 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJintang Li
SGHormer: An Energy-Saving Graph Transformer Driven by Spikes
Mar 26, 2024
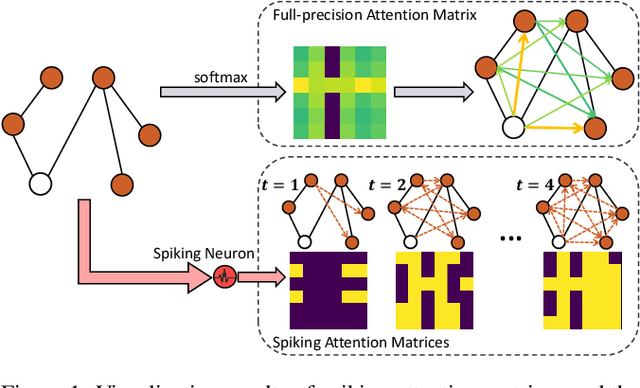
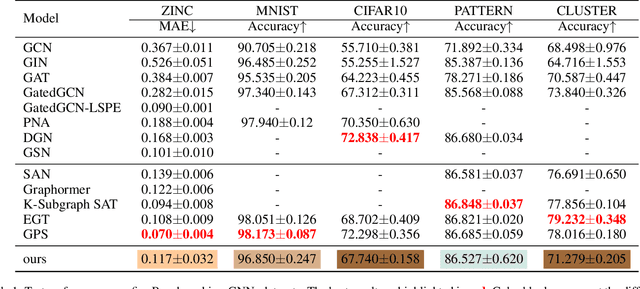
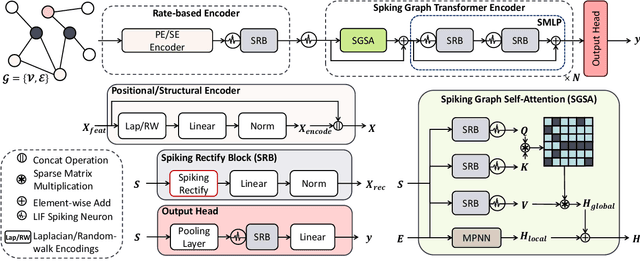
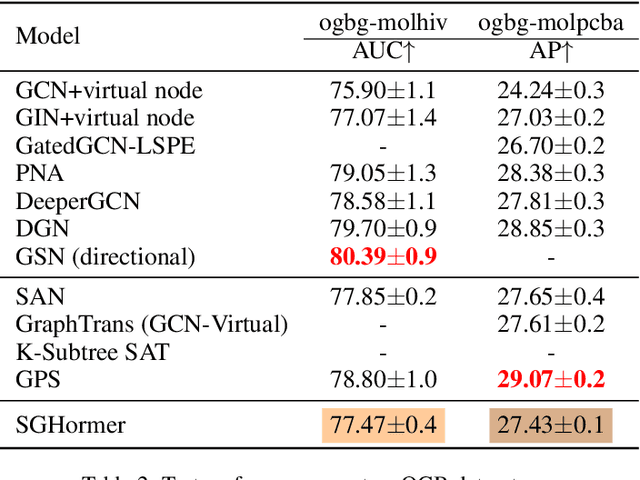
Graph Transformers (GTs) with powerful representation learning ability make a huge success in wide range of graph tasks. However, the costs behind outstanding performances of GTs are higher energy consumption and computational overhead. The complex structure and quadratic complexity during attention calculation in vanilla transformer seriously hinder its scalability on the large-scale graph data. Though existing methods have made strides in simplifying combinations among blocks or attention-learning paradigm to improve GTs' efficiency, a series of energy-saving solutions originated from biologically plausible structures are rarely taken into consideration when constructing GT framework. To this end, we propose a new spiking-based graph transformer (SGHormer). It turns full-precision embeddings into sparse and binarized spikes to reduce memory and computational costs. The spiking graph self-attention and spiking rectify blocks in SGHormer explicitly capture global structure information and recover the expressive power of spiking embeddings, respectively. In experiments, SGHormer achieves comparable performances to other full-precision GTs with extremely low computational energy consumption. The results show that SGHomer makes a remarkable progress in the field of low-energy GTs.
Rethinking and Simplifying Bootstrapped Graph Latents
Dec 05, 2023Graph contrastive learning (GCL) has emerged as a representative paradigm in graph self-supervised learning, where negative samples are commonly regarded as the key to preventing model collapse and producing distinguishable representations. Recent studies have shown that GCL without negative samples can achieve state-of-the-art performance as well as scalability improvement, with bootstrapped graph latent (BGRL) as a prominent step forward. However, BGRL relies on a complex architecture to maintain the ability to scatter representations, and the underlying mechanisms enabling the success remain largely unexplored. In this paper, we introduce an instance-level decorrelation perspective to tackle the aforementioned issue and leverage it as a springboard to reveal the potential unnecessary model complexity within BGRL. Based on our findings, we present SGCL, a simple yet effective GCL framework that utilizes the outputs from two consecutive iterations as positive pairs, eliminating the negative samples. SGCL only requires a single graph augmentation and a single graph encoder without additional parameters. Extensive experiments conducted on various graph benchmarks demonstrate that SGCL can achieve competitive performance with fewer parameters, lower time and space costs, and significant convergence speedup.
LasTGL: An Industrial Framework for Large-Scale Temporal Graph Learning
Nov 30, 2023


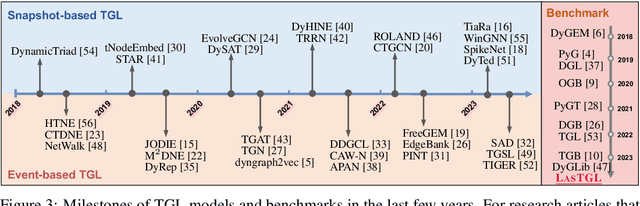
Over the past few years, graph neural networks (GNNs) have become powerful and practical tools for learning on (static) graph-structure data. However, many real-world applications, such as social networks and e-commerce, involve temporal graphs where nodes and edges are dynamically evolving. Temporal graph neural networks (TGNNs) have progressively emerged as an extension of GNNs to address time-evolving graphs and have gradually become a trending research topic in both academics and industry. Advancing research and application in such an emerging field necessitates the development of new tools to compose TGNN models and unify their different schemes for dealing with temporal graphs. In this work, we introduce LasTGL, an industrial framework that integrates unified and extensible implementations of common temporal graph learning algorithms for various advanced tasks. The purpose of LasTGL is to provide the essential building blocks for solving temporal graph learning tasks, focusing on the guiding principles of user-friendliness and quick prototyping on which PyTorch is based. In particular, LasTGL provides comprehensive temporal graph datasets, TGNN models and utilities along with well-documented tutorials, making it suitable for both absolute beginners and expert deep learning practitioners alike.
The Devil is in the Data: Learning Fair Graph Neural Networks via Partial Knowledge Distillation
Nov 29, 2023Graph neural networks (GNNs) are being increasingly used in many high-stakes tasks, and as a result, there is growing attention on their fairness recently. GNNs have been shown to be unfair as they tend to make discriminatory decisions toward certain demographic groups, divided by sensitive attributes such as gender and race. While recent works have been devoted to improving their fairness performance, they often require accessible demographic information. This greatly limits their applicability in real-world scenarios due to legal restrictions. To address this problem, we present a demographic-agnostic method to learn fair GNNs via knowledge distillation, namely FairGKD. Our work is motivated by the empirical observation that training GNNs on partial data (i.e., only node attributes or topology data) can improve their fairness, albeit at the cost of utility. To make a balanced trade-off between fairness and utility performance, we employ a set of fairness experts (i.e., GNNs trained on different partial data) to construct the synthetic teacher, which distills fairer and informative knowledge to guide the learning of the GNN student. Experiments on several benchmark datasets demonstrate that FairGKD, which does not require access to demographic information, significantly improves the fairness of GNNs by a large margin while maintaining their utility.
Hetero$^2$Net: Heterophily-aware Representation Learning on Heterogenerous Graphs
Oct 18, 2023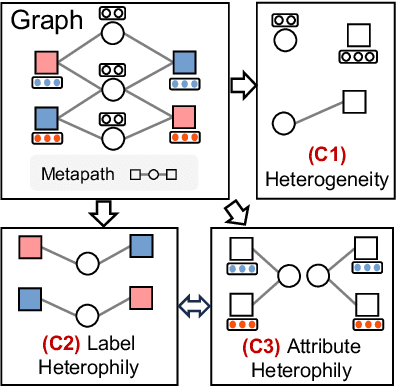
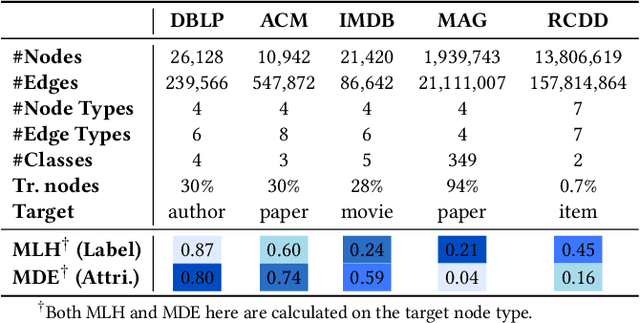
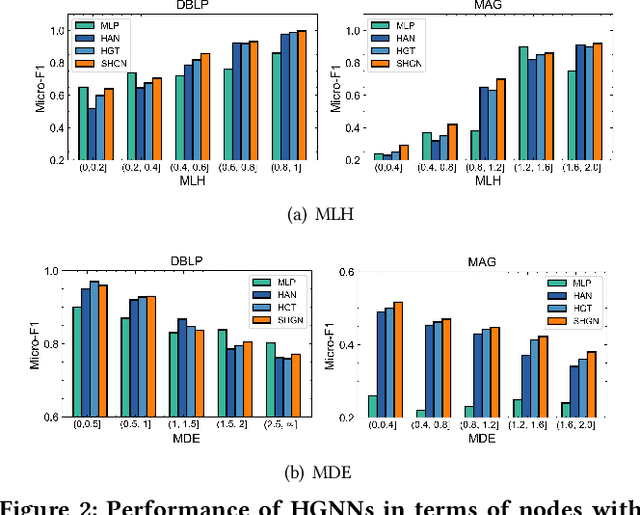
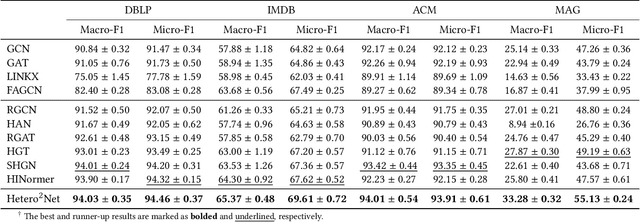
Real-world graphs are typically complex, exhibiting heterogeneity in the global structure, as well as strong heterophily within local neighborhoods. While a growing body of literature has revealed the limitations of common graph neural networks (GNNs) in handling homogeneous graphs with heterophily, little work has been conducted on investigating the heterophily properties in the context of heterogeneous graphs. To bridge this research gap, we identify the heterophily in heterogeneous graphs using metapaths and propose two practical metrics to quantitatively describe the levels of heterophily. Through in-depth investigations on several real-world heterogeneous graphs exhibiting varying levels of heterophily, we have observed that heterogeneous graph neural networks (HGNNs), which inherit many mechanisms from GNNs designed for homogeneous graphs, fail to generalize to heterogeneous graphs with heterophily or low level of homophily. To address the challenge, we present Hetero$^2$Net, a heterophily-aware HGNN that incorporates both masked metapath prediction and masked label prediction tasks to effectively and flexibly handle both homophilic and heterophilic heterogeneous graphs. We evaluate the performance of Hetero$^2$Net on five real-world heterogeneous graph benchmarks with varying levels of heterophily. The results demonstrate that Hetero$^2$Net outperforms strong baselines in the semi-supervised node classification task, providing valuable insights into effectively handling more complex heterogeneous graphs.
SAILOR: Structural Augmentation Based Tail Node Representation Learning
Aug 15, 2023



Graph Neural Networks (GNNs) have achieved state-of-the-art performance in representation learning for graphs recently. However, the effectiveness of GNNs, which capitalize on the key operation of message propagation, highly depends on the quality of the topology structure. Most of the graphs in real-world scenarios follow a long-tailed distribution on their node degrees, that is, a vast majority of the nodes in the graph are tail nodes with only a few connected edges. GNNs produce inferior node representations for tail nodes since they lack structural information. In the pursuit of promoting the expressiveness of GNNs for tail nodes, we explore how the deficiency of structural information deteriorates the performance of tail nodes and propose a general Structural Augmentation based taIL nOde Representation learning framework, dubbed as SAILOR, which can jointly learn to augment the graph structure and extract more informative representations for tail nodes. Extensive experiments on public benchmark datasets demonstrate that SAILOR can significantly improve the tail node representations and outperform the state-of-the-art baselines.
Scaling Up, Scaling Deep: Blockwise Graph Contrastive Learning
Jun 03, 2023



Oversmoothing is a common phenomenon in graph neural networks (GNNs), in which an increase in the network depth leads to a deterioration in their performance. Graph contrastive learning (GCL) is emerging as a promising way of leveraging vast unlabeled graph data. As a marriage between GNNs and contrastive learning, it remains unclear whether GCL inherits the same oversmoothing defect from GNNs. This work undertakes a fundamental analysis of GCL from the perspective of oversmoothing on the first hand. We demonstrate empirically that increasing network depth in GCL also leads to oversmoothing in their deep representations, and surprisingly, the shallow ones. We refer to this phenomenon in GCL as long-range starvation', wherein lower layers in deep networks suffer from degradation due to the lack of sufficient guidance from supervision (e.g., loss computing). Based on our findings, we present BlockGCL, a remarkably simple yet effective blockwise training framework to prevent GCL from notorious oversmoothing. Without bells and whistles, BlockGCL consistently improves robustness and stability for well-established GCL methods with increasing numbers of layers on real-world graph benchmarks. We believe our work will provide insights for future improvements of scalable and deep GCL frameworks.
A Graph is Worth 1-bit Spikes: When Graph Contrastive Learning Meets Spiking Neural Networks
May 30, 2023



While contrastive self-supervised learning has become the de-facto learning paradigm for graph neural networks, the pursuit of high task accuracy requires a large hidden dimensionality to learn informative and discriminative full-precision representations, raising concerns about computation, memory footprint, and energy consumption burden (largely overlooked) for real-world applications. This paper explores a promising direction for graph contrastive learning (GCL) with spiking neural networks (SNNs), which leverage sparse and binary characteristics to learn more biologically plausible and compact representations. We propose SpikeGCL, a novel GCL framework to learn binarized 1-bit representations for graphs, making balanced trade-offs between efficiency and performance. We provide theoretical guarantees to demonstrate that SpikeGCL has comparable expressiveness with its full-precision counterparts. Experimental results demonstrate that, with nearly 32x representation storage compression, SpikeGCL is either comparable to or outperforms many fancy state-of-the-art supervised and self-supervised methods across several graph benchmarks.
SAD: Semi-Supervised Anomaly Detection on Dynamic Graphs
May 23, 2023



Anomaly detection aims to distinguish abnormal instances that deviate significantly from the majority of benign ones. As instances that appear in the real world are naturally connected and can be represented with graphs, graph neural networks become increasingly popular in tackling the anomaly detection problem. Despite the promising results, research on anomaly detection has almost exclusively focused on static graphs while the mining of anomalous patterns from dynamic graphs is rarely studied but has significant application value. In addition, anomaly detection is typically tackled from semi-supervised perspectives due to the lack of sufficient labeled data. However, most proposed methods are limited to merely exploiting labeled data, leaving a large number of unlabeled samples unexplored. In this work, we present semi-supervised anomaly detection (SAD), an end-to-end framework for anomaly detection on dynamic graphs. By a combination of a time-equipped memory bank and a pseudo-label contrastive learning module, SAD is able to fully exploit the potential of large unlabeled samples and uncover underlying anomalies on evolving graph streams. Extensive experiments on four real-world datasets demonstrate that SAD efficiently discovers anomalies from dynamic graphs and outperforms existing advanced methods even when provided with only little labeled data.
Less Can Be More: Unsupervised Graph Pruning for Large-scale Dynamic Graphs
May 18, 2023
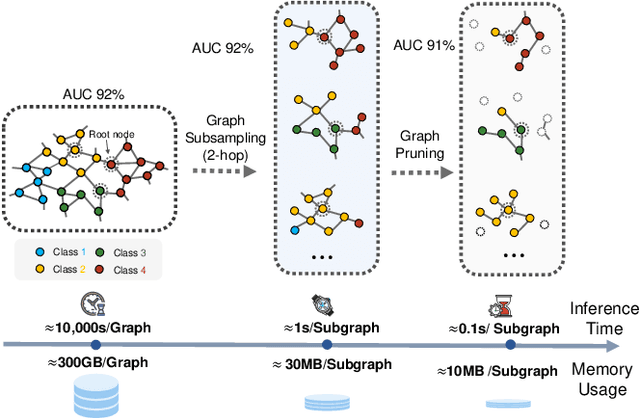
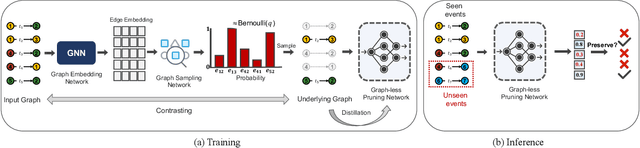

The prevalence of large-scale graphs poses great challenges in time and storage for training and deploying graph neural networks (GNNs). Several recent works have explored solutions for pruning the large original graph into a small and highly-informative one, such that training and inference on the pruned and large graphs have comparable performance. Although empirically effective, current researches focus on static or non-temporal graphs, which are not directly applicable to dynamic scenarios. In addition, they require labels as ground truth to learn the informative structure, limiting their applicability to new problem domains where labels are hard to obtain. To solve the dilemma, we propose and study the problem of unsupervised graph pruning on dynamic graphs. We approach the problem by our proposed STEP, a self-supervised temporal pruning framework that learns to remove potentially redundant edges from input dynamic graphs. From a technical and industrial viewpoint, our method overcomes the trade-offs between the performance and the time & memory overheads. Our results on three real-world datasets demonstrate the advantages on improving the efficacy, robustness, and efficiency of GNNs on dynamic node classification tasks. Most notably, STEP is able to prune more than 50% of edges on a million-scale industrial graph Alipay (7M nodes, 21M edges) while approximating up to 98% of the original performance. Code is available at https://github.com/EdisonLeeeee/STEP.