 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElisa Ricci
Vocabulary-free Image Classification and Semantic Segmentation
Apr 16, 2024
Large vision-language models revolutionized image classification and semantic segmentation paradigms. However, they typically assume a pre-defined set of categories, or vocabulary, at test time for composing textual prompts. This assumption is impractical in scenarios with unknown or evolving semantic context. Here, we address this issue and introduce the Vocabulary-free Image Classification (VIC) task, which aims to assign a class from an unconstrained language-induced semantic space to an input image without needing a known vocabulary. VIC is challenging due to the vastness of the semantic space, which contains millions of concepts, including fine-grained categories. To address VIC, we propose Category Search from External Databases (CaSED), a training-free method that leverages a pre-trained vision-language model and an external database. CaSED first extracts the set of candidate categories from the most semantically similar captions in the database and then assigns the image to the best-matching candidate category according to the same vision-language model. Furthermore, we demonstrate that CaSED can be applied locally to generate a coarse segmentation mask that classifies image regions, introducing the task of Vocabulary-free Semantic Segmentation. CaSED and its variants outperform other more complex vision-language models, on classification and semantic segmentation benchmarks, while using much fewer parameters.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.
Test-Time Zero-Shot Temporal Action Localization
Apr 11, 2024Zero-Shot Temporal Action Localization (ZS-TAL) seeks to identify and locate actions in untrimmed videos unseen during training. Existing ZS-TAL methods involve fine-tuning a model on a large amount of annotated training data. While effective, training-based ZS-TAL approaches assume the availability of labeled data for supervised learning, which can be impractical in some applications. Furthermore, the training process naturally induces a domain bias into the learned model, which may adversely affect the model's generalization ability to arbitrary videos. These considerations prompt us to approach the ZS-TAL problem from a radically novel perspective, relaxing the requirement for training data. To this aim, we introduce a novel method that performs Test-Time adaptation for Temporal Action Localization (T3AL). In a nutshell, T3AL adapts a pre-trained Vision and Language Model (VLM). T3AL operates in three steps. First, a video-level pseudo-label of the action category is computed by aggregating information from the entire video. Then, action localization is performed adopting a novel procedure inspired by self-supervised learning. Finally, frame-level textual descriptions extracted with a state-of-the-art captioning model are employed for refining the action region proposals. We validate the effectiveness of T3AL by conducting experiments on the THUMOS14 and the ActivityNet-v1.3 datasets. Our results demonstrate that T3AL significantly outperforms zero-shot baselines based on state-of-the-art VLMs, confirming the benefit of a test-time adaptation approach.
MULTIFLOW: Shifting Towards Task-Agnostic Vision-Language Pruning
Apr 08, 2024While excellent in transfer learning, Vision-Language models (VLMs) come with high computational costs due to their large number of parameters. To address this issue, removing parameters via model pruning is a viable solution. However, existing techniques for VLMs are task-specific, and thus require pruning the network from scratch for each new task of interest. In this work, we explore a new direction: Task-Agnostic Vision-Language Pruning (TA-VLP). Given a pretrained VLM, the goal is to find a unique pruned counterpart transferable to multiple unknown downstream tasks. In this challenging setting, the transferable representations already encoded in the pretrained model are a key aspect to preserve. Thus, we propose Multimodal Flow Pruning (MULTIFLOW), a first, gradient-free, pruning framework for TA-VLP where: (i) the importance of a parameter is expressed in terms of its magnitude and its information flow, by incorporating the saliency of the neurons it connects; and (ii) pruning is driven by the emergent (multimodal) distribution of the VLM parameters after pretraining. We benchmark eight state-of-the-art pruning algorithms in the context of TA-VLP, experimenting with two VLMs, three vision-language tasks, and three pruning ratios. Our experimental results show that MULTIFLOW outperforms recent sophisticated, combinatorial competitors in the vast majority of the cases, paving the way towards addressing TA-VLP. The code is publicly available at https://github.com/FarinaMatteo/multiflow.
Harnessing Large Language Models for Training-free Video Anomaly Detection
Apr 01, 2024Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training-free paradigm, exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
Feb 22, 2024Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net - a workhorse behind image generation - scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. See our website at https://snap-research.github.io/snapvideo/.
Democratizing Fine-grained Visual Recognition with Large Language Models
Jan 24, 2024Identifying subordinate-level categories from images is a longstanding task in computer vision and is referred to as fine-grained visual recognition (FGVR). It has tremendous significance in real-world applications since an average layperson does not excel at differentiating species of birds or mushrooms due to subtle differences among the species. A major bottleneck in developing FGVR systems is caused by the need of high-quality paired expert annotations. To circumvent the need of expert knowledge we propose Fine-grained Semantic Category Reasoning (FineR) that internally leverages the world knowledge of large language models (LLMs) as a proxy in order to reason about fine-grained category names. In detail, to bridge the modality gap between images and LLM, we extract part-level visual attributes from images as text and feed that information to a LLM. Based on the visual attributes and its internal world knowledge the LLM reasons about the subordinate-level category names. Our training-free FineR outperforms several state-of-the-art FGVR and language and vision assistant models and shows promise in working in the wild and in new domains where gathering expert annotation is arduous.
Diversified in-domain synthesis with efficient fine-tuning for few-shot classification
Dec 07, 2023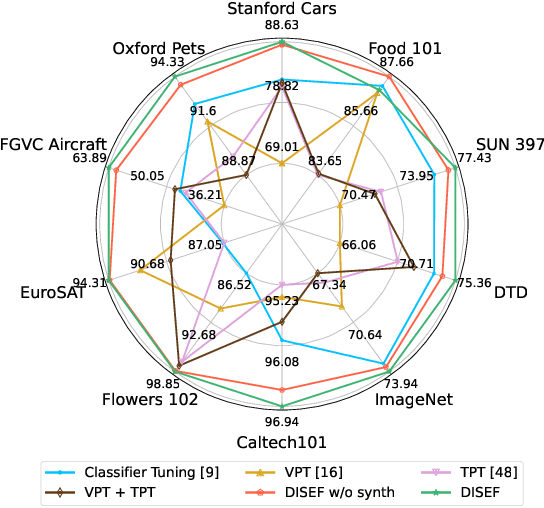

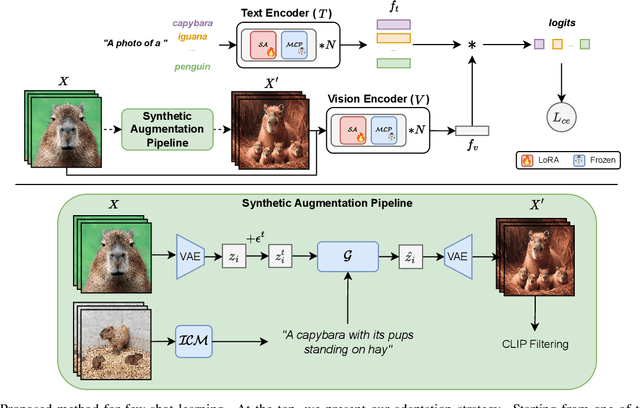
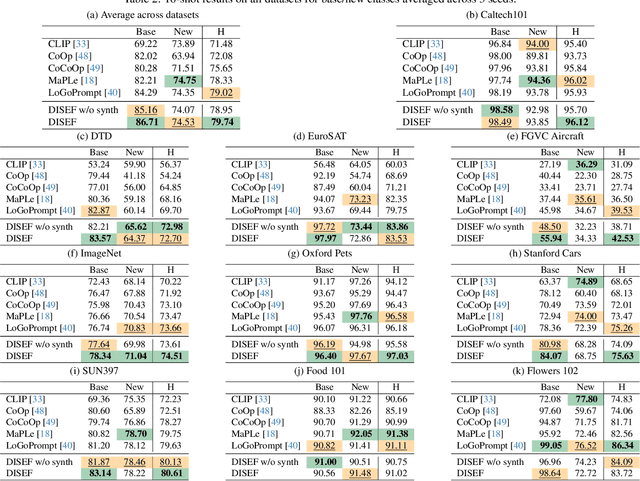
Few-shot image classification aims to learn an image classifier using only a small set of labeled examples per class. A recent research direction for improving few-shot classifiers involves augmenting the labelled samples with synthetic images created by state-of-the-art text-to-image generation models. Following this trend, we propose Diversified In-domain Synthesis with Efficient Fine-tuning (DISEF), a novel approach which addresses the generalization challenge in few-shot learning using synthetic data. DISEF consists of two main components. First, we propose a novel text-to-image augmentation pipeline that, by leveraging the real samples and their rich semantics coming from an advanced captioning model, promotes in-domain sample diversity for better generalization. Second, we emphasize the importance of effective model fine-tuning in few-shot recognition, proposing to use Low-Rank Adaptation (LoRA) for joint adaptation of the text and image encoders in a Vision Language Model. We validate our method in ten different benchmarks, consistently outperforming baselines and establishing a new state-of-the-art for few-shot classification. Code is available at https://github.com/vturrisi/disef.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.
Collaborative Neural Painting
Dec 04, 2023The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users' modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.