 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStéphane Lathuilière
Source-Guided Similarity Preservation for Online Person Re-Identification
Feb 23, 2024
Online Unsupervised Domain Adaptation (OUDA) for person Re-Identification (Re-ID) is the task of continuously adapting a model trained on a well-annotated source domain dataset to a target domain observed as a data stream. In OUDA, person Re-ID models face two main challenges: catastrophic forgetting and domain shift. In this work, we propose a new Source-guided Similarity Preservation (S2P) framework to alleviate these two problems. Our framework is based on the extraction of a support set composed of source images that maximizes the similarity with the target data. This support set is used to identify feature similarities that must be preserved during the learning process. S2P can incorporate multiple existing UDA methods to mitigate catastrophic forgetting. Our experiments show that S2P outperforms previous state-of-the-art methods on multiple real-to-real and synthetic-to-real challenging OUDA benchmarks.
Collaborating Foundation models for Domain Generalized Semantic Segmentation
Dec 15, 2023Domain Generalized Semantic Segmentation (DGSS) deals with training a model on a labeled source domain with the aim of generalizing to unseen domains during inference. Existing DGSS methods typically effectuate robust features by means of Domain Randomization (DR). Such an approach is often limited as it can only account for style diversification and not content. In this work, we take an orthogonal approach to DGSS and propose to use an assembly of CoLlaborative FOUndation models for Domain Generalized Semantic Segmentation (CLOUDS). In detail, CLOUDS is a framework that integrates FMs of various kinds: (i) CLIP backbone for its robust feature representation, (ii) generative models to diversify the content, thereby covering various modes of the possible target distribution, and (iii) Segment Anything Model (SAM) for iteratively refining the predictions of the segmentation model. Extensive experiments show that our CLOUDS excels in adapting from synthetic to real DGSS benchmarks and under varying weather conditions, notably outperforming prior methods by 5.6% and 6.7% on averaged miou, respectively. The code is available at : https://github.com/yasserben/CLOUDS
Weighted Ensemble Models Are Strong Continual Learners
Dec 14, 2023In this work, we study the problem of continual learning (CL) where the goal is to learn a model on a sequence of tasks, such that the data from the previous tasks becomes unavailable while learning on the current task data. CL is essentially a balancing act between being able to learn on the new task (i.e., plasticity) and maintaining the performance on the previously learned concepts (i.e., stability). With an aim to address the stability-plasticity trade-off, we propose to perform weight-ensembling of the model parameters of the previous and current task. This weight-ensembled model, which we call Continual Model Averaging (or CoMA), attains high accuracy on the current task by leveraging plasticity, while not deviating too far from the previous weight configuration, ensuring stability. We also propose an improved variant of CoMA, named Continual Fisher-weighted Model Averaging (or CoFiMA), that selectively weighs each parameter in the weight ensemble by leveraging the Fisher information of the weights of the model. Both the variants are conceptually simple, easy to implement, and effective in attaining state-of-the-art performance on several standard CL benchmarks.
Mini but Mighty: Finetuning ViTs with Mini Adapters
Nov 07, 2023Vision Transformers (ViTs) have become one of the dominant architectures in computer vision, and pre-trained ViT models are commonly adapted to new tasks via fine-tuning. Recent works proposed several parameter-efficient transfer learning methods, such as adapters, to avoid the prohibitive training and storage cost of finetuning. In this work, we observe that adapters perform poorly when the dimension of adapters is small, and we propose MiMi, a training framework that addresses this issue. We start with large adapters which can reach high performance, and iteratively reduce their size. To enable automatic estimation of the hidden dimension of every adapter, we also introduce a new scoring function, specifically designed for adapters, that compares the neuron importance across layers. Our method outperforms existing methods in finding the best trade-off between accuracy and trained parameters across the three dataset benchmarks DomainNet, VTAB, and Multi-task, for a total of 29 datasets.
Rethinking Class-incremental Learning in the Era of Large Pre-trained Models via Test-Time Adaptation
Oct 17, 2023Class-incremental learning (CIL) is a challenging task that involves continually learning to categorize classes into new tasks without forgetting previously learned information. The advent of the large pre-trained models (PTMs) has fast-tracked the progress in CIL due to the highly transferable PTM representations, where tuning a small set of parameters results in state-of-the-art performance when compared with the traditional CIL methods that are trained from scratch. However, repeated fine-tuning on each task destroys the rich representations of the PTMs and further leads to forgetting previous tasks. To strike a balance between the stability and plasticity of PTMs for CIL, we propose a novel perspective of eliminating training on every new task and instead performing test-time adaptation (TTA) directly on the test instances. Concretely, we propose "Test-Time Adaptation for Class-Incremental Learning" (TTACIL) that first fine-tunes Layer Norm parameters of the PTM on each test instance for learning task-specific features, and then resets them back to the base model to preserve stability. As a consequence, TTACIL does not undergo any forgetting, while benefiting each task with the rich PTM features. Additionally, by design, our method is robust to common data corruptions. Our TTACIL outperforms several state-of-the-art CIL methods when evaluated on multiple CIL benchmarks under both clean and corrupted data.
Towards image compression with perfect realism at ultra-low bitrates
Oct 16, 2023Image codecs are typically optimized to trade-off bitrate vs, distortion metrics. At low bitrates, this leads to compression artefacts which are easily perceptible, even when training with perceptual or adversarial losses. To improve image quality, and to make it less dependent on the bitrate, we propose to decode with iterative diffusion models, instead of feed-forward decoders trained using MSE or LPIPS distortions used in most neural codecs. In addition to conditioning the model on a vector-quantized image representation, we also condition on a global textual image description to provide additional context. We dub our model PerCo for 'perceptual compression', and compare it to state-of-the-art codecs at rates from 0.1 down to 0.003 bits per pixel. The latter rate is an order of magnitude smaller than those considered in most prior work. At this bitrate a 512x768 Kodak image is encoded in less than 153 bytes. Despite this ultra-low bitrate, our approach maintains the ability to reconstruct realistic images. We find that our model leads to reconstructions with state-of-the-art visual quality as measured by FID and KID, and that the visual quality is less dependent on the bitrate than previous methods.
Face Aging via Diffusion-based Editing
Sep 20, 2023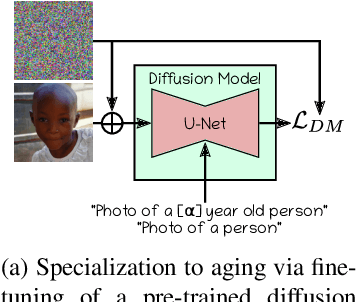
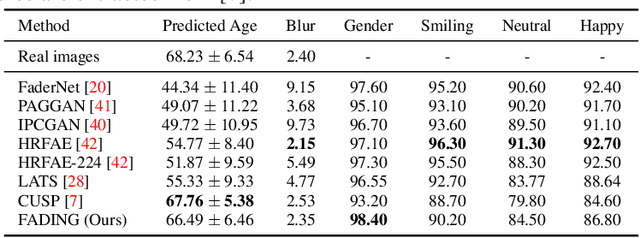


In this paper, we address the problem of face aging: generating past or future facial images by incorporating age-related changes to the given face. Previous aging methods rely solely on human facial image datasets and are thus constrained by their inherent scale and bias. This restricts their application to a limited generatable age range and the inability to handle large age gaps. We propose FADING, a novel approach to address Face Aging via DIffusion-based editiNG. We go beyond existing methods by leveraging the rich prior of large-scale language-image diffusion models. First, we specialize a pre-trained diffusion model for the task of face age editing by using an age-aware fine-tuning scheme. Next, we invert the input image to latent noise and obtain optimized null text embeddings. Finally, we perform text-guided local age editing via attention control. The quantitative and qualitative analyses demonstrate that our method outperforms existing approaches with respect to aging accuracy, attribute preservation, and aging quality.
The Unreasonable Effectiveness of Large Language-Vision Models for Source-free Video Domain Adaptation
Aug 22, 2023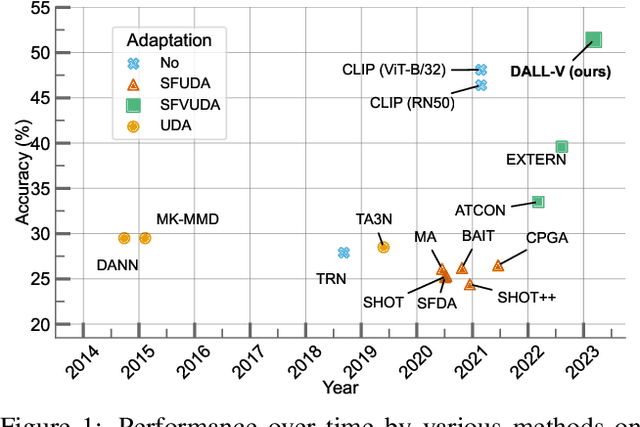
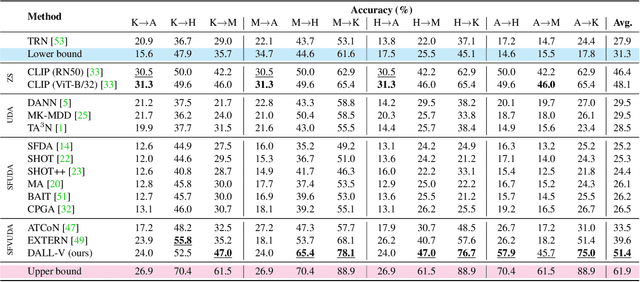
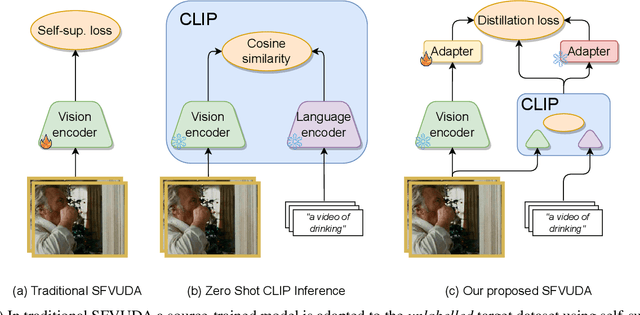
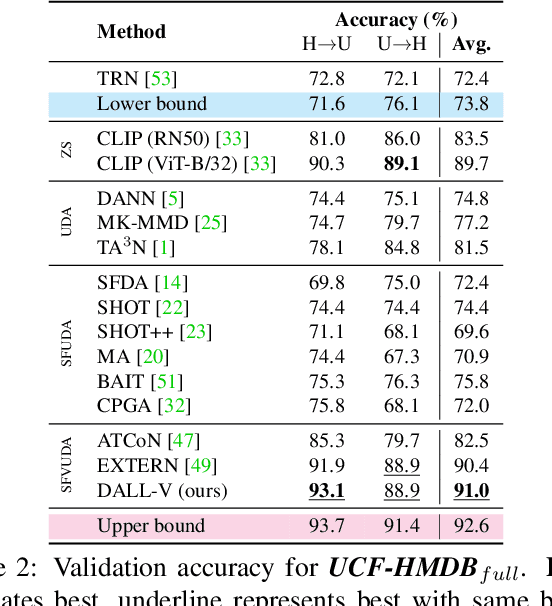
Source-Free Video Unsupervised Domain Adaptation (SFVUDA) task consists in adapting an action recognition model, trained on a labelled source dataset, to an unlabelled target dataset, without accessing the actual source data. The previous approaches have attempted to address SFVUDA by leveraging self-supervision (e.g., enforcing temporal consistency) derived from the target data itself. In this work, we take an orthogonal approach by exploiting "web-supervision" from Large Language-Vision Models (LLVMs), driven by the rationale that LLVMs contain a rich world prior surprisingly robust to domain-shift. We showcase the unreasonable effectiveness of integrating LLVMs for SFVUDA by devising an intuitive and parameter-efficient method, which we name Domain Adaptation with Large Language-Vision models (DALL-V), that distills the world prior and complementary source model information into a student network tailored for the target. Despite the simplicity, DALL-V achieves significant improvement over state-of-the-art SFVUDA methods.
Predictive Coding For Animation-Based Video Compression
Jul 09, 2023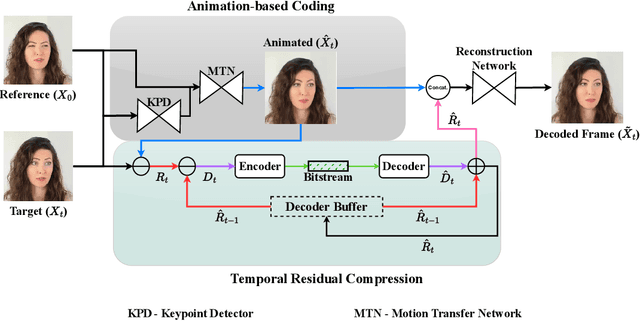
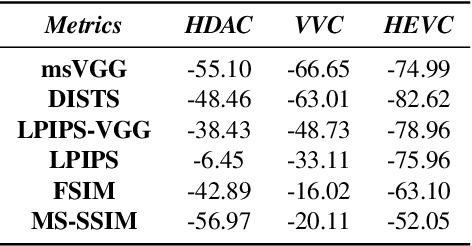
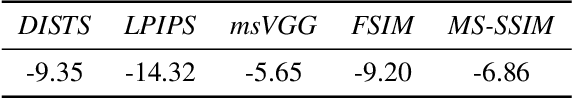

We address the problem of efficiently compressing video for conferencing-type applications. We build on recent approaches based on image animation, which can achieve good reconstruction quality at very low bitrate by representing face motions with a compact set of sparse keypoints. However, these methods encode video in a frame-by-frame fashion, i.e. each frame is reconstructed from a reference frame, which limits the reconstruction quality when the bandwidth is larger. Instead, we propose a predictive coding scheme which uses image animation as a predictor, and codes the residual with respect to the actual target frame. The residuals can be in turn coded in a predictive manner, thus removing efficiently temporal dependencies. Our experiments indicate a significant bitrate gain, in excess of 70% compared to the HEVC video standard and over 30% compared to VVC, on a datasetof talking-head videos