 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChaoqin Huang
Anomaly Detection in Electrocardiograms: Advancing Clinical Diagnosis Through Self-Supervised Learning
Apr 07, 2024
The electrocardiogram (ECG) is an essential tool for diagnosing heart disease, with computer-aided systems improving diagnostic accuracy and reducing healthcare costs. Despite advancements, existing systems often miss rare cardiac anomalies that could be precursors to serious, life-threatening issues or alterations in the cardiac macro/microstructure. We address this gap by focusing on self-supervised anomaly detection (AD), training exclusively on normal ECGs to recognize deviations indicating anomalies. We introduce a novel self-supervised learning framework for ECG AD, utilizing a vast dataset of normal ECGs to autonomously detect and localize cardiac anomalies. It proposes a novel masking and restoration technique alongside a multi-scale cross-attention module, enhancing the model's ability to integrate global and local signal features. The framework emphasizes accurate localization of anomalies within ECG signals, ensuring the method's clinical relevance and reliability. To reduce the impact of individual variability, the approach further incorporates crucial patient-specific information from ECG reports, such as age and gender, thus enabling accurate identification of a broad spectrum of cardiac anomalies, including rare ones. Utilizing an extensive dataset of 478,803 ECG graphic reports from real-world clinical practice, our method has demonstrated exceptional effectiveness in AD across all tested conditions, regardless of their frequency of occurrence, significantly outperforming existing models. It achieved superior performance metrics, including an AUROC of 91.2%, an F1 score of 83.7%, a sensitivity rate of 84.2%, a specificity of 83.0%, and a precision of 75.6% with a fixed recall rate of 90%. It has also demonstrated robust localization capabilities, with an AUROC of 76.5% and a Dice coefficient of 65.3% for anomaly localization.
Adapting Visual-Language Models for Generalizable Anomaly Detection in Medical Images
Mar 19, 2024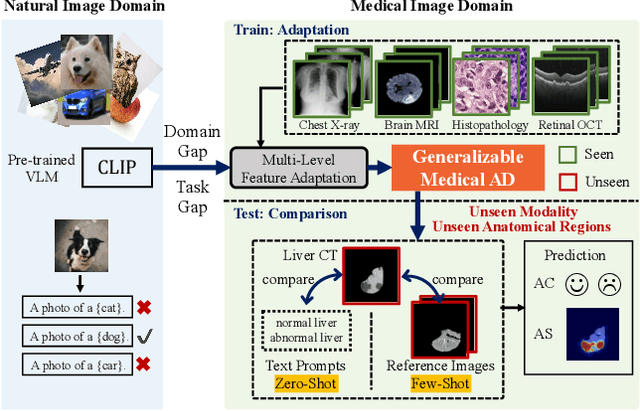
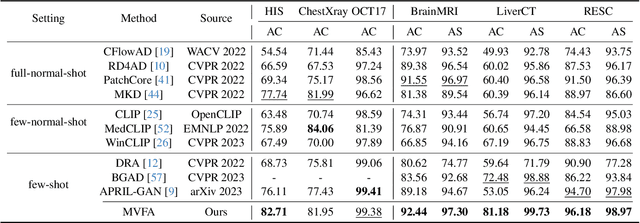
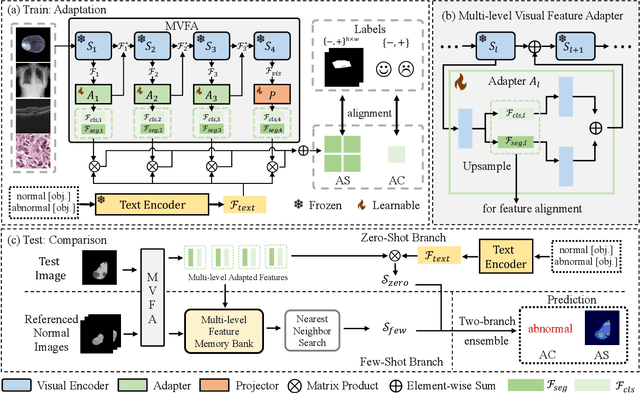
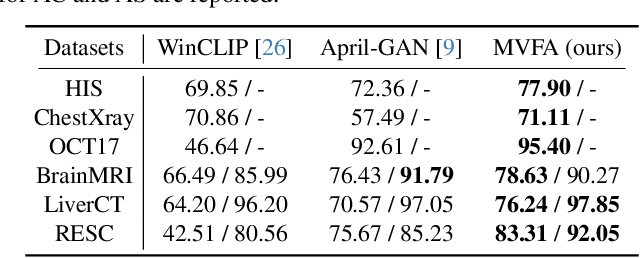
Recent advancements in large-scale visual-language pre-trained models have led to significant progress in zero-/few-shot anomaly detection within natural image domains. However, the substantial domain divergence between natural and medical images limits the effectiveness of these methodologies in medical anomaly detection. This paper introduces a novel lightweight multi-level adaptation and comparison framework to repurpose the CLIP model for medical anomaly detection. Our approach integrates multiple residual adapters into the pre-trained visual encoder, enabling a stepwise enhancement of visual features across different levels. This multi-level adaptation is guided by multi-level, pixel-wise visual-language feature alignment loss functions, which recalibrate the model's focus from object semantics in natural imagery to anomaly identification in medical images. The adapted features exhibit improved generalization across various medical data types, even in zero-shot scenarios where the model encounters unseen medical modalities and anatomical regions during training. Our experiments on medical anomaly detection benchmarks demonstrate that our method significantly surpasses current state-of-the-art models, with an average AUC improvement of 6.24% and 7.33% for anomaly classification, 2.03% and 2.37% for anomaly segmentation, under the zero-shot and few-shot settings, respectively. Source code is available at: https://github.com/MediaBrain-SJTU/MVFA-AD
Multi-Scale Memory Comparison for Zero-/Few-Shot Anomaly Detection
Aug 09, 2023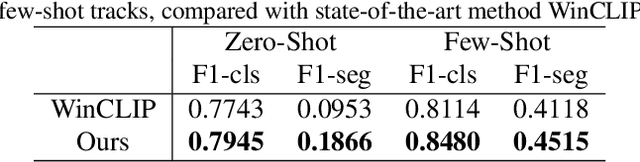
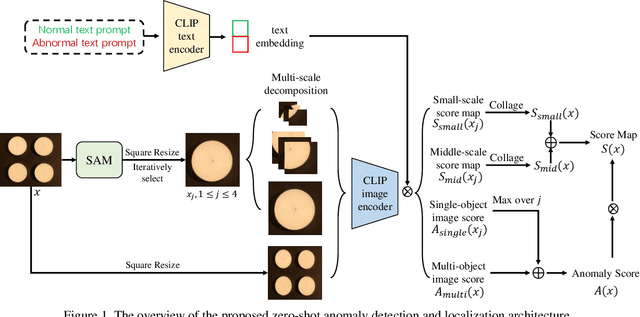


Anomaly detection has gained considerable attention due to its broad range of applications, particularly in industrial defect detection. To address the challenges of data collection, researchers have introduced zero-/few-shot anomaly detection techniques that require minimal normal images for each category. However, complex industrial scenarios often involve multiple objects, presenting a significant challenge. In light of this, we propose a straightforward yet powerful multi-scale memory comparison framework for zero-/few-shot anomaly detection. Our approach employs a global memory bank to capture features across the entire image, while an individual memory bank focuses on simplified scenes containing a single object. The efficacy of our method is validated by its remarkable achievement of 4th place in the zero-shot track and 2nd place in the few-shot track of the Visual Anomaly and Novelty Detection (VAND) competition.
Multi-scale Cross-restoration Framework for Electrocardiogram Anomaly Detection
Aug 03, 2023
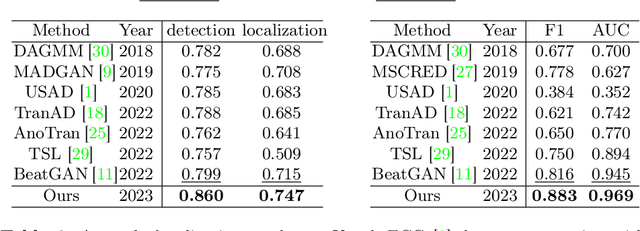
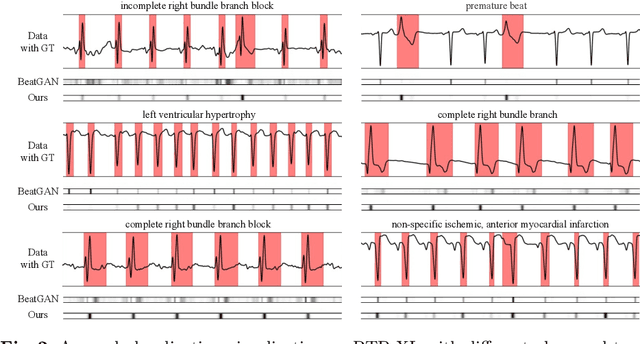
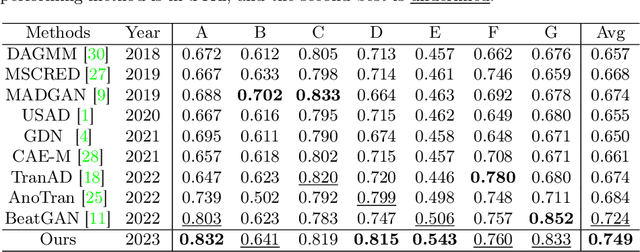
Electrocardiogram (ECG) is a widely used diagnostic tool for detecting heart conditions. Rare cardiac diseases may be underdiagnosed using traditional ECG analysis, considering that no training dataset can exhaust all possible cardiac disorders. This paper proposes using anomaly detection to identify any unhealthy status, with normal ECGs solely for training. However, detecting anomalies in ECG can be challenging due to significant inter-individual differences and anomalies present in both global rhythm and local morphology. To address this challenge, this paper introduces a novel multi-scale cross-restoration framework for ECG anomaly detection and localization that considers both local and global ECG characteristics. The proposed framework employs a two-branch autoencoder to facilitate multi-scale feature learning through a masking and restoration process, with one branch focusing on global features from the entire ECG and the other on local features from heartbeat-level details, mimicking the diagnostic process of cardiologists. Anomalies are identified by their high restoration errors. To evaluate the performance on a large number of individuals, this paper introduces a new challenging benchmark with signal point-level ground truths annotated by experienced cardiologists. The proposed method demonstrates state-of-the-art performance on this benchmark and two other well-known ECG datasets. The benchmark dataset and source code are available at: \url{https://github.com/MediaBrain-SJTU/ECGAD}
Registration based Few-Shot Anomaly Detection
Jul 15, 2022
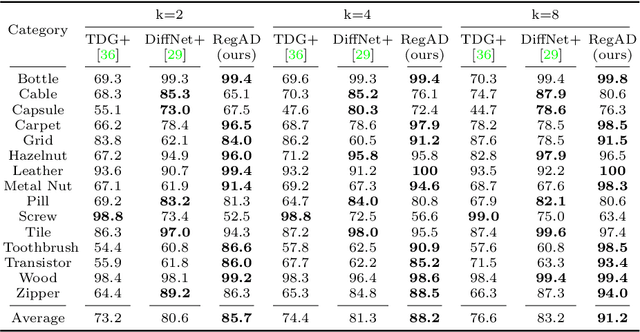
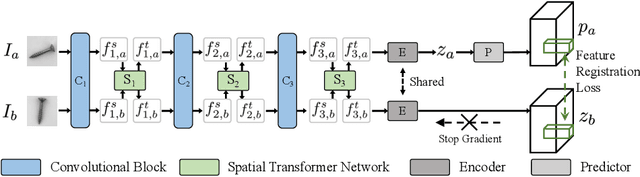
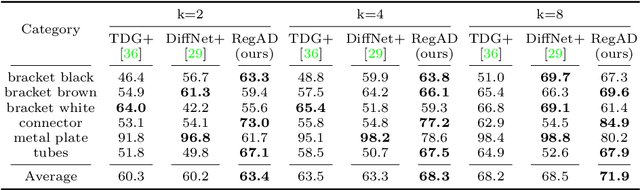
This paper considers few-shot anomaly detection (FSAD), a practical yet under-studied setting for anomaly detection (AD), where only a limited number of normal images are provided for each category at training. So far, existing FSAD studies follow the one-model-per-category learning paradigm used for standard AD, and the inter-category commonality has not been explored. Inspired by how humans detect anomalies, i.e., comparing an image in question to normal images, we here leverage registration, an image alignment task that is inherently generalizable across categories, as the proxy task, to train a category-agnostic anomaly detection model. During testing, the anomalies are identified by comparing the registered features of the test image and its corresponding support (normal) images. As far as we know, this is the first FSAD method that trains a single generalizable model and requires no re-training or parameter fine-tuning for new categories. Experimental results have shown that the proposed method outperforms the state-of-the-art FSAD methods by 3%-8% in AUC on the MVTec and MPDD benchmarks.
Self-Supervised Masking for Unsupervised Anomaly Detection and Localization
May 13, 2022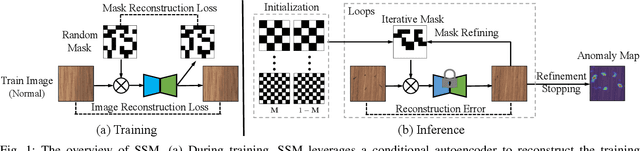
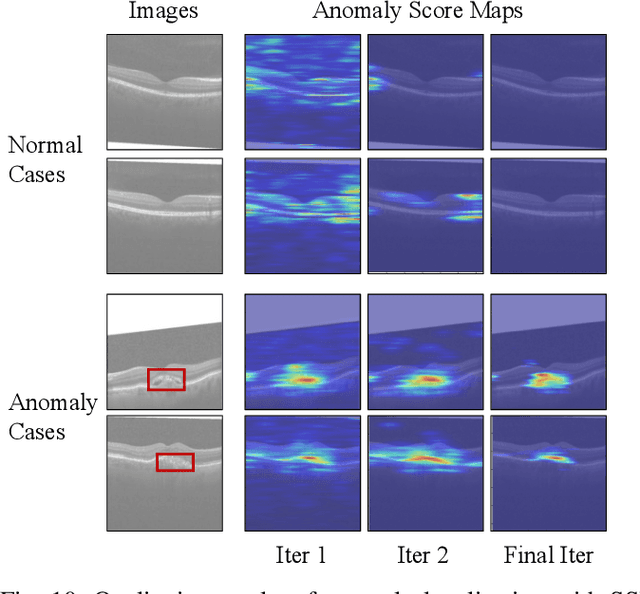
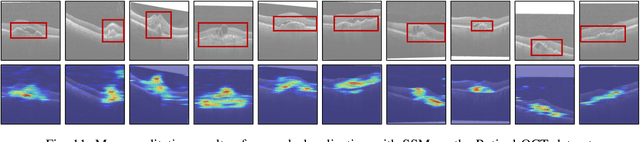
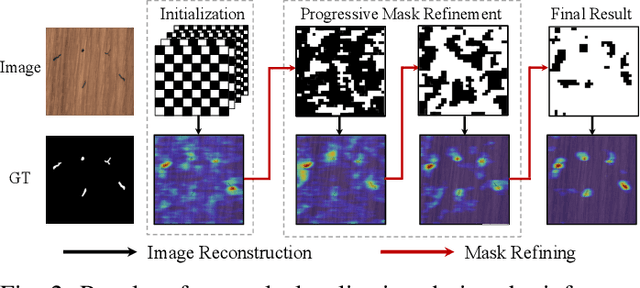
Recently, anomaly detection and localization in multimedia data have received significant attention among the machine learning community. In real-world applications such as medical diagnosis and industrial defect detection, anomalies only present in a fraction of the images. To extend the reconstruction-based anomaly detection architecture to the localized anomalies, we propose a self-supervised learning approach through random masking and then restoring, named Self-Supervised Masking (SSM) for unsupervised anomaly detection and localization. SSM not only enhances the training of the inpainting network but also leads to great improvement in the efficiency of mask prediction at inference. Through random masking, each image is augmented into a diverse set of training triplets, thus enabling the autoencoder to learn to reconstruct with masks of various sizes and shapes during training. To improve the efficiency and effectiveness of anomaly detection and localization at inference, we propose a novel progressive mask refinement approach that progressively uncovers the normal regions and finally locates the anomalous regions. The proposed SSM method outperforms several state-of-the-arts for both anomaly detection and anomaly localization, achieving 98.3% AUC on Retinal-OCT and 93.9% AUC on MVTec AD, respectively.
Self-supervised Tumor Segmentation through Layer Decomposition
Sep 07, 2021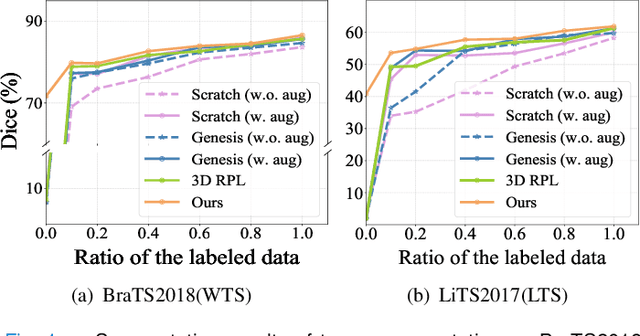
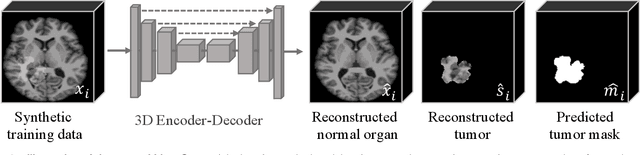

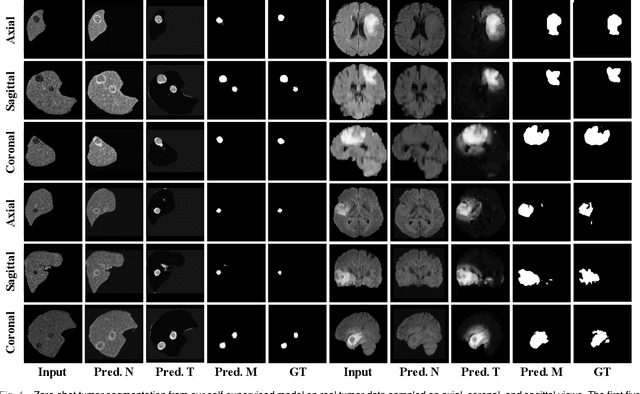
In this paper, we propose a self-supervised approach for tumor segmentation. Specifically, we advocate a zero-shot setting, where models from self-supervised learning should be directly applicable for the downstream task, without using any manual annotations whatsoever. We make the following contributions. First, with careful examination on existing self-supervised learning approaches, we reveal the surprising result that, given suitable data augmentation, models trained from scratch in fact achieve comparable performance to those pre-trained with self-supervised learning. Second, inspired by the fact that tumors tend to be characterized independently to the contexts, we propose a scalable pipeline for generating synthetic tumor data, and train a self-supervised model that minimises the generalisation gap with the downstream task. Third, we conduct extensive ablation studies on different downstream datasets, BraTS2018 for brain tumor segmentation and LiTS2017 for liver tumor segmentation. While evaluating the model transferability for tumor segmentation under a low-annotation regime, including an extreme case of zero-shot segmentation, the proposed approach demonstrates state-of-the-art performance, substantially outperforming all existing self-supervised approaches, and opening up the usage of self-supervised learning in practical scenarios.
ESAD: End-to-end Deep Semi-supervised Anomaly Detection
Dec 09, 2020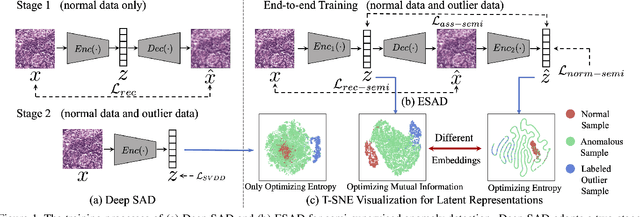
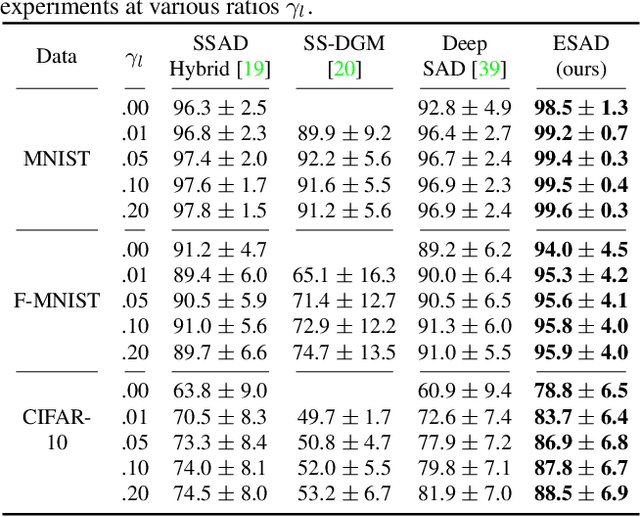
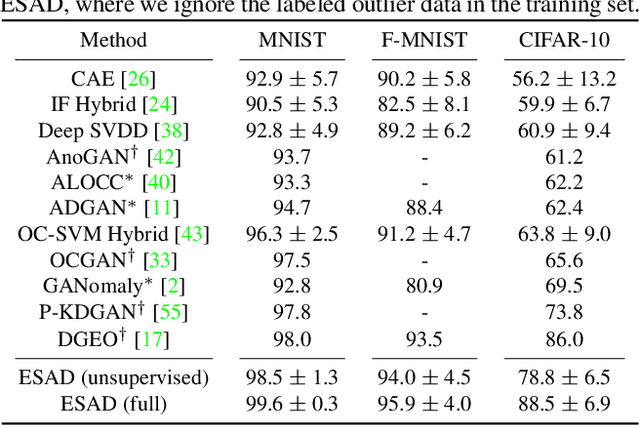
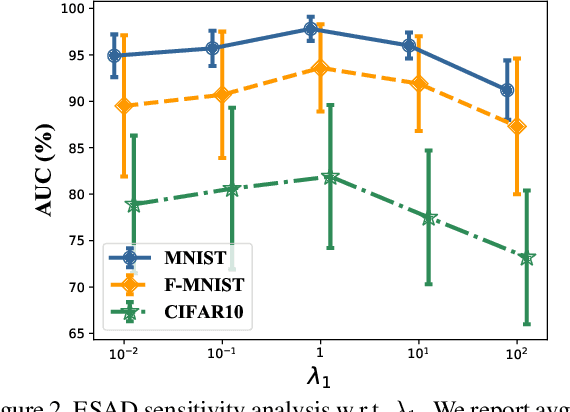
This paper explores semi-supervised anomaly detection, a more practical setting for anomaly detection where a small set of labeled outlier samples are provided in addition to a large amount of unlabeled data for training. Rethinking the optimization target of anomaly detection, we propose a new objective function that measures the KL-divergence between normal and anomalous data, and prove that two factors: the mutual information between the data and latent representations, and the entropy of latent representations, constitute an integral objective function for anomaly detection. To resolve the contradiction in simultaneously optimizing the two factors, we propose a novel encoder-decoder-encoder structure, with the first encoder focusing on optimizing the mutual information and the second encoder focusing on optimizing the entropy. The two encoders are enforced to share similar encoding with a consistent constraint on their latent representations. Extensive experiments have revealed that the proposed method significantly outperforms several state-of-the-arts on multiple benchmark datasets, including medical diagnosis and several classic anomaly detection benchmarks.
Deep Unsupervised Image Anomaly Detection: An Information Theoretic Framework
Dec 09, 2020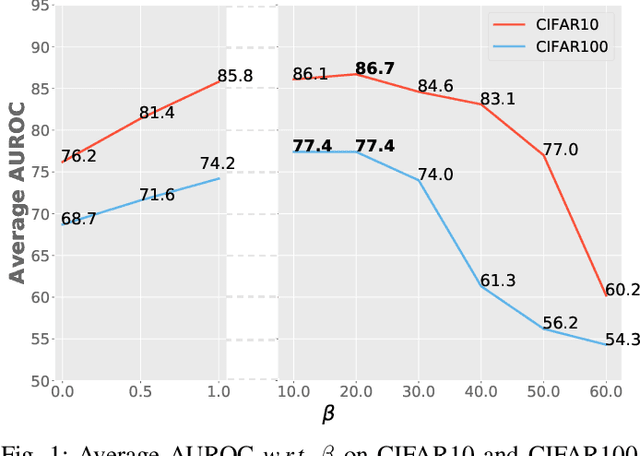
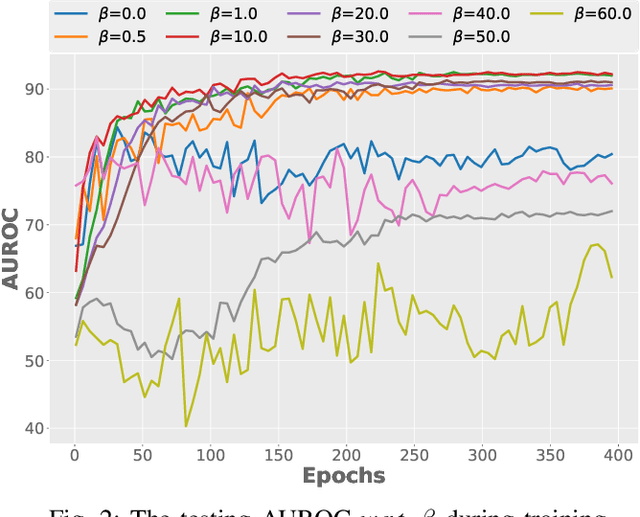
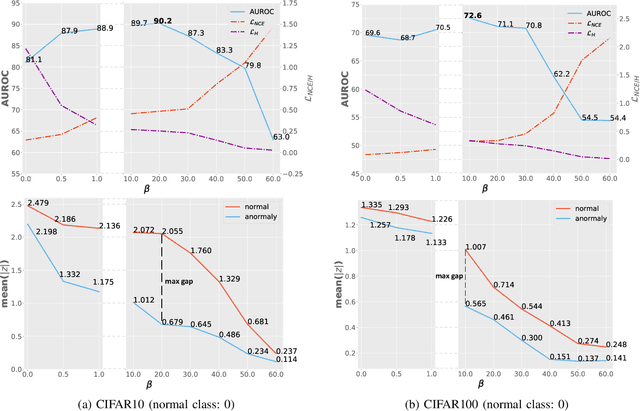
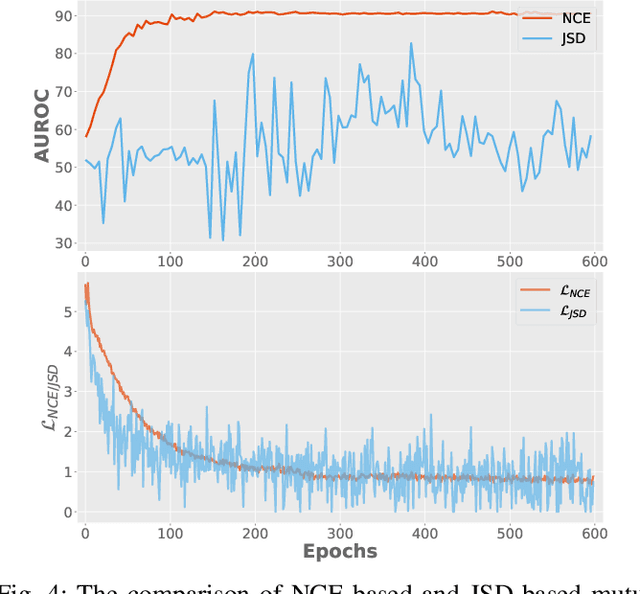
Surrogate task based methods have recently shown great promise for unsupervised image anomaly detection. However, there is no guarantee that the surrogate tasks share the consistent optimization direction with anomaly detection. In this paper, we return to a direct objective function for anomaly detection with information theory, which maximizes the distance between normal and anomalous data in terms of the joint distribution of images and their representation. Unfortunately, this objective function is not directly optimizable under the unsupervised setting where no anomalous data is provided during training. Through mathematical analysis of the above objective function, we manage to decompose it into four components. In order to optimize in an unsupervised fashion, we show that, under the assumption that distribution of the normal and anomalous data are separable in the latent space, its lower bound can be considered as a function which weights the trade-off between mutual information and entropy. This objective function is able to explain why the surrogate task based methods are effective for anomaly detection and further point out the potential direction of improvement. Based on this object function we introduce a novel information theoretic framework for unsupervised image anomaly detection. Extensive experiments have demonstrated that the proposed framework significantly outperforms several state-of-the-arts on multiple benchmark data sets.
Recurrent Residual Module for Fast Inference in Videos
Feb 27, 2018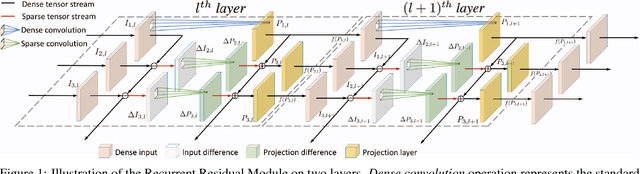

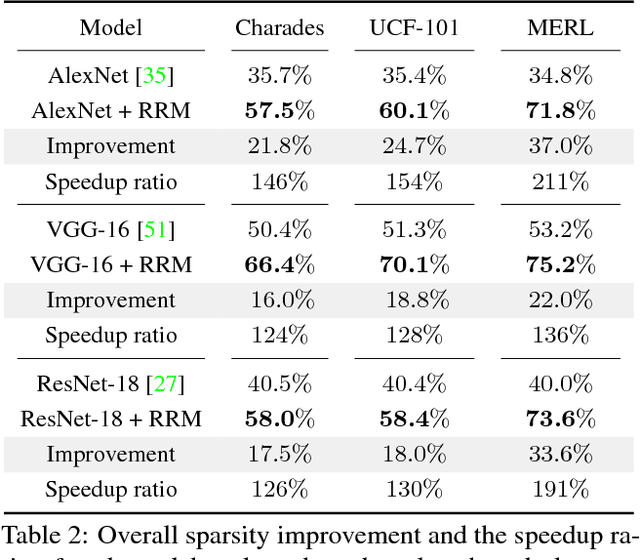
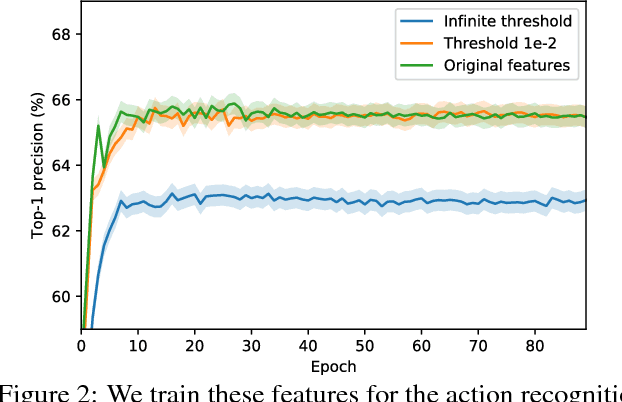
Deep convolutional neural networks (CNNs) have made impressive progress in many video recognition tasks such as video pose estimation and video object detection. However, CNN inference on video is computationally expensive due to processing dense frames individually. In this work, we propose a framework called Recurrent Residual Module (RRM) to accelerate the CNN inference for video recognition tasks. This framework has a novel design of using the similarity of the intermediate feature maps of two consecutive frames, to largely reduce the redundant computation. One unique property of the proposed method compared to previous work is that feature maps of each frame are precisely computed. The experiments show that, while maintaining the similar recognition performance, our RRM yields averagely 2x acceleration on the commonly used CNNs such as AlexNet, ResNet, deep compression model (thus 8-12x faster than the original dense models using the efficient inference engine), and impressively 9x acceleration on some binary networks such as XNOR-Nets (thus 500x faster than the original model). We further verify the effectiveness of the RRM on speeding up CNNs for video pose estimation and video object detection.