 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunlin Chen
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024
The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Apr 18, 2024We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at \href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
Explaining Time Series via Contrastive and Locally Sparse Perturbations
Jan 29, 2024Explaining multivariate time series is a compound challenge, as it requires identifying important locations in the time series and matching complex temporal patterns. Although previous saliency-based methods addressed the challenges, their perturbation may not alleviate the distribution shift issue, which is inevitable especially in heterogeneous samples. We present ContraLSP, a locally sparse model that introduces counterfactual samples to build uninformative perturbations but keeps distribution using contrastive learning. Furthermore, we incorporate sample-specific sparse gates to generate more binary-skewed and smooth masks, which easily integrate temporal trends and select the salient features parsimoniously. Empirical studies on both synthetic and real-world datasets show that ContraLSP outperforms state-of-the-art models, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/ContraLSP}.
Joint Projection Learning and Tensor Decomposition Based Incomplete Multi-view Clustering
Oct 06, 2023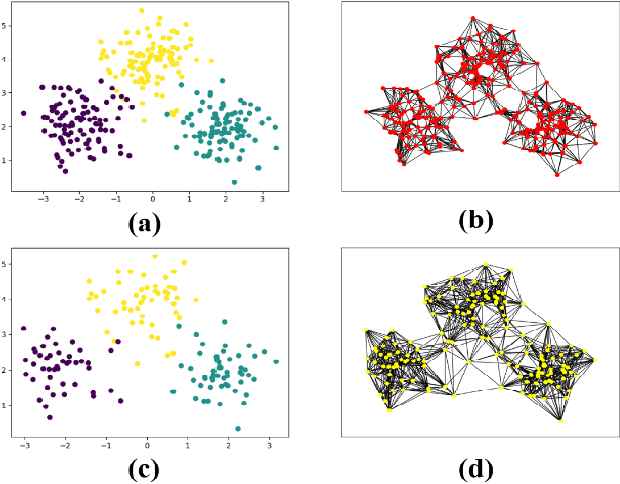
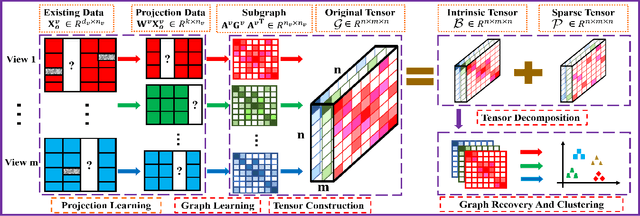
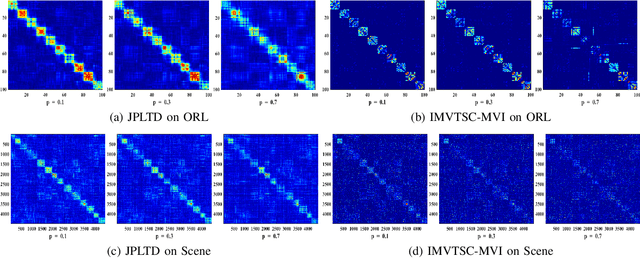

Incomplete multi-view clustering (IMVC) has received increasing attention since it is often that some views of samples are incomplete in reality. Most existing methods learn similarity subgraphs from original incomplete multi-view data and seek complete graphs by exploring the incomplete subgraphs of each view for spectral clustering. However, the graphs constructed on the original high-dimensional data may be suboptimal due to feature redundancy and noise. Besides, previous methods generally ignored the graph noise caused by the inter-class and intra-class structure variation during the transformation of incomplete graphs and complete graphs. To address these problems, we propose a novel Joint Projection Learning and Tensor Decomposition Based method (JPLTD) for IMVC. Specifically, to alleviate the influence of redundant features and noise in high-dimensional data, JPLTD introduces an orthogonal projection matrix to project the high-dimensional features into a lower-dimensional space for compact feature learning.Meanwhile, based on the lower-dimensional space, the similarity graphs corresponding to instances of different views are learned, and JPLTD stacks these graphs into a third-order low-rank tensor to explore the high-order correlations across different views. We further consider the graph noise of projected data caused by missing samples and use a tensor-decomposition based graph filter for robust clustering.JPLTD decomposes the original tensor into an intrinsic tensor and a sparse tensor. The intrinsic tensor models the true data similarities. An effective optimization algorithm is adopted to solve the JPLTD model. Comprehensive experiments on several benchmark datasets demonstrate that JPLTD outperforms the state-of-the-art methods. The code of JPLTD is available at https://github.com/weilvNJU/JPLTD.
BiERL: A Meta Evolutionary Reinforcement Learning Framework via Bilevel Optimization
Aug 01, 2023



Evolutionary reinforcement learning (ERL) algorithms recently raise attention in tackling complex reinforcement learning (RL) problems due to high parallelism, while they are prone to insufficient exploration or model collapse without carefully tuning hyperparameters (aka meta-parameters). In the paper, we propose a general meta ERL framework via bilevel optimization (BiERL) to jointly update hyperparameters in parallel to training the ERL model within a single agent, which relieves the need for prior domain knowledge or costly optimization procedure before model deployment. We design an elegant meta-level architecture that embeds the inner-level's evolving experience into an informative population representation and introduce a simple and feasible evaluation of the meta-level fitness function to facilitate learning efficiency. We perform extensive experiments in MuJoCo and Box2D tasks to verify that as a general framework, BiERL outperforms various baselines and consistently improves the learning performance for a diversity of ERL algorithms.
Magnetic Field-Based Reward Shaping for Goal-Conditioned Reinforcement Learning
Jul 16, 2023



Goal-conditioned reinforcement learning (RL) is an interesting extension of the traditional RL framework, where the dynamic environment and reward sparsity can cause conventional learning algorithms to fail. Reward shaping is a practical approach to improving sample efficiency by embedding human domain knowledge into the learning process. Existing reward shaping methods for goal-conditioned RL are typically built on distance metrics with a linear and isotropic distribution, which may fail to provide sufficient information about the ever-changing environment with high complexity. This paper proposes a novel magnetic field-based reward shaping (MFRS) method for goal-conditioned RL tasks with dynamic target and obstacles. Inspired by the physical properties of magnets, we consider the target and obstacles as permanent magnets and establish the reward function according to the intensity values of the magnetic field generated by these magnets. The nonlinear and anisotropic distribution of the magnetic field intensity can provide more accessible and conducive information about the optimization landscape, thus introducing a more sophisticated magnetic reward compared to the distance-based setting. Further, we transform our magnetic reward to the form of potential-based reward shaping by learning a secondary potential function concurrently to ensure the optimal policy invariance of our method. Experiments results in both simulated and real-world robotic manipulation tasks demonstrate that MFRS outperforms relevant existing methods and effectively improves the sample efficiency of RL algorithms in goal-conditioned tasks with various dynamics of the target and obstacles.
Boosting Value Decomposition via Unit-Wise Attentive State Representation for Cooperative Multi-Agent Reinforcement Learning
May 12, 2023



In cooperative multi-agent reinforcement learning (MARL), the environmental stochasticity and uncertainties will increase exponentially when the number of agents increases, which puts hard pressure on how to come up with a compact latent representation from partial observation for boosting value decomposition. To tackle these issues, we propose a simple yet powerful method that alleviates partial observability and efficiently promotes coordination by introducing the UNit-wise attentive State Representation (UNSR). In UNSR, each agent learns a compact and disentangled unit-wise state representation outputted from transformer blocks, and produces its local action-value function. The proposed UNSR is used to boost the value decomposition with a multi-head attention mechanism for producing efficient credit assignment in the mixing network, providing an efficient reasoning path between the individual value function and joint value function. Experimental results demonstrate that our method achieves superior performance and data efficiency compared to solid baselines on the StarCraft II micromanagement challenge. Additional ablation experiments also help identify the key factors contributing to the performance of UNSR.
Attention-Based Transformer Networks for Quantum State Tomography
May 09, 2023



Neural networks have been actively explored for quantum state tomography (QST) due to their favorable expressibility. To further enhance the efficiency of reconstructing quantum states, we explore the similarity between language modeling and quantum state tomography and propose an attention-based QST method that utilizes the Transformer network to capture the correlations between measured results from different measurements. Our method directly retrieves the density matrices of quantum states from measured statistics, with the assistance of an integrated loss function that helps minimize the difference between the actual states and the retrieved states. Then, we systematically trace different impacts within a bag of common training strategies involving various parameter adjustments on the attention-based QST method. Combining these techniques, we establish a robust baseline that can efficiently reconstruct pure and mixed quantum states. Furthermore, by comparing the performance of three popular neural network architectures (FCNs, CNNs, and Transformer), we demonstrate the remarkable expressiveness of attention in learning density matrices from measured statistics.
MIXRTs: Toward Interpretable Multi-Agent Reinforcement Learning via Mixing Recurrent Soft Decision Trees
Sep 15, 2022



Multi-agent reinforcement learning (MARL) recently has achieved tremendous success in a wide range of fields. However, with a black-box neural network architecture, existing MARL methods make decisions in an opaque fashion that hinders humans from understanding the learned knowledge and how input observations influence decisions. Our solution is MIXing Recurrent soft decision Trees (MIXRTs), a novel interpretable architecture that can represent explicit decision processes via the root-to-leaf path of decision trees. We introduce a novel recurrent structure in soft decision trees to address partial observability, and estimate joint action values via linearly mixing outputs of recurrent trees based on local observations only. Theoretical analysis shows that MIXRTs guarantees the structural constraint with additivity and monotonicity in factorization. We evaluate MIXRTs on a range of challenging StarCraft II tasks. Experimental results show that our interpretable learning framework obtains competitive performance compared to widely investigated baselines, and delivers more straightforward explanations and domain knowledge of the decision processes.
Model-Aware Contrastive Learning: Towards Escaping Uniformity-Tolerance Dilemma in Training
Jul 16, 2022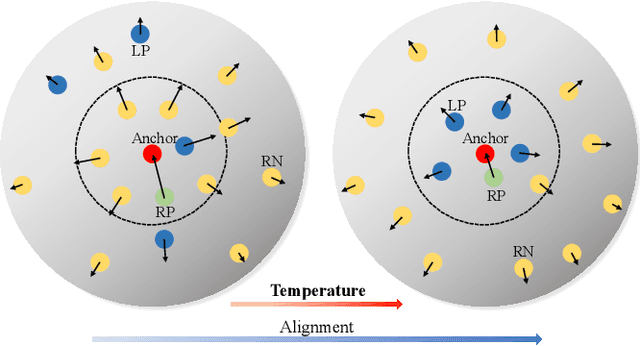
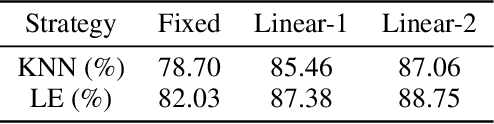

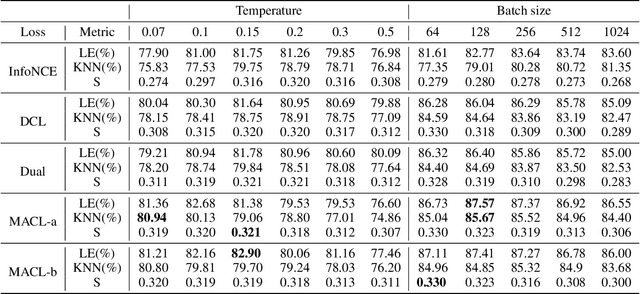
Instance discrimination contrastive learning (CL) has achieved significant success in learning transferable representations. A hardness-aware property related to the temperature $ \tau $ of the CL loss is identified to play an essential role in automatically concentrating on hard negative samples. However, previous work also proves that there exists a uniformity-tolerance dilemma (UTD) in CL loss, which will lead to unexpected performance degradation. Specifically, a smaller temperature helps to learn separable embeddings but has less tolerance to semantically related samples, which may result in suboptimal embedding space, and vice versa. In this paper, we propose a Model-Aware Contrastive Learning (MACL) strategy to escape UTD. For the undertrained phases, there is less possibility that the high similarity region of the anchor contains latent positive samples. Thus, adopting a small temperature in these stages can impose larger penalty strength on hard negative samples to improve the discrimination of the CL model. In contrast, a larger temperature in the well-trained phases helps to explore semantic structures due to more tolerance to potential positive samples. During implementation, the temperature in MACL is designed to be adaptive to the alignment property that reflects the confidence of a CL model. Furthermore, we reexamine why contrastive learning requires a large number of negative samples in a unified gradient reduction perspective. Based on MACL and these analyses, a new CL loss is proposed in this work to improve the learned representations and training with small batch size.