 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Wang
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Apr 18, 2024
We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at \href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
TMPQ-DM: Joint Timestep Reduction and Quantization Precision Selection for Efficient Diffusion Models
Apr 15, 2024Diffusion models have emerged as preeminent contenders in the realm of generative models. Distinguished by their distinctive sequential generative processes, characterized by hundreds or even thousands of timesteps, diffusion models progressively reconstruct images from pure Gaussian noise, with each timestep necessitating full inference of the entire model. However, the substantial computational demands inherent to these models present challenges for deployment, quantization is thus widely used to lower the bit-width for reducing the storage and computing overheads. Current quantization methodologies primarily focus on model-side optimization, disregarding the temporal dimension, such as the length of the timestep sequence, thereby allowing redundant timesteps to continue consuming computational resources, leaving substantial scope for accelerating the generative process. In this paper, we introduce TMPQ-DM, which jointly optimizes timestep reduction and quantization to achieve a superior performance-efficiency trade-off, addressing both temporal and model optimization aspects. For timestep reduction, we devise a non-uniform grouping scheme tailored to the non-uniform nature of the denoising process, thereby mitigating the explosive combinations of timesteps. In terms of quantization, we adopt a fine-grained layer-wise approach to allocate varying bit-widths to different layers based on their respective contributions to the final generative performance, thus rectifying performance degradation observed in prior studies. To expedite the evaluation of fine-grained quantization, we further devise a super-network to serve as a precision solver by leveraging shared quantization results. These two design components are seamlessly integrated within our framework, enabling rapid joint exploration of the exponentially large decision space via a gradient-free evolutionary search algorithm.
BAMBOO: a predictive and transferable machine learning force field framework for liquid electrolyte development
Apr 12, 2024Despite the widespread applications of machine learning force field (MLFF) on solids and small molecules, there is a notable gap in applying MLFF to complex liquid electrolytes. In this work, we introduce BAMBOO (ByteDance AI Molecular Simulation Booster), a novel framework for molecular dynamics (MD) simulations, with a demonstration of its capabilities in the context of liquid electrolytes for lithium batteries. We design a physics-inspired graph equivariant transformer architecture as the backbone of BAMBOO to learn from quantum mechanical simulations. Additionally, we pioneer an ensemble knowledge distillation approach and apply it on MLFFs to improve the stability of MD simulations. Finally, we propose the density alignment algorithm to align BAMBOO with experimental measurements. BAMBOO demonstrates state-of-the-art accuracy in predicting key electrolyte properties such as density, viscosity, and ionic conductivity across various solvents and salt combinations. Our current model, trained on more than 15 chemical species, achieves the average density error of 0.01 g/cm$^3$ on various compositions compared with experimental data. Moreover, our model demonstrates transferability to molecules not included in the quantum mechanical dataset. We envision this work as paving the way to a "universal MLFF" capable of simulating properties of common organic liquids.
Investigating the Impact of Quantization on Adversarial Robustness
Apr 08, 2024Quantization is a promising technique for reducing the bit-width of deep models to improve their runtime performance and storage efficiency, and thus becomes a fundamental step for deployment. In real-world scenarios, quantized models are often faced with adversarial attacks which cause the model to make incorrect inferences by introducing slight perturbations. However, recent studies have paid less attention to the impact of quantization on the model robustness. More surprisingly, existing studies on this topic even present inconsistent conclusions, which prompted our in-depth investigation. In this paper, we conduct a first-time analysis of the impact of the quantization pipeline components that can incorporate robust optimization under the settings of Post-Training Quantization and Quantization-Aware Training. Through our detailed analysis, we discovered that this inconsistency arises from the use of different pipelines in different studies, specifically regarding whether robust optimization is performed and at which quantization stage it occurs. Our research findings contribute insights into deploying more secure and robust quantized networks, assisting practitioners in reference for scenarios with high-security requirements and limited resources.
Metric Learning from Limited Pairwise Preference Comparisons
Mar 28, 2024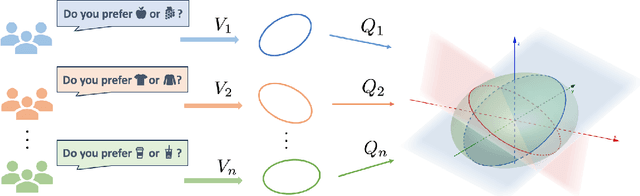
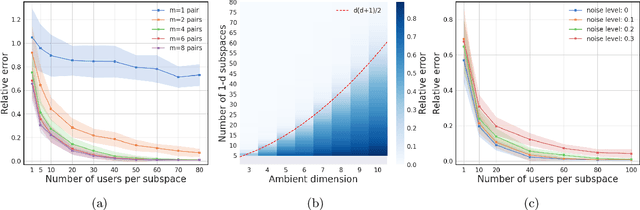
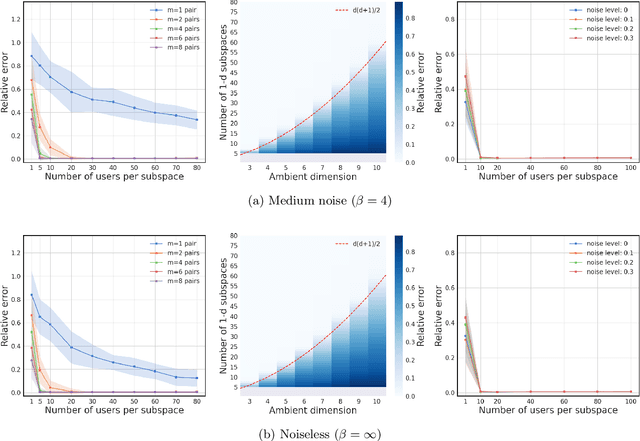
We study metric learning from preference comparisons under the ideal point model, in which a user prefers an item over another if it is closer to their latent ideal item. These items are embedded into $\mathbb{R}^d$ equipped with an unknown Mahalanobis distance shared across users. While recent work shows that it is possible to simultaneously recover the metric and ideal items given $\mathcal{O}(d)$ pairwise comparisons per user, in practice we often have a limited budget of $o(d)$ comparisons. We study whether the metric can still be recovered, even though it is known that learning individual ideal items is now no longer possible. We show that in general, $o(d)$ comparisons reveals no information about the metric, even with infinitely many users. However, when comparisons are made over items that exhibit low-dimensional structure, each user can contribute to learning the metric restricted to a low-dimensional subspace so that the metric can be jointly identified. We present a divide-and-conquer approach that achieves this, and provide theoretical recovery guarantees and empirical validation.
MamMIL: Multiple Instance Learning for Whole Slide Images with State Space Models
Mar 08, 2024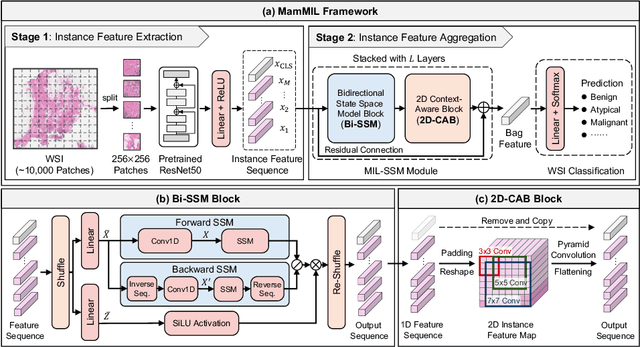
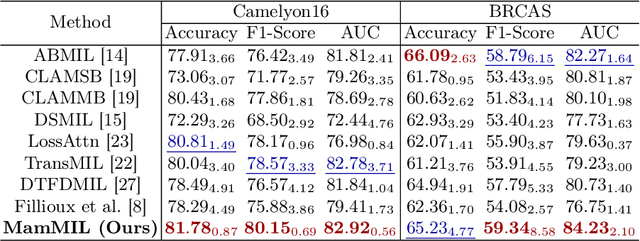
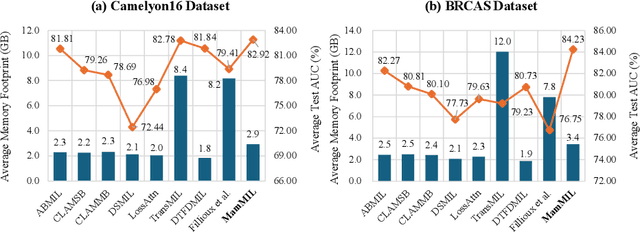
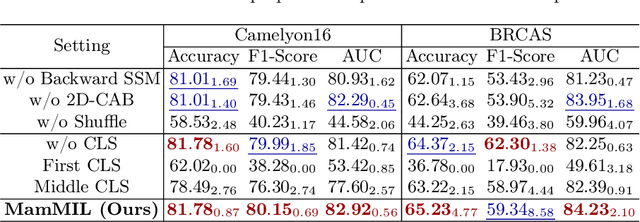
Recently, pathological diagnosis, the gold standard for cancer diagnosis, has achieved superior performance by combining the Transformer with the multiple instance learning (MIL) framework using whole slide images (WSIs). However, the giga-pixel nature of WSIs poses a great challenge for the quadratic-complexity self-attention mechanism in Transformer to be applied in MIL. Existing studies usually use linear attention to improve computing efficiency but inevitably bring performance bottlenecks. To tackle this challenge, we propose a MamMIL framework for WSI classification by cooperating the selective structured state space model (i.e., Mamba) with MIL for the first time, enabling the modeling of instance dependencies while maintaining linear complexity. Specifically, to solve the problem that Mamba can only conduct unidirectional one-dimensional (1D) sequence modeling, we innovatively introduce a bidirectional state space model and a 2D context-aware block to enable MamMIL to learn the bidirectional instance dependencies with 2D spatial relationships. Experiments on two datasets show that MamMIL can achieve advanced classification performance with smaller memory footprints than the state-of-the-art MIL frameworks based on the Transformer. The code will be open-sourced if accepted.
Large Language Model Adaptation for Networking
Feb 04, 2024Many networking tasks now employ deep learning (DL) to solve complex prediction and system optimization problems. However, current design philosophy of DL-based algorithms entails intensive engineering overhead due to the manual design of deep neural networks (DNNs) for different networking tasks. Besides, DNNs tend to achieve poor generalization performance on unseen data distributions/environments. Motivated by the recent success of large language models (LLMs), for the first time, this work studies the LLM adaptation for networking to explore a more sustainable design philosophy. With the massive pre-trained knowledge and powerful inference ability, LLM can serve as the foundation model, and is expected to achieve "one model for all" with even better performance and stronger generalization for various tasks. In this paper, we present NetLLM, the first LLM adaptation framework that efficiently adapts LLMs to solve networking problems. NetLLM addresses many practical challenges in LLM adaptation, from how to process task-specific information with LLMs, to how to improve the efficiency of answer generation and acquiring domain knowledge for networking. Across three networking-related use cases - viewport prediction (VP), adaptive bitrate streaming (ABR) and cluster job scheduling (CJS), we showcase the effectiveness of NetLLM in LLM adaptation for networking. Results show that the adapted LLM surpasses state-of-the-art algorithms by 10.1-36.6% for VP, 14.5-36.6% for ABR, 6.8-41.3% for CJS, and also achieves superior generalization performance.
Retraining-free Model Quantization via One-Shot Weight-Coupling Learning
Jan 03, 2024Quantization is of significance for compressing the over-parameterized deep neural models and deploying them on resource-limited devices. Fixed-precision quantization suffers from performance drop due to the limited numerical representation ability. Conversely, mixed-precision quantization (MPQ) is advocated to compress the model effectively by allocating heterogeneous bit-width for layers. MPQ is typically organized into a searching-retraining two-stage process. Previous works only focus on determining the optimal bit-width configuration in the first stage efficiently, while ignoring the considerable time costs in the second stage. However, retraining always consumes hundreds of GPU-hours on the cutting-edge GPUs, thus hindering deployment efficiency significantly. In this paper, we devise a one-shot training-searching paradigm for mixed-precision model compression. Specifically, in the first stage, all potential bit-width configurations are coupled and thus optimized simultaneously within a set of shared weights. However, our observations reveal a previously unseen and severe bit-width interference phenomenon among highly coupled weights during optimization, leading to considerable performance degradation under a high compression ratio. To tackle this problem, we first design a bit-width scheduler to dynamically freeze the most turbulent bit-width of layers during training, to ensure the rest bit-widths converged properly. Then, taking inspiration from information theory, we present an information distortion mitigation technique to align the behaviour of the bad-performing bit-widths to the well-performing ones.
OVD-Explorer: Optimism Should Not Be the Sole Pursuit of Exploration in Noisy Environments
Dec 20, 2023In reinforcement learning, the optimism in the face of uncertainty (OFU) is a mainstream principle for directing exploration towards less explored areas, characterized by higher uncertainty. However, in the presence of environmental stochasticity (noise), purely optimistic exploration may lead to excessive probing of high-noise areas, consequently impeding exploration efficiency. Hence, in exploring noisy environments, while optimism-driven exploration serves as a foundation, prudent attention to alleviating unnecessary over-exploration in high-noise areas becomes beneficial. In this work, we propose Optimistic Value Distribution Explorer (OVD-Explorer) to achieve a noise-aware optimistic exploration for continuous control. OVD-Explorer proposes a new measurement of the policy's exploration ability considering noise in optimistic perspectives, and leverages gradient ascent to drive exploration. Practically, OVD-Explorer can be easily integrated with continuous control RL algorithms. Extensive evaluations on the MuJoCo and GridChaos tasks demonstrate the superiority of OVD-Explorer in achieving noise-aware optimistic exploration.
Towards Compact 3D Representations via Point Feature Enhancement Masked Autoencoders
Dec 17, 2023Learning 3D representation plays a critical role in masked autoencoder (MAE) based pre-training methods for point cloud, including single-modal and cross-modal based MAE. Specifically, although cross-modal MAE methods learn strong 3D representations via the auxiliary of other modal knowledge, they often suffer from heavy computational burdens and heavily rely on massive cross-modal data pairs that are often unavailable, which hinders their applications in practice. Instead, single-modal methods with solely point clouds as input are preferred in real applications due to their simplicity and efficiency. However, such methods easily suffer from limited 3D representations with global random mask input. To learn compact 3D representations, we propose a simple yet effective Point Feature Enhancement Masked Autoencoders (Point-FEMAE), which mainly consists of a global branch and a local branch to capture latent semantic features. Specifically, to learn more compact features, a share-parameter Transformer encoder is introduced to extract point features from the global and local unmasked patches obtained by global random and local block mask strategies, followed by a specific decoder to reconstruct. Meanwhile, to further enhance features in the local branch, we propose a Local Enhancement Module with local patch convolution to perceive fine-grained local context at larger scales. Our method significantly improves the pre-training efficiency compared to cross-modal alternatives, and extensive downstream experiments underscore the state-of-the-art effectiveness, particularly outperforming our baseline (Point-MAE) by 5.16%, 5.00%, and 5.04% in three variants of ScanObjectNN, respectively. The code is available at https://github.com/zyh16143998882/AAAI24-PointFEMAE.