 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhangxuan Gu
Conditional Prototype Rectification Prompt Learning
Apr 15, 2024
Pre-trained large-scale vision-language models (VLMs) have acquired profound understanding of general visual concepts. Recent advancements in efficient transfer learning (ETL) have shown remarkable success in fine-tuning VLMs within the scenario of limited data, introducing only a few parameters to harness task-specific insights from VLMs. Despite significant progress, current leading ETL methods tend to overfit the narrow distributions of base classes seen during training and encounter two primary challenges: (i) only utilizing uni-modal information to modeling task-specific knowledge; and (ii) using costly and time-consuming methods to supplement knowledge. To address these issues, we propose a Conditional Prototype Rectification Prompt Learning (CPR) method to correct the bias of base examples and augment limited data in an effective way. Specifically, we alleviate overfitting on base classes from two aspects. First, each input image acquires knowledge from both textual and visual prototypes, and then generates sample-conditional text tokens. Second, we extract utilizable knowledge from unlabeled data to further refine the prototypes. These two strategies mitigate biases stemming from base classes, yielding a more effective classifier. Extensive experiments on 11 benchmark datasets show that our CPR achieves state-of-the-art performance on both few-shot classification and base-to-new generalization tasks. Our code is avaliable at \url{https://github.com/chenhaoxing/CPR}.
Segment Anything Model Meets Image Harmonization
Dec 20, 2023Image harmonization is a crucial technique in image composition that aims to seamlessly match the background by adjusting the foreground of composite images. Current methods adopt either global-level or pixel-level feature matching. Global-level feature matching ignores the proximity prior, treating foreground and background as separate entities. On the other hand, pixel-level feature matching loses contextual information. Therefore, it is necessary to use the information from semantic maps that describe different objects to guide harmonization. In this paper, we propose Semantic-guided Region-aware Instance Normalization (SRIN) that can utilize the semantic segmentation maps output by a pre-trained Segment Anything Model (SAM) to guide the visual consistency learning of foreground and background features. Abundant experiments demonstrate the superiority of our method for image harmonization over state-of-the-art methods.
Boosting Audio-visual Zero-shot Learning with Large Language Models
Nov 21, 2023Audio-visual zero-shot learning aims to recognize unseen categories based on paired audio-visual sequences. Recent methods mainly focus on learning aligned and discriminative multi-modal features to boost generalization towards unseen categories. However, these approaches ignore the obscure action concepts in category names and may inevitably introduce complex network structures with difficult training objectives. In this paper, we propose a simple yet effective framework named Knowledge-aware Distribution Adaptation (KDA) to help the model better grasp the novel action contents with an external knowledge base. Specifically, we first propose using large language models to generate rich descriptions from category names, which leads to a better understanding of unseen categories. Additionally, we propose a distribution alignment loss as well as a knowledge-aware adaptive margin loss to further improve the generalization ability towards unseen categories. Extensive experimental results demonstrate that our proposed KDA can outperform state-of-the-art methods on three popular audio-visual zero-shot learning datasets. Our code will be avaliable at \url{https://github.com/chenhaoxing/KDA}.
Backpropagation Path Search On Adversarial Transferability
Aug 15, 2023Deep neural networks are vulnerable to adversarial examples, dictating the imperativeness to test the model's robustness before deployment. Transfer-based attackers craft adversarial examples against surrogate models and transfer them to victim models deployed in the black-box situation. To enhance the adversarial transferability, structure-based attackers adjust the backpropagation path to avoid the attack from overfitting the surrogate model. However, existing structure-based attackers fail to explore the convolution module in CNNs and modify the backpropagation graph heuristically, leading to limited effectiveness. In this paper, we propose backPropagation pAth Search (PAS), solving the aforementioned two problems. We first propose SkipConv to adjust the backpropagation path of convolution by structural reparameterization. To overcome the drawback of heuristically designed backpropagation paths, we further construct a DAG-based search space, utilize one-step approximation for path evaluation and employ Bayesian Optimization to search for the optimal path. We conduct comprehensive experiments in a wide range of transfer settings, showing that PAS improves the attack success rate by a huge margin for both normally trained and defense models.
DiffUTE: Universal Text Editing Diffusion Model
May 19, 2023



Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
Mobile User Interface Element Detection Via Adaptively Prompt Tuning
May 16, 2023



Recent object detection approaches rely on pretrained vision-language models for image-text alignment. However, they fail to detect the Mobile User Interface (MUI) element since it contains additional OCR information, which describes its content and function but is often ignored. In this paper, we develop a new MUI element detection dataset named MUI-zh and propose an Adaptively Prompt Tuning (APT) module to take advantage of discriminating OCR information. APT is a lightweight and effective module to jointly optimize category prompts across different modalities. For every element, APT uniformly encodes its visual features and OCR descriptions to dynamically adjust the representation of frozen category prompts. We evaluate the effectiveness of our plug-and-play APT upon several existing CLIP-based detectors for both standard and open-vocabulary MUI element detection. Extensive experiments show that our method achieves considerable improvements on two datasets. The datasets is available at \url{github.com/antmachineintelligence/MUI-zh}.
DiffusionInst: Diffusion Model for Instance Segmentation
Dec 07, 2022



Recently, diffusion frameworks have achieved comparable performance with previous state-of-the-art image generation models. Researchers are curious about its variants in discriminative tasks because of its powerful noise-to-image denoising pipeline. This paper proposes DiffusionInst, a novel framework that represents instances as instance-aware filters and formulates instance segmentation as a noise-to-filter denoising process. The model is trained to reverse the noisy groundtruth without any inductive bias from RPN. During inference, it takes a randomly generated filter as input and outputs mask in one-step or multi-step denoising. Extensive experimental results on COCO and LVIS show that DiffusionInst achieves competitive performance compared to existing instance segmentation models. We hope our work could serve as a simple yet effective baseline, which could inspire designing more efficient diffusion frameworks for challenging discriminative tasks. Our code is available in https://github.com/chenhaoxing/DiffusionInst.
Hierarchical Dynamic Image Harmonization
Nov 16, 2022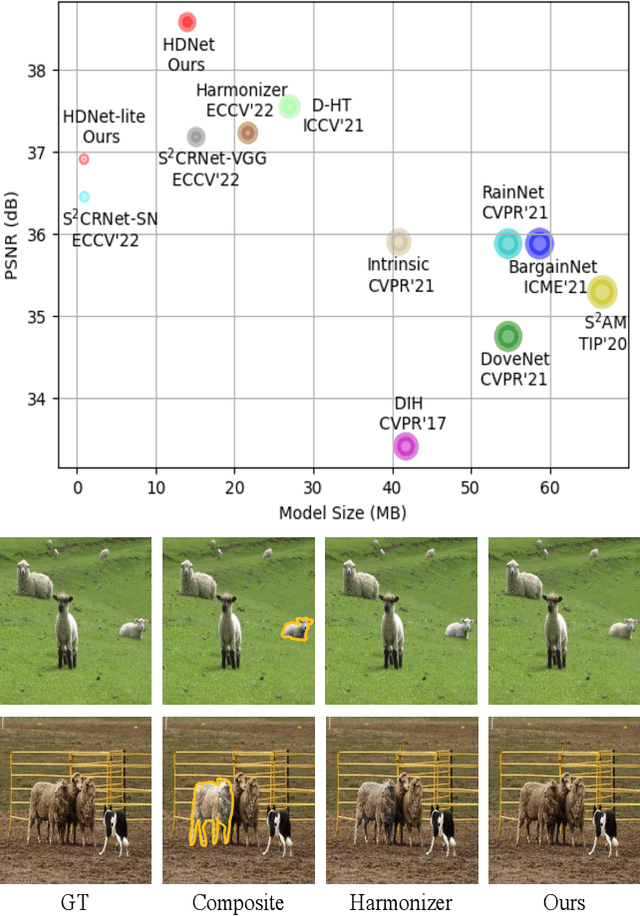
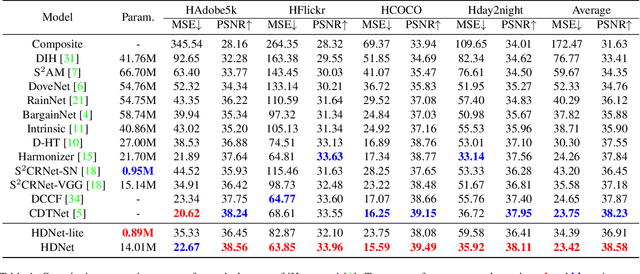
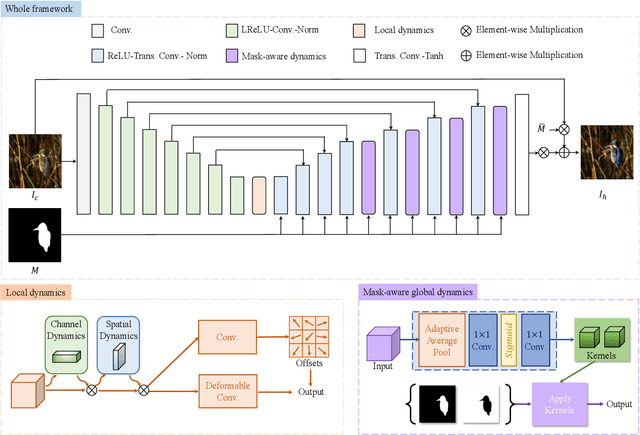
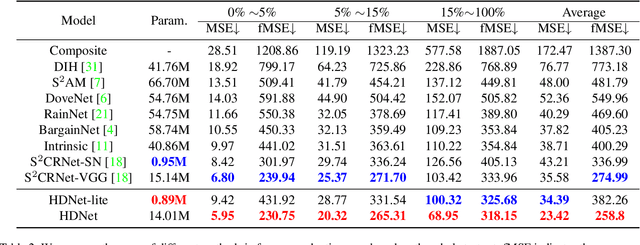
Image harmonization is a critical task in computer vision, which aims to adjust the fore-ground to make it compatible with the back-ground. Recent works mainly focus on using global transformation (i.e., normalization and color curve rendering) to achieve visual consistency. However, these model ignore local consistency and their model size limit their harmonization ability on edge devices. Inspired by the dynamic deep networks that adapt the model structures or parameters conditioned on the inputs, we propose a hierarchical dynamic network (HDNet) for efficient image harmonization to adapt the model parameters and features from local to global view for better feature transformation. Specifically, local dynamics (LD) and mask-aware global dynamics (MGD) are applied. LD enables features of different channels and positions to change adaptively and improve the representation ability of geometric transformation through structural information learning. MGD learns the representations of fore- and back-ground regions and correlations to global harmonization. Experiments show that the proposed HDNet reduces more than 80\% parameters compared with previous methods but still achieves the state-of-the-art performance on the popular iHarmony4 dataset. Our code is avaliable in https://github.com/chenhaoxing/HDNet.
XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding
Mar 15, 2022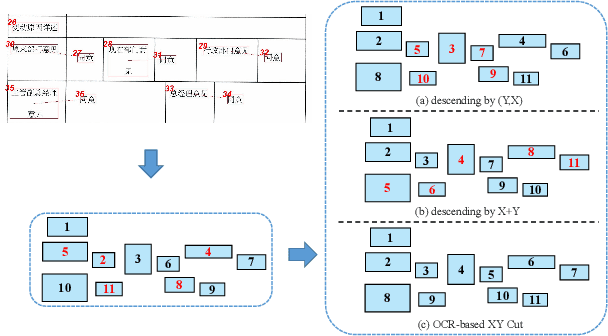
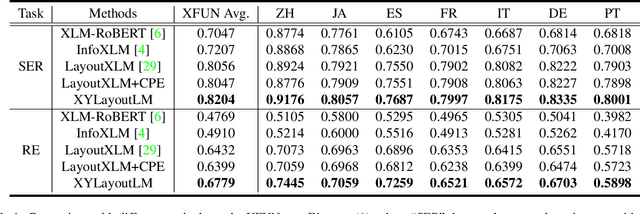
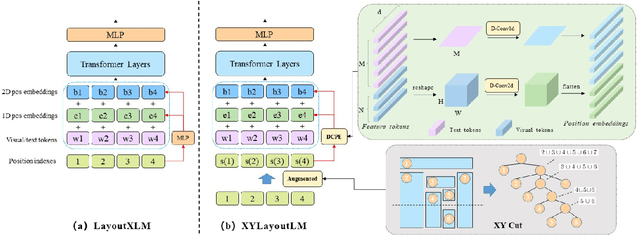
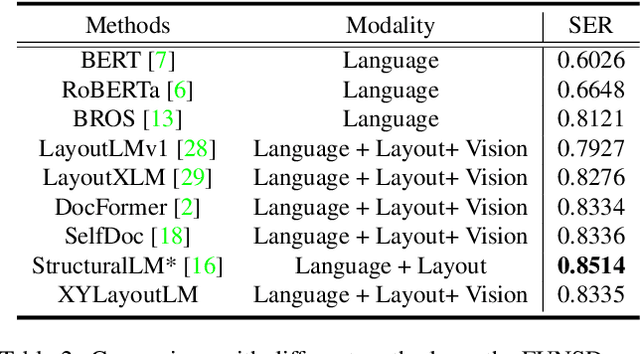
Recently, various multimodal networks for Visually-Rich Document Understanding(VRDU) have been proposed, showing the promotion of transformers by integrating visual and layout information with the text embeddings. However, most existing approaches utilize the position embeddings to incorporate the sequence information, neglecting the noisy improper reading order obtained by OCR tools. In this paper, we propose a robust layout-aware multimodal network named XYLayoutLM to capture and leverage rich layout information from proper reading orders produced by our Augmented XY Cut. Moreover, a Dilated Conditional Position Encoding module is proposed to deal with the input sequence of variable lengths, and it additionally extracts local layout information from both textual and visual modalities while generating position embeddings. Experiment results show that our XYLayoutLM achieves competitive results on document understanding tasks.
STC: Spatio-Temporal Contrastive Learning for Video Instance Segmentation
Feb 08, 2022



Video Instance Segmentation (VIS) is a task that simultaneously requires classification, segmentation, and instance association in a video. Recent VIS approaches rely on sophisticated pipelines to achieve this goal, including RoI-related operations or 3D convolutions. In contrast, we present a simple and efficient single-stage VIS framework based on the instance segmentation method CondInst by adding an extra tracking head. To improve instance association accuracy, a novel bi-directional spatio-temporal contrastive learning strategy for tracking embedding across frames is proposed. Moreover, an instance-wise temporal consistency scheme is utilized to produce temporally coherent results. Experiments conducted on the YouTube-VIS-2019, YouTube-VIS-2021, and OVIS-2021 datasets validate the effectiveness and efficiency of the proposed method. We hope the proposed framework can serve as a simple and strong alternative for many other instance-level video association tasks. Code will be made available.