 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFabio Poiesi
Light-weight Retinal Layer Segmentation with Global Reasoning
Apr 25, 2024
Automatic retinal layer segmentation with medical images, such as optical coherence tomography (OCT) images, serves as an important tool for diagnosing ophthalmic diseases. However, it is challenging to achieve accurate segmentation due to low contrast and blood flow noises presented in the images. In addition, the algorithm should be light-weight to be deployed for practical clinical applications. Therefore, it is desired to design a light-weight network with high performance for retinal layer segmentation. In this paper, we propose LightReSeg for retinal layer segmentation which can be applied to OCT images. Specifically, our approach follows an encoder-decoder structure, where the encoder part employs multi-scale feature extraction and a Transformer block for fully exploiting the semantic information of feature maps at all scales and making the features have better global reasoning capabilities, while the decoder part, we design a multi-scale asymmetric attention (MAA) module for preserving the semantic information at each encoder scale. The experiments show that our approach achieves a better segmentation performance compared to the current state-of-the-art method TransUnet with 105.7M parameters on both our collected dataset and two other public datasets, with only 3.3M parameters.
IFFNeRF: Initialisation Free and Fast 6DoF pose estimation from a single image and a NeRF model
Mar 19, 2024



We introduce IFFNeRF to estimate the six degrees-of-freedom (6DoF) camera pose of a given image, building on the Neural Radiance Fields (NeRF) formulation. IFFNeRF is specifically designed to operate in real-time and eliminates the need for an initial pose guess that is proximate to the sought solution. IFFNeRF utilizes the Metropolis-Hasting algorithm to sample surface points from within the NeRF model. From these sampled points, we cast rays and deduce the color for each ray through pixel-level view synthesis. The camera pose can then be estimated as the solution to a Least Squares problem by selecting correspondences between the query image and the resulting bundle. We facilitate this process through a learned attention mechanism, bridging the query image embedding with the embedding of parameterized rays, thereby matching rays pertinent to the image. Through synthetic and real evaluation settings, we show that our method can improve the angular and translation error accuracy by 80.1% and 67.3%, respectively, compared to iNeRF while performing at 34fps on consumer hardware and not requiring the initial pose guess.
Zero-Shot Point Cloud Registration
Dec 08, 2023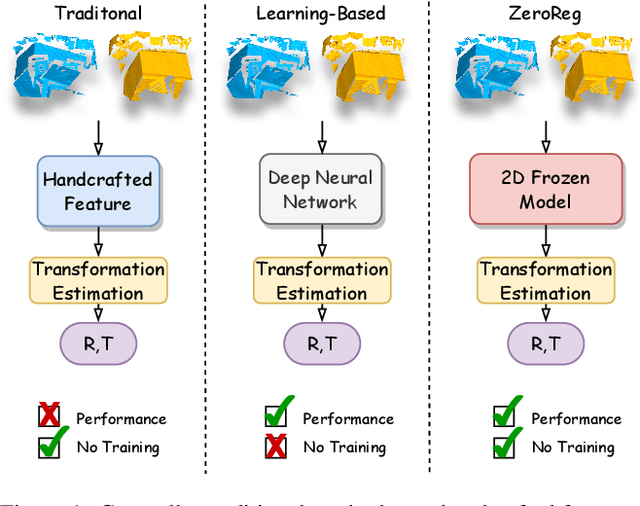
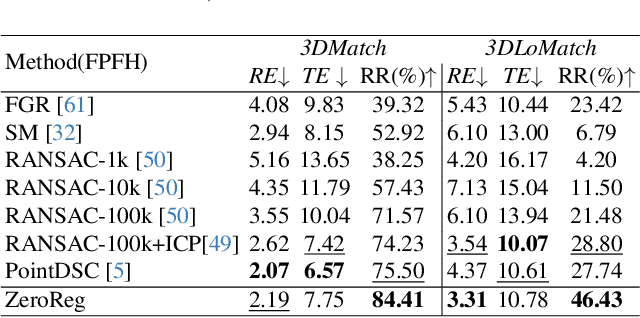
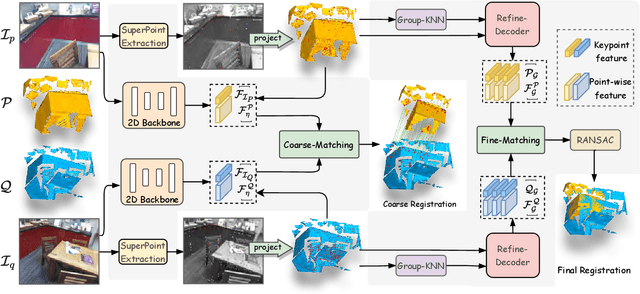
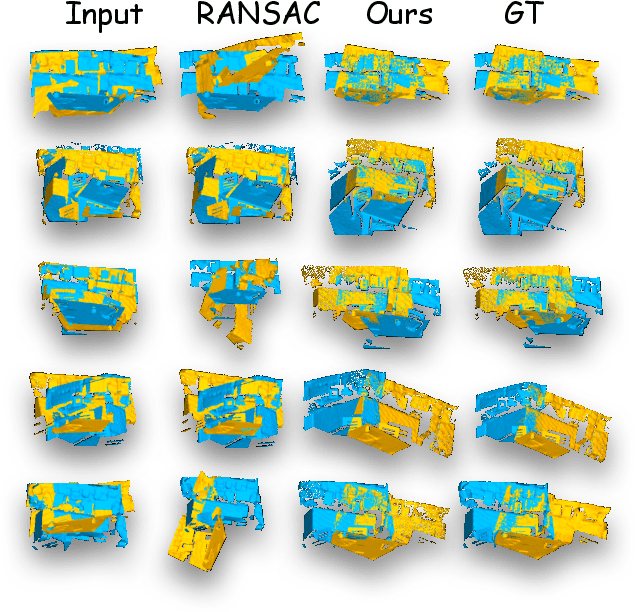
Learning-based point cloud registration approaches have significantly outperformed their traditional counterparts. However, they typically require extensive training on specific datasets. In this paper, we propose , the first zero-shot point cloud registration approach that eliminates the need for training on point cloud datasets. The cornerstone of ZeroReg is the novel transfer of image features from keypoints to the point cloud, enriched by aggregating information from 3D geometric neighborhoods. Specifically, we extract keypoints and features from 2D image pairs using a frozen pretrained 2D backbone. These features are then projected in 3D, and patches are constructed by searching for neighboring points. We integrate the geometric and visual features of each point using our novel parameter-free geometric decoder. Subsequently, the task of determining correspondences between point clouds is formulated as an optimal transport problem. Extensive evaluations of ZeroReg demonstrate its competitive performance against both traditional and learning-based methods. On benchmarks such as 3DMatch, 3DLoMatch, and ScanNet, ZeroReg achieves impressive Recall Ratios (RR) of over 84%, 46%, and 75%, respectively.
Open-vocabulary object 6D pose estimation
Dec 07, 2023We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g. CAD or video sequence) is required at inference, (iii) the object is imaged from two different viewpoints of two different scenes, and (iv) the object was not observed during the training phase. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from two distinct scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 39 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes. Project page: https://jcorsetti.github.io/oryon/.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Dec 04, 2023Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. We will release the source code publicly.
Object 6D pose estimation meets zero-shot learning
Dec 01, 2023Object 6D pose estimation methods can achieve high accuracy when trained and tested on the same objects. However, estimating the pose of objects that are absent at training time is still a challenge. In this work, we advance the state-of-the-art in zero-shot object 6D pose estimation by proposing the first method that fuses the contribution of pre-trained geometric and vision foundation models. Unlike state-of-the-art approaches that train their pipeline on data specifically crafted for the 6D pose estimation task, our method does not require task-specific finetuning. Instead, our method, which we name PoMZ, combines geometric descriptors learned from point cloud data with visual features learned from large-scale web images to produce distinctive 3D point-level descriptors. By applying an off-the-shelf registration algorithm, like RANSAC, PoMZ outperforms all state-of-the-art zero-shot object 6D pose estimation approaches. We extensively evaluate PoMZ across the seven core datasets of the BOP Benchmark, encompassing over a hundred objects and 20 thousand images captured in diverse scenarios. PoMZ ranks first in the BOP Benchmark under the category Task 4: 6D localization of unseen objects. We will release the source code publicly.
Delving into CLIP latent space for Video Anomaly Recognition
Oct 04, 2023



We tackle the complex problem of detecting and recognising anomalies in surveillance videos at the frame level, utilising only video-level supervision. We introduce the novel method AnomalyCLIP, the first to combine Large Language and Vision (LLV) models, such as CLIP, with multiple instance learning for joint video anomaly detection and classification. Our approach specifically involves manipulating the latent CLIP feature space to identify the normal event subspace, which in turn allows us to effectively learn text-driven directions for abnormal events. When anomalous frames are projected onto these directions, they exhibit a large feature magnitude if they belong to a particular class. We also introduce a computationally efficient Transformer architecture to model short- and long-term temporal dependencies between frames, ultimately producing the final anomaly score and class prediction probabilities. We compare AnomalyCLIP against state-of-the-art methods considering three major anomaly detection benchmarks, i.e. ShanghaiTech, UCF-Crime, and XD-Violence, and empirically show that it outperforms baselines in recognising video anomalies.
Detect, Augment, Compose, and Adapt: Four Steps for Unsupervised Domain Adaptation in Object Detection
Aug 29, 2023



Unsupervised domain adaptation (UDA) plays a crucial role in object detection when adapting a source-trained detector to a target domain without annotated data. In this paper, we propose a novel and effective four-step UDA approach that leverages self-supervision and trains source and target data concurrently. We harness self-supervised learning to mitigate the lack of ground truth in the target domain. Our method consists of the following steps: (1) identify the region with the highest-confidence set of detections in each target image, which serve as our pseudo-labels; (2) crop the identified region and generate a collection of its augmented versions; (3) combine these latter into a composite image; (4) adapt the network to the target domain using the composed image. Through extensive experiments under cross-camera, cross-weather, and synthetic-to-real scenarios, our approach achieves state-of-the-art performance, improving upon the nearest competitor by more than 2% in terms of mean Average Precision (mAP). The code is available at https://github.com/MohamedTEV/DACA.
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
Aug 29, 2023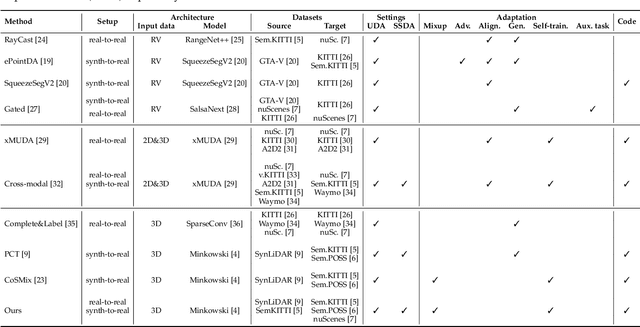
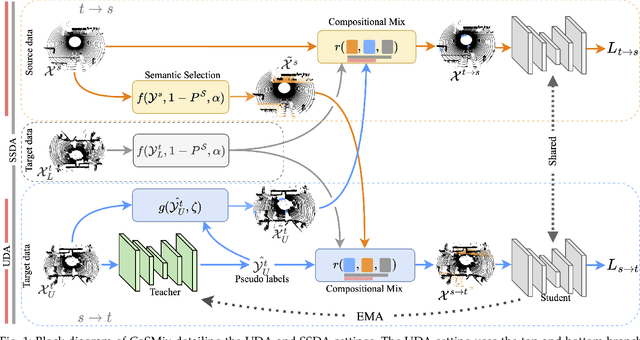
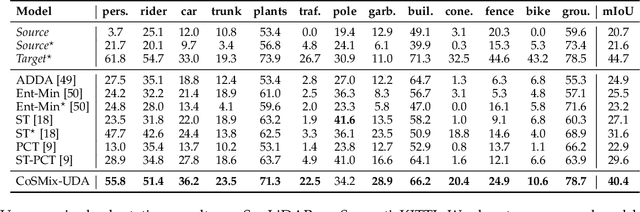
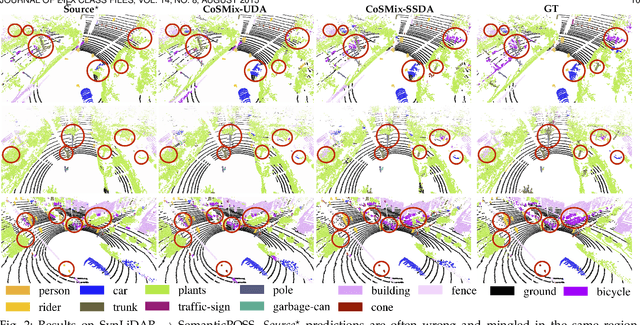
Deep-learning models for 3D point cloud semantic segmentation exhibit limited generalization capabilities when trained and tested on data captured with different sensors or in varying environments due to domain shift. Domain adaptation methods can be employed to mitigate this domain shift, for instance, by simulating sensor noise, developing domain-agnostic generators, or training point cloud completion networks. Often, these methods are tailored for range view maps or necessitate multi-modal input. In contrast, domain adaptation in the image domain can be executed through sample mixing, which emphasizes input data manipulation rather than employing distinct adaptation modules. In this study, we introduce compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. We present a two-branch symmetric network architecture capable of concurrently processing point clouds from a source domain (e.g. synthetic) and point clouds from a target domain (e.g. real-world). Each branch operates within one domain by integrating selected data fragments from the other domain and utilizing semantic information derived from source labels and target (pseudo) labels. Additionally, our method can leverage a limited number of human point-level annotations (semi-supervised) to further enhance performance. We assess our approach in both synthetic-to-real and real-to-real scenarios using LiDAR datasets and demonstrate that it significantly outperforms state-of-the-art methods in both unsupervised and semi-supervised settings.