced context embedding approach to include more comprehensive context information in the query. Extensive experiments on a randomly generated benchmark and a public benchmark have shown that, while achieving comparative results on most small-scale TSP instances as SOTA DRL approaches do, Pointerformer can also well generalize to large-scale TSPs.