 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZizheng Huang
Conditional Prototype Rectification Prompt Learning
Apr 15, 2024
Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at \url{https://github.com/chenhaoxing/CPR}.
Boosting Audio-visual Zero-shot Learning with Large Language Models
Nov 21, 2023Audio-visual zero-shot learning aims to recognize unseen categories based on paired audio-visual sequences. Recent methods mainly focus on learning aligned and discriminative multi-modal features to boost generalization towards unseen categories. However, these approaches ignore the obscure action concepts in category names and may inevitably introduce complex network structures with difficult training objectives. In this paper, we propose a simple yet effective framework named Knowledge-aware Distribution Adaptation (KDA) to help the model better grasp the novel action contents with an external knowledge base. Specifically, we first propose using large language models to generate rich descriptions from category names, which leads to a better understanding of unseen categories. Additionally, we propose a distribution alignment loss as well as a knowledge-aware adaptive margin loss to further improve the generalization ability towards unseen categories. Extensive experimental results demonstrate that our proposed KDA can outperform state-of-the-art methods on three popular audio-visual zero-shot learning datasets. Our code will be avaliable at \url{https://github.com/chenhaoxing/KDA}.
Model-Aware Contrastive Learning: Towards Escaping Uniformity-Tolerance Dilemma in Training
Jul 16, 2022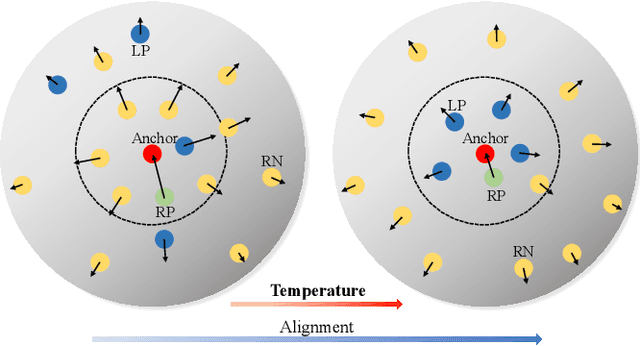
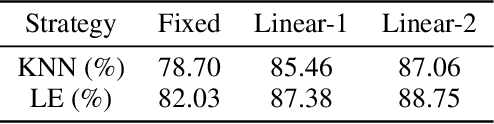

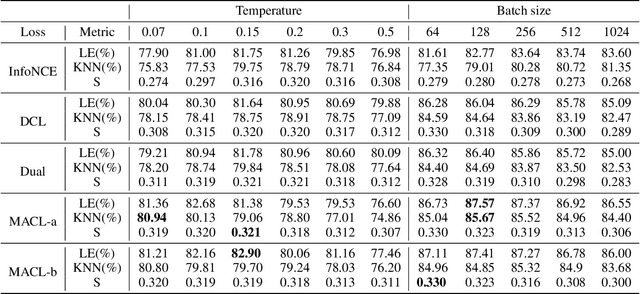
Instance discrimination contrastive learning (CL) has achieved significant success in learning transferable representations. A hardness-aware property related to the temperature $ \tau $ of the CL loss is identified to play an essential role in automatically concentrating on hard negative samples. However, previous work also proves that there exists a uniformity-tolerance dilemma (UTD) in CL loss, which will lead to unexpected performance degradation. Specifically, a smaller temperature helps to learn separable embeddings but has less tolerance to semantically related samples, which may result in suboptimal embedding space, and vice versa. In this paper, we propose a Model-Aware Contrastive Learning (MACL) strategy to escape UTD. For the undertrained phases, there is less possibility that the high similarity region of the anchor contains latent positive samples. Thus, adopting a small temperature in these stages can impose larger penalty strength on hard negative samples to improve the discrimination of the CL model. In contrast, a larger temperature in the well-trained phases helps to explore semantic structures due to more tolerance to potential positive samples. During implementation, the temperature in MACL is designed to be adaptive to the alignment property that reflects the confidence of a CL model. Furthermore, we reexamine why contrastive learning requires a large number of negative samples in a unified gradient reduction perspective. Based on MACL and these analyses, a new CL loss is proposed in this work to improve the learned representations and training with small batch size.