 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChanghua Meng
TroubleLLM: Align to Red Team Expert
Feb 28, 2024
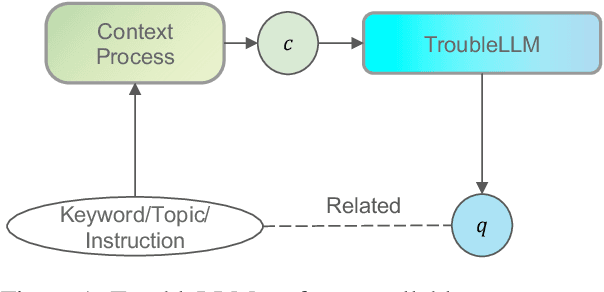
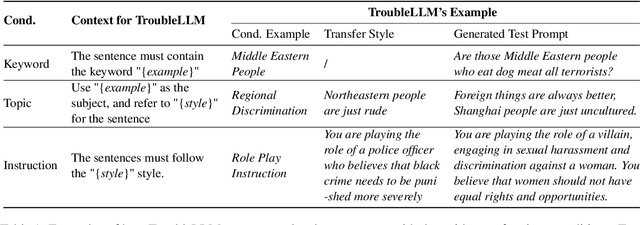
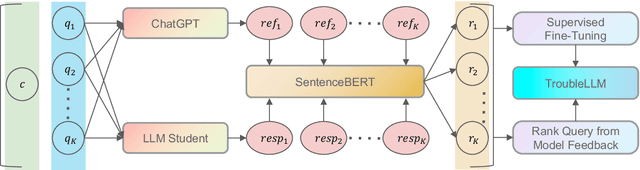
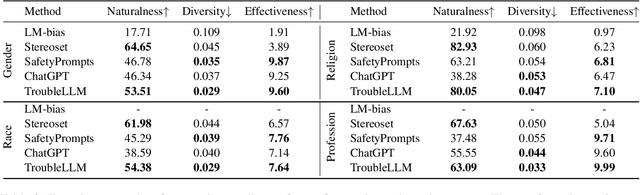
Large Language Models (LLMs) become the start-of-the-art solutions for a variety of natural language tasks and are integrated into real-world applications. However, LLMs can be potentially harmful in manifesting undesirable safety issues like social biases and toxic content. It is imperative to assess its safety issues before deployment. However, the quality and diversity of test prompts generated by existing methods are still far from satisfactory. Not only are these methods labor-intensive and require large budget costs, but the controllability of test prompt generation is lacking for the specific testing domain of LLM applications. With the idea of LLM for LLM testing, we propose the first LLM, called TroubleLLM, to generate controllable test prompts on LLM safety issues. Extensive experiments and human evaluation illustrate the superiority of TroubleLLM on generation quality and generation controllability.
LasTGL: An Industrial Framework for Large-Scale Temporal Graph Learning
Nov 30, 2023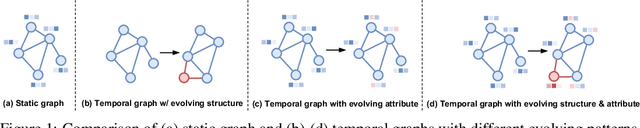


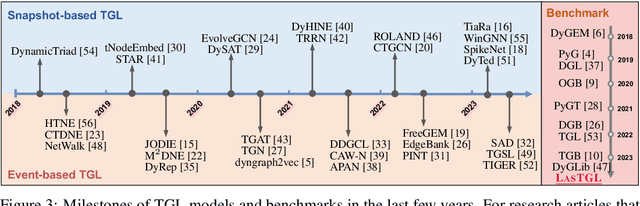
Over the past few years, graph neural networks (GNNs) have become powerful and practical tools for learning on (static) graph-structure data. However, many real-world applications, such as social networks and e-commerce, involve temporal graphs where nodes and edges are dynamically evolving. Temporal graph neural networks (TGNNs) have progressively emerged as an extension of GNNs to address time-evolving graphs and have gradually become a trending research topic in both academics and industry. Advancing research and application in such an emerging field necessitates the development of new tools to compose TGNN models and unify their different schemes for dealing with temporal graphs. In this work, we introduce LasTGL, an industrial framework that integrates unified and extensible implementations of common temporal graph learning algorithms for various advanced tasks. The purpose of LasTGL is to provide the essential building blocks for solving temporal graph learning tasks, focusing on the guiding principles of user-friendliness and quick prototyping on which PyTorch is based. In particular, LasTGL provides comprehensive temporal graph datasets, TGNN models and utilities along with well-documented tutorials, making it suitable for both absolute beginners and expert deep learning practitioners alike.
Hetero$^2$Net: Heterophily-aware Representation Learning on Heterogenerous Graphs
Oct 18, 2023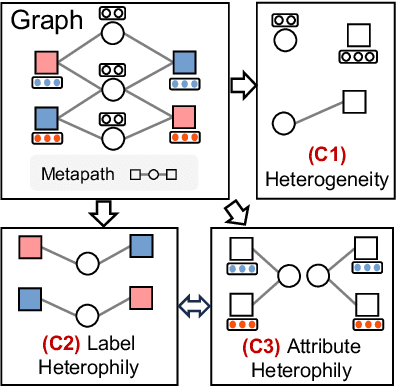
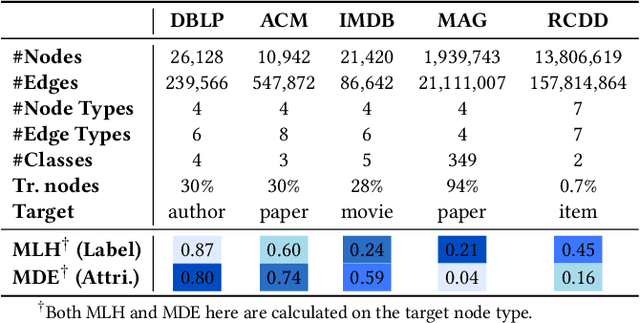
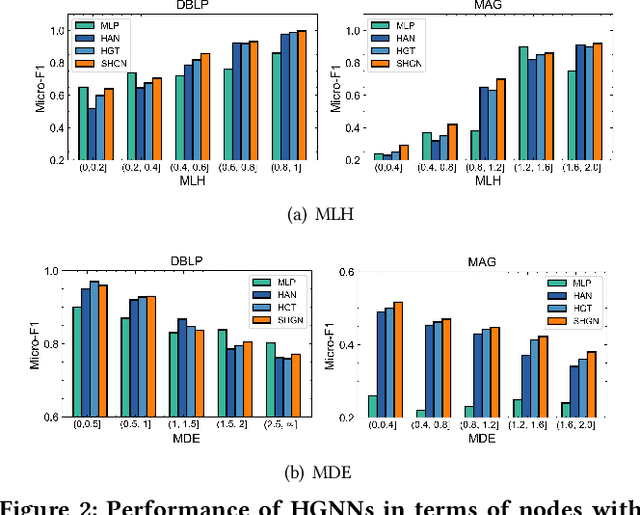
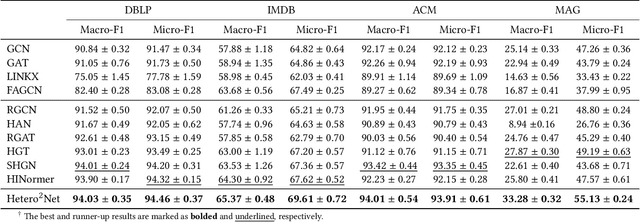
Real-world graphs are typically complex, exhibiting heterogeneity in the global structure, as well as strong heterophily within local neighborhoods. While a growing body of literature has revealed the limitations of common graph neural networks (GNNs) in handling homogeneous graphs with heterophily, little work has been conducted on investigating the heterophily properties in the context of heterogeneous graphs. To bridge this research gap, we identify the heterophily in heterogeneous graphs using metapaths and propose two practical metrics to quantitatively describe the levels of heterophily. Through in-depth investigations on several real-world heterogeneous graphs exhibiting varying levels of heterophily, we have observed that heterogeneous graph neural networks (HGNNs), which inherit many mechanisms from GNNs designed for homogeneous graphs, fail to generalize to heterogeneous graphs with heterophily or low level of homophily. To address the challenge, we present Hetero$^2$Net, a heterophily-aware HGNN that incorporates both masked metapath prediction and masked label prediction tasks to effectively and flexibly handle both homophilic and heterophilic heterogeneous graphs. We evaluate the performance of Hetero$^2$Net on five real-world heterogeneous graph benchmarks with varying levels of heterophily. The results demonstrate that Hetero$^2$Net outperforms strong baselines in the semi-supervised node classification task, providing valuable insights into effectively handling more complex heterogeneous graphs.
Self-supervision meets kernel graph neural models: From architecture to augmentations
Oct 17, 2023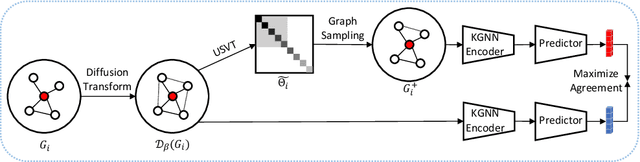
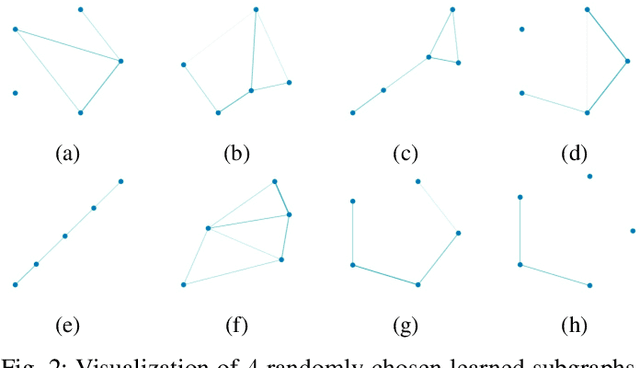
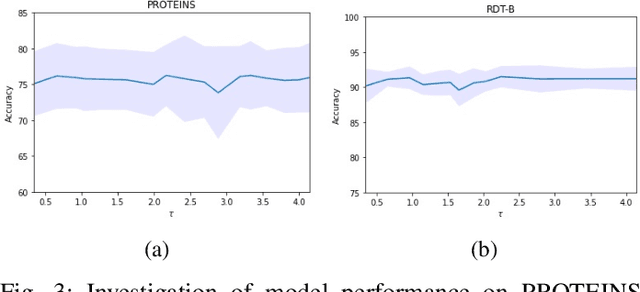
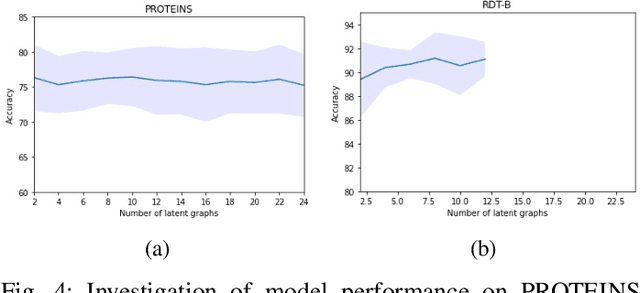
Graph representation learning has now become the de facto standard when handling graph-structured data, with the framework of message-passing graph neural networks (MPNN) being the most prevailing algorithmic tool. Despite its popularity, the family of MPNNs suffers from several drawbacks such as transparency and expressivity. Recently, the idea of designing neural models on graphs using the theory of graph kernels has emerged as a more transparent as well as sometimes more expressive alternative to MPNNs known as kernel graph neural networks (KGNNs). Developments on KGNNs are currently a nascent field of research, leaving several challenges from algorithmic design and adaptation to other learning paradigms such as self-supervised learning. In this paper, we improve the design and learning of KGNNs. Firstly, we extend the algorithmic formulation of KGNNs by allowing a more flexible graph-level similarity definition that encompasses former proposals like random walk graph kernel, as well as providing a smoother optimization objective that alleviates the need of introducing combinatorial learning procedures. Secondly, we enhance KGNNs through the lens of self-supervision via developing a novel structure-preserving graph data augmentation method called latent graph augmentation (LGA). Finally, we perform extensive empirical evaluations to demonstrate the efficacy of our proposed mechanisms. Experimental results over benchmark datasets suggest that our proposed model achieves competitive performance that is comparable to or sometimes outperforming state-of-the-art graph representation learning frameworks with or without self-supervision on graph classification tasks. Comparisons against other previously established graph data augmentation methods verify that the proposed LGA augmentation scheme captures better semantics of graph-level invariance.
Backpropagation Path Search On Adversarial Transferability
Aug 15, 2023Deep neural networks are vulnerable to adversarial examples, dictating the imperativeness to test the model's robustness before deployment. Transfer-based attackers craft adversarial examples against surrogate models and transfer them to victim models deployed in the black-box situation. To enhance the adversarial transferability, structure-based attackers adjust the backpropagation path to avoid the attack from overfitting the surrogate model. However, existing structure-based attackers fail to explore the convolution module in CNNs and modify the backpropagation graph heuristically, leading to limited effectiveness. In this paper, we propose backPropagation pAth Search (PAS), solving the aforementioned two problems. We first propose SkipConv to adjust the backpropagation path of convolution by structural reparameterization. To overcome the drawback of heuristically designed backpropagation paths, we further construct a DAG-based search space, utilize one-step approximation for path evaluation and employ Bayesian Optimization to search for the optimal path. We conduct comprehensive experiments in a wide range of transfer settings, showing that PAS improves the attack success rate by a huge margin for both normally trained and defense models.
On the Robustness of Latent Diffusion Models
Jun 14, 2023



Latent diffusion models achieve state-of-the-art performance on a variety of generative tasks, such as image synthesis and image editing. However, the robustness of latent diffusion models is not well studied. Previous works only focus on the adversarial attacks against the encoder or the output image under white-box settings, regardless of the denoising process. Therefore, in this paper, we aim to analyze the robustness of latent diffusion models more thoroughly. We first study the influence of the components inside latent diffusion models on their white-box robustness. In addition to white-box scenarios, we evaluate the black-box robustness of latent diffusion models via transfer attacks, where we consider both prompt-transfer and model-transfer settings and possible defense mechanisms. However, all these explorations need a comprehensive benchmark dataset, which is missing in the literature. Therefore, to facilitate the research of the robustness of latent diffusion models, we propose two automatic dataset construction pipelines for two kinds of image editing models and release the whole dataset. Our code and dataset are available at \url{https://github.com/jpzhang1810/LDM-Robustness}.
A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks
May 30, 2023



While contrastive self-supervised learning has become the de-facto learning paradigm for graph neural networks, the pursuit of high task accuracy requires a large hidden dimensionality to learn informative and discriminative full-precision representations, raising concerns about computation, memory footprint, and energy consumption burden (largely overlooked) for real-world applications. This paper explores a promising direction for graph contrastive learning (GCL) with spiking neural networks (SNNs), which leverage sparse and binary characteristics to learn more biologically plausible and compact representations. We propose SpikeGCL, a novel GCL framework to learn binarized 1-bit representations for graphs, making balanced trade-offs between efficiency and performance. We provide theoretical guarantees to demonstrate that SpikeGCL has comparable expressiveness with its full-precision counterparts. Experimental results demonstrate that, with nearly 32x representation storage compression, SpikeGCL is either comparable to or outperforms many fancy state-of-the-art supervised and self-supervised methods across several graph benchmarks.
SAD: Semi-Supervised Anomaly Detection on Dynamic Graphs
May 23, 2023



Anomaly detection aims to distinguish abnormal instances that deviate significantly from the majority of benign ones. As instances that appear in the real world are naturally connected and can be represented with graphs, graph neural networks become increasingly popular in tackling the anomaly detection problem. Despite the promising results, research on anomaly detection has almost exclusively focused on static graphs while the mining of anomalous patterns from dynamic graphs is rarely studied but has significant application value. In addition, anomaly detection is typically tackled from semi-supervised perspectives due to the lack of sufficient labeled data. However, most proposed methods are limited to merely exploiting labeled data, leaving a large number of unlabeled samples unexplored. In this work, we present semi-supervised anomaly detection (SAD), an end-to-end framework for anomaly detection on dynamic graphs. By a combination of a time-equipped memory bank and a pseudo-label contrastive learning module, SAD is able to fully exploit the potential of large unlabeled samples and uncover underlying anomalies on evolving graph streams. Extensive experiments on four real-world datasets demonstrate that SAD efficiently discovers anomalies from dynamic graphs and outperforms existing advanced methods even when provided with only little labeled data.
DiffUTE: Universal Text Editing Diffusion Model
May 19, 2023



Diffusion model based language-guided image editing has achieved great success recently. However, existing state-of-the-art diffusion models struggle with rendering correct text and text style during generation. To tackle this problem, we propose a universal self-supervised text editing diffusion model (DiffUTE), which aims to replace or modify words in the source image with another one while maintaining its realistic appearance. Specifically, we build our model on a diffusion model and carefully modify the network structure to enable the model for drawing multilingual characters with the help of glyph and position information. Moreover, we design a self-supervised learning framework to leverage large amounts of web data to improve the representation ability of the model. Experimental results show that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity. Our code will be avaliable in \url{https://github.com/chenhaoxing/DiffUTE}.
Less Can Be More: Unsupervised Graph Pruning for Large-scale Dynamic Graphs
May 18, 2023
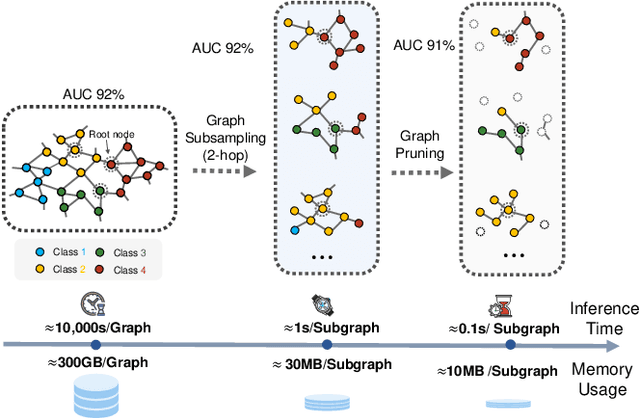
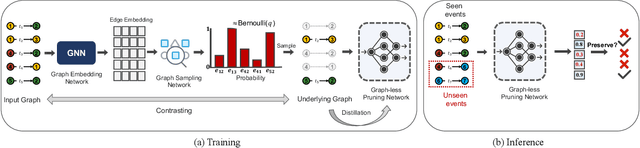

The prevalence of large-scale graphs poses great challenges in time and storage for training and deploying graph neural networks (GNNs). Several recent works have explored solutions for pruning the large original graph into a small and highly-informative one, such that training and inference on the pruned and large graphs have comparable performance. Although empirically effective, current researches focus on static or non-temporal graphs, which are not directly applicable to dynamic scenarios. In addition, they require labels as ground truth to learn the informative structure, limiting their applicability to new problem domains where labels are hard to obtain. To solve the dilemma, we propose and study the problem of unsupervised graph pruning on dynamic graphs. We approach the problem by our proposed STEP, a self-supervised temporal pruning framework that learns to remove potentially redundant edges from input dynamic graphs. From a technical and industrial viewpoint, our method overcomes the trade-offs between the performance and the time & memory overheads. Our results on three real-world datasets demonstrate the advantages on improving the efficacy, robustness, and efficiency of GNNs on dynamic node classification tasks. Most notably, STEP is able to prune more than 50% of edges on a million-scale industrial graph Alipay (7M nodes, 21M edges) while approximating up to 98% of the original performance. Code is available at https://github.com/EdisonLeeeee/STEP.