 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHao Luo
Uncovering the Text Embedding in Text-to-Image Diffusion Models
Apr 01, 2024
The correspondence between input text and the generated image exhibits opacity, wherein minor textual modifications can induce substantial deviations in the generated image. While, text embedding, as the pivotal intermediary between text and images, remains relatively underexplored. In this paper, we address this research gap by delving into the text embedding space, unleashing its capacity for controllable image editing and explicable semantic direction attributes within a learning-free framework. Specifically, we identify two critical insights regarding the importance of per-word embedding and their contextual correlations within text embedding, providing instructive principles for learning-free image editing. Additionally, we find that text embedding inherently possesses diverse semantic potentials, and further reveal this property through the lens of singular value decomposition (SVD). These uncovered properties offer practical utility for image editing and semantic discovery. More importantly, we expect the in-depth analyses and findings of the text embedding can enhance the understanding of text-to-image diffusion models.
Text Data-Centric Image Captioning with Interactive Prompts
Mar 28, 2024Supervised image captioning approaches have made great progress, but it is challenging to collect high-quality human-annotated image-text data. Recently, large-scale vision and language models (e.g., CLIP) and large-scale generative language models (e.g., GPT-2) have shown strong performances in various tasks, which also provide some new solutions for image captioning with web paired data, unpaired data or even text-only data. Among them, the mainstream solution is to project image embeddings into the text embedding space with the assistance of consistent representations between image-text pairs from the CLIP model. However, the current methods still face several challenges in adapting to the diversity of data configurations in a unified solution, accurately estimating image-text embedding bias, and correcting unsatisfactory prediction results in the inference stage. This paper proposes a new Text data-centric approach with Interactive Prompts for image Captioning, named TIPCap. 1) We consider four different settings which gradually reduce the dependence on paired data. 2) We construct a mapping module driven by multivariate Gaussian distribution to mitigate the modality gap, which is applicable to the above four different settings. 3) We propose a prompt interaction module that can incorporate optional prompt information before generating captions. Extensive experiments show that our TIPCap outperforms other weakly or unsupervised image captioning methods and achieves a new state-of-the-art performance on two widely used datasets, i.e., MS-COCO and Flickr30K.
Enhancing Hyperspectral Images via Diffusion Model and Group-Autoencoder Super-resolution Network
Feb 27, 2024Existing hyperspectral image (HSI) super-resolution (SR) methods struggle to effectively capture the complex spectral-spatial relationships and low-level details, while diffusion models represent a promising generative model known for their exceptional performance in modeling complex relations and learning high and low-level visual features. The direct application of diffusion models to HSI SR is hampered by challenges such as difficulties in model convergence and protracted inference time. In this work, we introduce a novel Group-Autoencoder (GAE) framework that synergistically combines with the diffusion model to construct a highly effective HSI SR model (DMGASR). Our proposed GAE framework encodes high-dimensional HSI data into low-dimensional latent space where the diffusion model works, thereby alleviating the difficulty of training the diffusion model while maintaining band correlation and considerably reducing inference time. Experimental results on both natural and remote sensing hyperspectral datasets demonstrate that the proposed method is superior to other state-of-the-art methods both visually and metrically.
Accelerating Parallel Sampling of Diffusion Models
Feb 15, 2024Diffusion models have emerged as state-of-the-art generative models for image generation. However, sampling from diffusion models is usually time-consuming due to the inherent autoregressive nature of their sampling process. In this work, we propose a novel approach that accelerates the sampling of diffusion models by parallelizing the autoregressive process. Specifically, we reformulate the sampling process as solving a system of triangular nonlinear equations through fixed-point iteration. With this innovative formulation, we explore several systematic techniques to further reduce the iteration steps required by the solving process. Applying these techniques, we introduce ParaTAA, a universal and training-free parallel sampling algorithm that can leverage extra computational and memory resources to increase the sampling speed. Our experiments demonstrate that ParaTAA can decrease the inference steps required by common sequential sampling algorithms such as DDIM and DDPM by a factor of 4~14 times. Notably, when applying ParaTAA with 100 steps DDIM for Stable Diffusion, a widely-used text-to-image diffusion model, it can produce the same images as the sequential sampling in only 7 inference steps.
ISAC with Backscattering RFID Tags: Joint Beamforming Design
Jan 31, 2024In this paper, we explore an integrated sensing and communication (ISAC) system with backscattering RFID tags. In this setup, an access point employs a communication beam to serve a user while leveraging a sensing beam to detect an RFID tag. Under the total transmit power constraint of the system, our objective is to design sensing and communication beams by considering the tag detection and communication requirements. First, we adopt zero-forcing to design the beamforming vectors, followed by solving a convex optimization problem to determine the power allocation between sensing and communication. Then, we study a joint beamforming design problem with the goal of minimizing the total transmit power while satisfying the tag detection and communication requirements. To resolve this, we re-formulate the non-convex constraints into convex second-order cone constraints. The simulation results demonstrate that, under different communication SINR requirements, joint beamforming optimization outperforms the zero-forcing-based method in terms of achievable detection distance, offering a promising approach for the ISAC-backscattering systems.
Integrated Imaging and Communication with Reconfigurable Intelligent Surfaces
Jan 29, 2024Reconfigurable intelligent surfaces, with their large number of antennas, offer an interesting opportunity for high spatial-resolution imaging. In this paper, we propose a novel RIS-aided integrated imaging and communication system that can reduce the RIS beam training overhead for communication by leveraging the imaging of the surrounding environment. In particular, using the RIS as a wireless imaging device, our system constructs the scene depth map of the environment, including the mobile user. Then, we develop a user detection algorithm that subtracts the background and extracts the mobile user attributes from the depth map. These attributes are then utilized to design the RIS interaction vector and the beam selection strategy with low overhead. Simulation results show that the proposed approach can achieve comparable beamforming gain to the optimal/exhaustive beam selection solution while requiring 1000 times less beam training overhead.
CL2CM: Improving Cross-Lingual Cross-Modal Retrieval via Cross-Lingual Knowledge Transfer
Dec 14, 2023Cross-lingual cross-modal retrieval has garnered increasing attention recently, which aims to achieve the alignment between vision and target language (V-T) without using any annotated V-T data pairs. Current methods employ machine translation (MT) to construct pseudo-parallel data pairs, which are then used to learn a multi-lingual and multi-modal embedding space that aligns visual and target-language representations. However, the large heterogeneous gap between vision and text, along with the noise present in target language translations, poses significant challenges in effectively aligning their representations. To address these challenges, we propose a general framework, Cross-Lingual to Cross-Modal (CL2CM), which improves the alignment between vision and target language using cross-lingual transfer. This approach allows us to fully leverage the merits of multi-lingual pre-trained models (e.g., mBERT) and the benefits of the same modality structure, i.e., smaller gap, to provide reliable and comprehensive semantic correspondence (knowledge) for the cross-modal network. We evaluate our proposed approach on two multilingual image-text datasets, Multi30K and MSCOCO, and one video-text dataset, VATEX. The results clearly demonstrate the effectiveness of our proposed method and its high potential for large-scale retrieval.
VGSG: Vision-Guided Semantic-Group Network for Text-based Person Search
Nov 13, 2023Text-based Person Search (TBPS) aims to retrieve images of target pedestrian indicated by textual descriptions. It is essential for TBPS to extract fine-grained local features and align them crossing modality. Existing methods utilize external tools or heavy cross-modal interaction to achieve explicit alignment of cross-modal fine-grained features, which is inefficient and time-consuming. In this work, we propose a Vision-Guided Semantic-Group Network (VGSG) for text-based person search to extract well-aligned fine-grained visual and textual features. In the proposed VGSG, we develop a Semantic-Group Textual Learning (SGTL) module and a Vision-guided Knowledge Transfer (VGKT) module to extract textual local features under the guidance of visual local clues. In SGTL, in order to obtain the local textual representation, we group textual features from the channel dimension based on the semantic cues of language expression, which encourages similar semantic patterns to be grouped implicitly without external tools. In VGKT, a vision-guided attention is employed to extract visual-related textual features, which are inherently aligned with visual cues and termed vision-guided textual features. Furthermore, we design a relational knowledge transfer, including a vision-language similarity transfer and a class probability transfer, to adaptively propagate information of the vision-guided textual features to semantic-group textual features. With the help of relational knowledge transfer, VGKT is capable of aligning semantic-group textual features with corresponding visual features without external tools and complex pairwise interaction. Experimental results on two challenging benchmarks demonstrate its superiority over state-of-the-art methods.
Deep Learning Enables Large Depth-of-Field Images for Sub-Diffraction-Limit Scanning Superlens Microscopy
Oct 27, 2023Scanning electron microscopy (SEM) is indispensable in diverse applications ranging from microelectronics to food processing because it provides large depth-of-field images with a resolution beyond the optical diffraction limit. However, the technology requires coating conductive films on insulator samples and a vacuum environment. We use deep learning to obtain the mapping relationship between optical super-resolution (OSR) images and SEM domain images, which enables the transformation of OSR images into SEM-like large depth-of-field images. Our custom-built scanning superlens microscopy (SSUM) system, which requires neither coating samples by conductive films nor a vacuum environment, is used to acquire the OSR images with features down to ~80 nm. The peak signal-to-noise ratio (PSNR) and structural similarity index measure values indicate that the deep learning method performs excellently in image-to-image translation, with a PSNR improvement of about 0.74 dB over the optical super-resolution images. The proposed method provides a high level of detail in the reconstructed results, indicating that it has broad applicability to chip-level defect detection, biological sample analysis, forensics, and various other fields.
SCT: A Simple Baseline for Parameter-Efficient Fine-Tuning via Salient Channels
Sep 18, 2023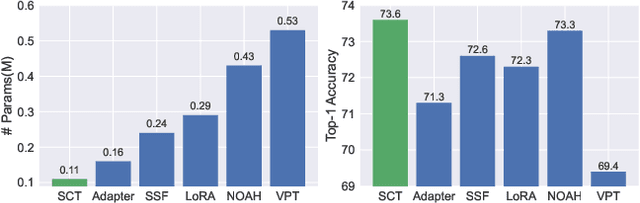
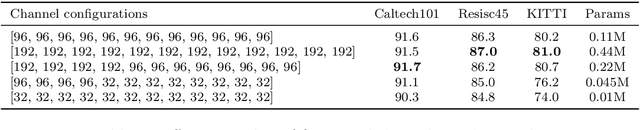
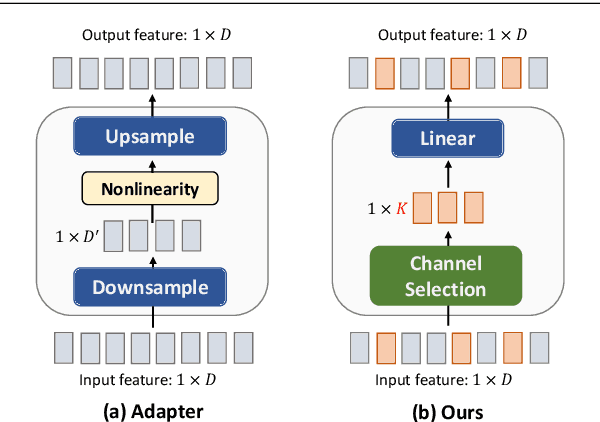

Pre-trained vision transformers have strong representation benefits to various downstream tasks. Recently, many parameter-efficient fine-tuning (PEFT) methods have been proposed, and their experiments demonstrate that tuning only 1% of extra parameters could surpass full fine-tuning in low-data resource scenarios. However, these methods overlook the task-specific information when fine-tuning diverse downstream tasks. In this paper, we propose a simple yet effective method called "Salient Channel Tuning" (SCT) to leverage the task-specific information by forwarding the model with the task images to select partial channels in a feature map that enables us to tune only 1/8 channels leading to significantly lower parameter costs. Experiments outperform full fine-tuning on 18 out of 19 tasks in the VTAB-1K benchmark by adding only 0.11M parameters of the ViT-B, which is 780$\times$ fewer than its full fine-tuning counterpart. Furthermore, experiments on domain generalization and few-shot learning surpass other PEFT methods with lower parameter costs, demonstrating our proposed tuning technique's strong capability and effectiveness in the low-data regime.