 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWilli Menapace
Harnessing Large Language Models for Training-free Video Anomaly Detection
Apr 01, 2024
Video anomaly detection (VAD) aims to temporally locate abnormal events in a video. Existing works mostly rely on training deep models to learn the distribution of normality with either video-level supervision, one-class supervision, or in an unsupervised setting. Training-based methods are prone to be domain-specific, thus being costly for practical deployment as any domain change will involve data collection and model training. In this paper, we radically depart from previous efforts and propose LAnguage-based VAD (LAVAD), a method tackling VAD in a novel, training-free paradigm, exploiting the capabilities of pre-trained large language models (LLMs) and existing vision-language models (VLMs). We leverage VLM-based captioning models to generate textual descriptions for each frame of any test video. With the textual scene description, we then devise a prompting mechanism to unlock the capability of LLMs in terms of temporal aggregation and anomaly score estimation, turning LLMs into an effective video anomaly detector. We further leverage modality-aligned VLMs and propose effective techniques based on cross-modal similarity for cleaning noisy captions and refining the LLM-based anomaly scores. We evaluate LAVAD on two large datasets featuring real-world surveillance scenarios (UCF-Crime and XD-Violence), showing that it outperforms both unsupervised and one-class methods without requiring any training or data collection.
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
Feb 29, 2024The quality of the data and annotation upper-bounds the quality of a downstream model. While there exist large text corpora and image-text pairs, high-quality video-text data is much harder to collect. First of all, manual labeling is more time-consuming, as it requires an annotator to watch an entire video. Second, videos have a temporal dimension, consisting of several scenes stacked together, and showing multiple actions. Accordingly, to establish a video dataset with high-quality captions, we propose an automatic approach leveraging multimodal inputs, such as textual video description, subtitles, and individual video frames. Specifically, we curate 3.8M high-resolution videos from the publicly available HD-VILA-100M dataset. We then split them into semantically consistent video clips, and apply multiple cross-modality teacher models to obtain captions for each video. Next, we finetune a retrieval model on a small subset where the best caption of each video is manually selected and then employ the model in the whole dataset to select the best caption as the annotation. In this way, we get 70M videos paired with high-quality text captions. We dub the dataset as Panda-70M. We show the value of the proposed dataset on three downstream tasks: video captioning, video and text retrieval, and text-driven video generation. The models trained on the proposed data score substantially better on the majority of metrics across all the tasks.
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
Feb 22, 2024Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net - a workhorse behind image generation - scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. See our website at https://snap-research.github.io/snapvideo/.
Collaborative Neural Painting
Dec 04, 2023The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users' modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.
Delving into CLIP latent space for Video Anomaly Recognition
Oct 04, 2023



We tackle the complex problem of detecting and recognising anomalies in surveillance videos at the frame level, utilising only video-level supervision. We introduce the novel method AnomalyCLIP, the first to combine Large Language and Vision (LLV) models, such as CLIP, with multiple instance learning for joint video anomaly detection and classification. Our approach specifically involves manipulating the latent CLIP feature space to identify the normal event subspace, which in turn allows us to effectively learn text-driven directions for abnormal events. When anomalous frames are projected onto these directions, they exhibit a large feature magnitude if they belong to a particular class. We also introduce a computationally efficient Transformer architecture to model short- and long-term temporal dependencies between frames, ultimately producing the final anomaly score and class prediction probabilities. We compare AnomalyCLIP against state-of-the-art methods considering three major anomaly detection benchmarks, i.e. ShanghaiTech, UCF-Crime, and XD-Violence, and empirically show that it outperforms baselines in recognising video anomalies.
Interactive Neural Painting
Jul 31, 2023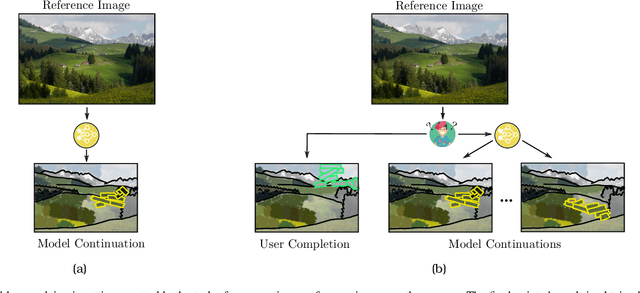
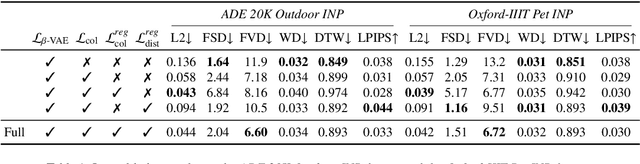
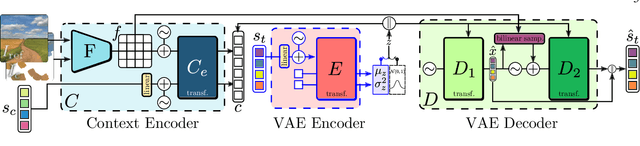
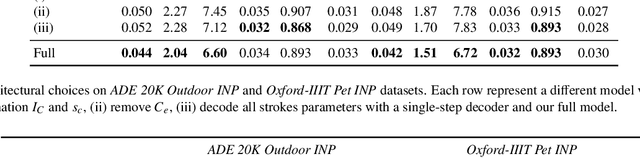
In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
Quantum Multi-Model Fitting
Mar 27, 2023



Geometric model fitting is a challenging but fundamental computer vision problem. Recently, quantum optimization has been shown to enhance robust fitting for the case of a single model, while leaving the question of multi-model fitting open. In response to this challenge, this paper shows that the latter case can significantly benefit from quantum hardware and proposes the first quantum approach to multi-model fitting (MMF). We formulate MMF as a problem that can be efficiently sampled by modern adiabatic quantum computers without the relaxation of the objective function. We also propose an iterative and decomposed version of our method, which supports real-world-sized problems. The experimental evaluation demonstrates promising results on a variety of datasets. The source code is available at: https://github.com/FarinaMatteo/qmmf.
Plotting Behind the Scenes: Towards Learnable Game Engines
Mar 23, 2023



Game engines are powerful tools in computer graphics. Their power comes at the immense cost of their development. In this work, we present a framework to train game-engine-like neural models, solely from monocular annotated videos. The result-a Learnable Game Engine (LGE)-maintains states of the scene, objects and agents in it, and enables rendering the environment from a controllable viewpoint. Similarly to a game engine, it models the logic of the game and the underlying rules of physics, to make it possible for a user to play the game by specifying both high- and low-level action sequences. Most captivatingly, our LGE unlocks the director's mode, where the game is played by plotting behind the scenes, specifying high-level actions and goals for the agents in the form of language and desired states. This requires learning "game AI", encapsulated by our animation model, to navigate the scene using high-level constraints, play against an adversary, devise the strategy to win a point. The key to learning such game AI is the exploitation of a large and diverse text corpus, collected in this work, describing detailed actions in a game and used to train our animation model. To render the resulting state of the environment and its agents, we use a compositional NeRF representation used in our synthesis model. To foster future research, we present newly collected, annotated and calibrated large-scale Tennis and Minecraft datasets. Our method significantly outperforms existing neural video game simulators in terms of rendering quality. Besides, our LGEs unlock applications beyond capabilities of the current state of the art. Our framework, data, and models are available at https://learnable-game-engines.github.io/lge-website.
Unsupervised Volumetric Animation
Jan 26, 2023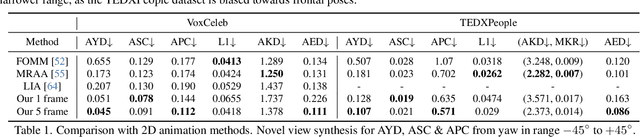
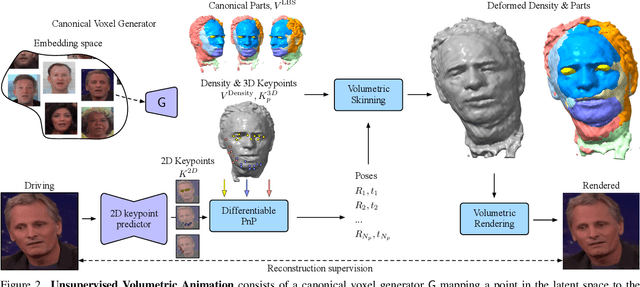
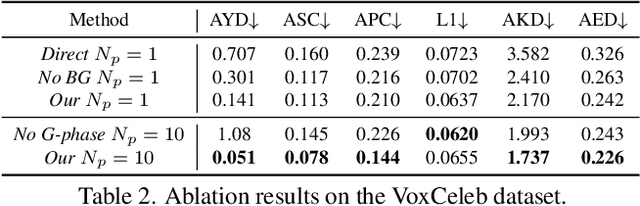

We propose a novel approach for unsupervised 3D animation of non-rigid deformable objects. Our method learns the 3D structure and dynamics of objects solely from single-view RGB videos, and can decompose them into semantically meaningful parts that can be tracked and animated. Using a 3D autodecoder framework, paired with a keypoint estimator via a differentiable PnP algorithm, our model learns the underlying object geometry and parts decomposition in an entirely unsupervised manner. This allows it to perform 3D segmentation, 3D keypoint estimation, novel view synthesis, and animation. We primarily evaluate the framework on two video datasets: VoxCeleb $256^2$ and TEDXPeople $256^2$. In addition, on the Cats $256^2$ image dataset, we show it even learns compelling 3D geometry from still images. Finally, we show our model can obtain animatable 3D objects from a single or few images. Code and visual results available on our project website, see https://snap-research.github.io/unsupervised-volumetric-animation .
InfiniCity: Infinite-Scale City Synthesis
Jan 23, 2023
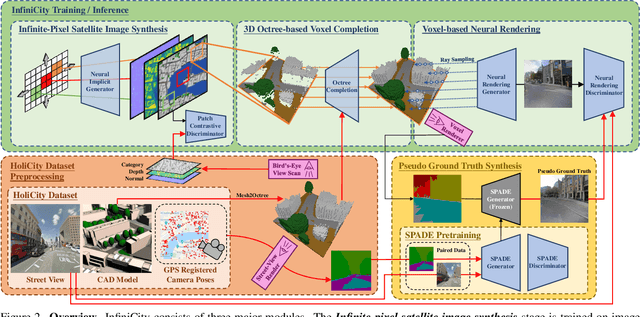


Toward infinite-scale 3D city synthesis, we propose a novel framework, InfiniCity, which constructs and renders an unconstrainedly large and 3D-grounded environment from random noises. InfiniCity decomposes the seemingly impractical task into three feasible modules, taking advantage of both 2D and 3D data. First, an infinite-pixel image synthesis module generates arbitrary-scale 2D maps from the bird's-eye view. Next, an octree-based voxel completion module lifts the generated 2D map to 3D octrees. Finally, a voxel-based neural rendering module texturizes the voxels and renders 2D images. InfiniCity can thus synthesize arbitrary-scale and traversable 3D city environments, and allow flexible and interactive editing from users. We quantitatively and qualitatively demonstrate the efficacy of the proposed framework. Project page: https://hubert0527.github.io/infinicity/