 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingxuan Liu
Fairness-Aware Interpretable Modeling (FAIM) for Trustworthy Machine Learning in Healthcare
Mar 08, 2024




The escalating integration of machine learning in high-stakes fields such as healthcare raises substantial concerns about model fairness. We propose an interpretable framework - Fairness-Aware Interpretable Modeling (FAIM), to improve model fairness without compromising performance, featuring an interactive interface to identify a "fairer" model from a set of high-performing models and promoting the integration of data-driven evidence and clinical expertise to enhance contextualized fairness. We demonstrated FAIM's value in reducing sex and race biases by predicting hospital admission with two real-world databases, MIMIC-IV-ED and SGH-ED. We show that for both datasets, FAIM models not only exhibited satisfactory discriminatory performance but also significantly mitigated biases as measured by well-established fairness metrics, outperforming commonly used bias-mitigation methods. Our approach demonstrates the feasibility of improving fairness without sacrificing performance and provides an a modeling mode that invites domain experts to engage, fostering a multidisciplinary effort toward tailored AI fairness.
Survival modeling using deep learning, machine learning and statistical methods: A comparative analysis for predicting mortality after hospital admission
Mar 04, 2024
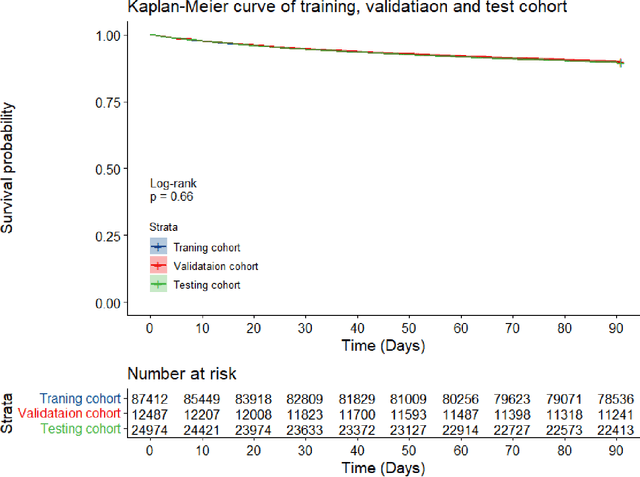
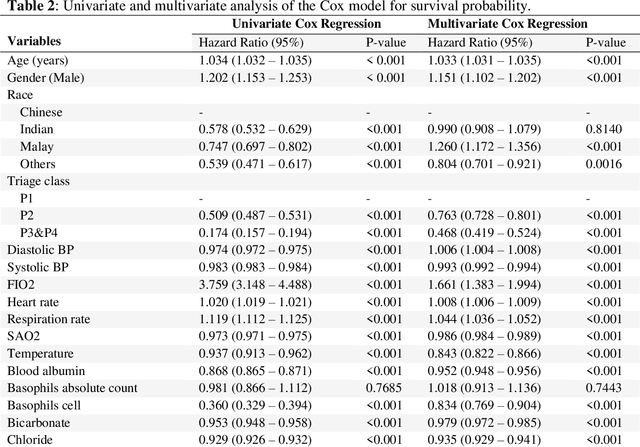
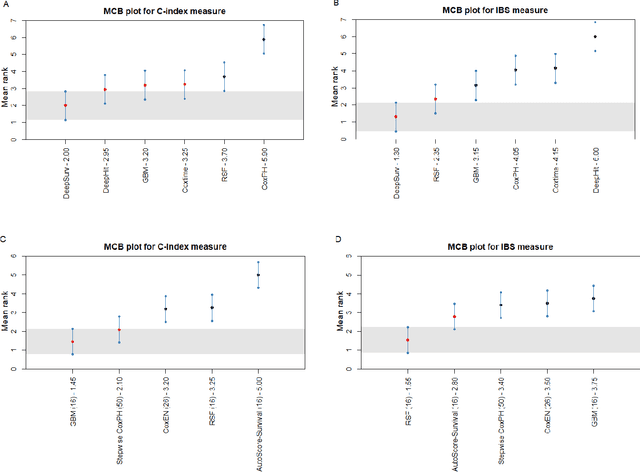
Survival analysis is essential for studying time-to-event outcomes and providing a dynamic understanding of the probability of an event occurring over time. Various survival analysis techniques, from traditional statistical models to state-of-the-art machine learning algorithms, support healthcare intervention and policy decisions. However, there remains ongoing discussion about their comparative performance. We conducted a comparative study of several survival analysis methods, including Cox proportional hazards (CoxPH), stepwise CoxPH, elastic net penalized Cox model, Random Survival Forests (RSF), Gradient Boosting machine (GBM) learning, AutoScore-Survival, DeepSurv, time-dependent Cox model based on neural network (CoxTime), and DeepHit survival neural network. We applied the concordance index (C-index) for model goodness-of-fit, and integral Brier scores (IBS) for calibration, and considered the model interpretability. As a case study, we performed a retrospective analysis of patients admitted through the emergency department of a tertiary hospital from 2017 to 2019, predicting 90-day all-cause mortality based on patient demographics, clinicopathological features, and historical data. The results of the C-index indicate that deep learning achieved comparable performance, with DeepSurv producing the best discrimination (DeepSurv: 0.893; CoxTime: 0.892; DeepHit: 0.891). The calibration of DeepSurv (IBS: 0.041) performed the best, followed by RSF (IBS: 0.042) and GBM (IBS: 0.0421), all using the full variables. Moreover, AutoScore-Survival, using a minimal variable subset, is easy to interpret, and can achieve good discrimination and calibration (C-index: 0.867; IBS: 0.044). While all models were satisfactory, DeepSurv exhibited the best discrimination and calibration. In addition, AutoScore-Survival offers a more parsimonious model and excellent interpretability.
Spiking-PhysFormer: Camera-Based Remote Photoplethysmography with Parallel Spike-driven Transformer
Feb 09, 2024Artificial neural networks (ANNs) can help camera-based remote photoplethysmography (rPPG) in measuring cardiac activity and physiological signals from facial videos, such as pulse wave, heart rate and respiration rate with better accuracy. However, most existing ANN-based methods require substantial computing resources, which poses challenges for effective deployment on mobile devices. Spiking neural networks (SNNs), on the other hand, hold immense potential for energy-efficient deep learning owing to their binary and event-driven architecture. To the best of our knowledge, we are the first to introduce SNNs into the realm of rPPG, proposing a hybrid neural network (HNN) model, the Spiking-PhysFormer, aimed at reducing power consumption. Specifically, the proposed Spiking-PhyFormer consists of an ANN-based patch embedding block, SNN-based transformer blocks, and an ANN-based predictor head. First, to simplify the transformer block while preserving its capacity to aggregate local and global spatio-temporal features, we design a parallel spike transformer block to replace sequential sub-blocks. Additionally, we propose a simplified spiking self-attention mechanism that omits the value parameter without compromising the model's performance. Experiments conducted on four datasets-PURE, UBFC-rPPG, UBFC-Phys, and MMPD demonstrate that the proposed model achieves a 12.4\% reduction in power consumption compared to PhysFormer. Additionally, the power consumption of the transformer block is reduced by a factor of 12.2, while maintaining decent performance as PhysFormer and other ANN-based models.
Democratizing Fine-grained Visual Recognition with Large Language Models
Jan 24, 2024Identifying subordinate-level categories from images is a longstanding task in computer vision and is referred to as fine-grained visual recognition (FGVR). It has tremendous significance in real-world applications since an average layperson does not excel at differentiating species of birds or mushrooms due to subtle differences among the species. A major bottleneck in developing FGVR systems is caused by the need of high-quality paired expert annotations. To circumvent the need of expert knowledge we propose Fine-grained Semantic Category Reasoning (FineR) that internally leverages the world knowledge of large language models (LLMs) as a proxy in order to reason about fine-grained category names. In detail, to bridge the modality gap between images and LLM, we extract part-level visual attributes from images as text and feed that information to a LLM. Based on the visual attributes and its internal world knowledge the LLM reasons about the subordinate-level category names. Our training-free FineR outperforms several state-of-the-art FGVR and language and vision assistant models and shows promise in working in the wild and in new domains where gathering expert annotation is arduous.
Generative Artificial Intelligence in Healthcare: Ethical Considerations and Assessment Checklist
Nov 02, 2023The widespread use of ChatGPT and other emerging technology powered by generative artificial intelligence (AI) has drawn much attention to potential ethical issues, especially in high-stakes applications such as healthcare. However, less clear is how to resolve such issues beyond following guidelines and regulations that are still under discussion and development. On the other hand, other types of generative AI have been used to synthesize images and other types of data for research and practical purposes, which have resolved some ethical issues and exposed other ethical issues, but such technology is less often the focus of ongoing ethical discussions. Here we highlight gaps in current ethical discussions of generative AI via a systematic scoping review of relevant existing research in healthcare, and reduce the gaps by proposing an ethics checklist for comprehensive assessment and transparent documentation of ethical discussions in generative AI development. While the checklist can be readily integrated into the current peer review and publication system to enhance generative AI research, it may also be used in broader settings to disclose ethics-related considerations in generative AI-powered products (or real-life applications of such products) to help users establish reasonable trust in their capabilities.
SAM-Deblur: Let Segment Anything Boost Image Deblurring
Sep 05, 2023
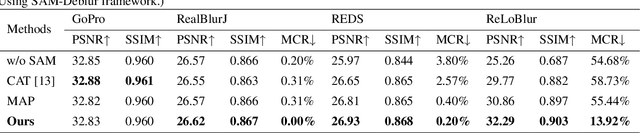

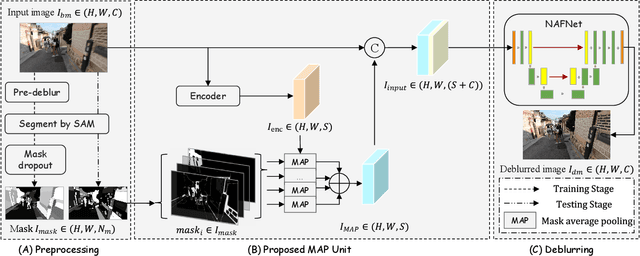
Image deblurring is a critical task in the field of image restoration, aiming to eliminate blurring artifacts. However, the challenge of addressing non-uniform blurring leads to an ill-posed problem, which limits the generalization performance of existing deblurring models. To solve the problem, we propose a framework SAM-Deblur, integrating prior knowledge from the Segment Anything Model (SAM) into the deblurring task for the first time. In particular, SAM-Deblur is divided into three stages. First, We preprocess the blurred images, obtain image masks via SAM, and propose a mask dropout method for training to enhance model robustness. Then, to fully leverage the structural priors generated by SAM, we propose a Mask Average Pooling (MAP) unit specifically designed to average SAM-generated segmented areas, serving as a plug-and-play component which can be seamlessly integrated into existing deblurring networks. Finally, we feed the fused features generated by the MAP Unit into the deblurring model to obtain a sharp image. Experimental results on the RealBlurJ, ReloBlur, and REDS datasets reveal that incorporating our methods improves NAFNet's PSNR by 0.05, 0.96, and 7.03, respectively. Code will be available at \href{https://github.com/HPLQAQ/SAM-Deblur}{SAM-Deblur}.
Spiking-Diffusion: Vector Quantized Discrete Diffusion Model with Spiking Neural Networks
Sep 04, 2023


Spiking neural networks (SNNs) have tremendous potential for energy-efficient neuromorphic chips due to their binary and event-driven architecture. SNNs have been primarily used in classification tasks, but limited exploration on image generation tasks. To fill the gap, we propose a Spiking-Diffusion model, which is based on the vector quantized discrete diffusion model. First, we develop a vector quantized variational autoencoder with SNNs (VQ-SVAE) to learn a discrete latent space for images. In VQ-SVAE, image features are encoded using both the spike firing rate and postsynaptic potential, and an adaptive spike generator is designed to restore embedding features in the form of spike trains. Next, we perform absorbing state diffusion in the discrete latent space and construct a spiking diffusion image decoder (SDID) with SNNs to denoise the image. Our work is the first to build the diffusion model entirely from SNN layers. Experimental results on MNIST, FMNIST, KMNIST, Letters, and Cifar10 demonstrate that Spiking-Diffusion outperforms the existing SNN-based generation model. We achieve FIDs of 37.50, 91.98, 59.23, 67.41, and 120.5 on the above datasets respectively, with reductions of 58.60\%, 18.75\%, 64.51\%, 29.75\%, and 44.88\% in FIDs compared with the state-of-art work. Our code will be available at \url{https://github.com/Arktis2022/Spiking-Diffusion}.
Towards clinical AI fairness: A translational perspective
Apr 26, 2023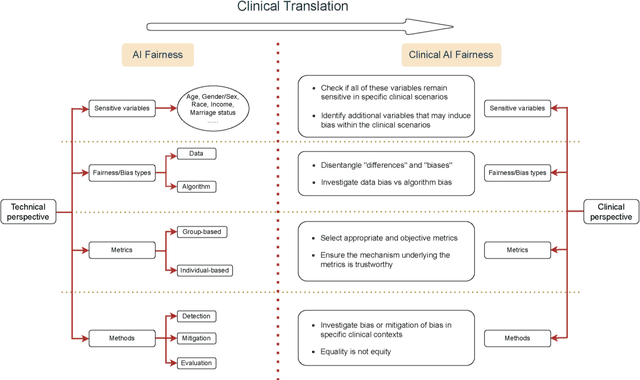
Artificial intelligence (AI) has demonstrated the ability to extract insights from data, but the issue of fairness remains a concern in high-stakes fields such as healthcare. Despite extensive discussion and efforts in algorithm development, AI fairness and clinical concerns have not been adequately addressed. In this paper, we discuss the misalignment between technical and clinical perspectives of AI fairness, highlight the barriers to AI fairness' translation to healthcare, advocate multidisciplinary collaboration to bridge the knowledge gap, and provide possible solutions to address the clinical concerns pertaining to AI fairness.
Large-scale Pre-trained Models are Surprisingly Strong in Incremental Novel Class Discovery
Mar 29, 2023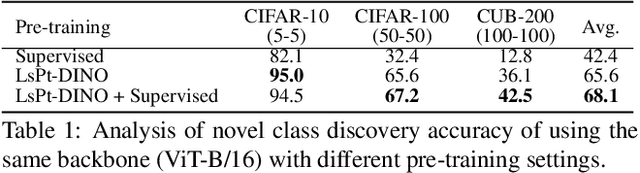
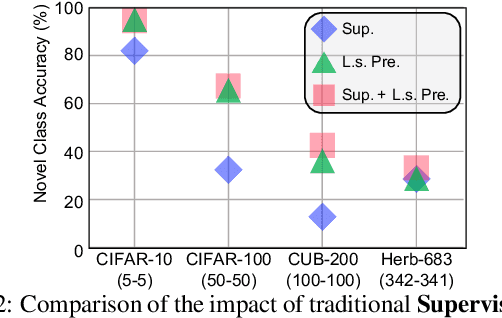

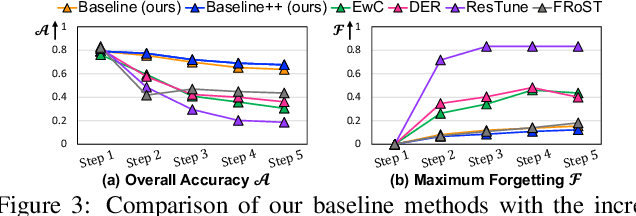
Discovering novel concepts from unlabelled data and in a continuous manner is an important desideratum of lifelong learners. In the literature such problems have been partially addressed under very restricted settings, where either access to labelled data is provided for discovering novel concepts (e.g., NCD) or learning occurs for a limited number of incremental steps (e.g., class-iNCD). In this work we challenge the status quo and propose a more challenging and practical learning paradigm called MSc-iNCD, where learning occurs continuously and unsupervisedly, while exploiting the rich priors from large-scale pre-trained models. To this end, we propose simple baselines that are not only resilient under longer learning scenarios, but are surprisingly strong when compared with sophisticated state-of-the-art methods. We conduct extensive empirical evaluation on a multitude of benchmarks and show the effectiveness of our proposed baselines, which significantly raises the bar.
FedScore: A privacy-preserving framework for federated scoring system development
Mar 01, 2023



We propose FedScore, a privacy-preserving federated learning framework for scoring system generation across multiple sites to facilitate cross-institutional collaborations. The FedScore framework includes five modules: federated variable ranking, federated variable transformation, federated score derivation, federated model selection and federated model evaluation. To illustrate usage and assess FedScore's performance, we built a hypothetical global scoring system for mortality prediction within 30 days after a visit to an emergency department using 10 simulated sites divided from a tertiary hospital in Singapore. We employed a pre-existing score generator to construct 10 local scoring systems independently at each site and we also developed a scoring system using centralized data for comparison. We compared the acquired FedScore model's performance with that of other scoring models using the receiver operating characteristic (ROC) analysis. The FedScore model achieved an average area under the curve (AUC) value of 0.763 across all sites, with a standard deviation (SD) of 0.020. We also calculated the average AUC values and SDs for each local model, and the FedScore model showed promising accuracy and stability with a high average AUC value which was closest to the one of the pooled model and SD which was lower than that of most local models. This study demonstrates that FedScore is a privacy-preserving scoring system generator with potentially good generalizability.