 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXingqian Xu
OpenBias: Open-set Bias Detection in Text-to-Image Generative Models
Apr 11, 2024
Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Smooth Diffusion: Crafting Smooth Latent Spaces in Diffusion Models
Dec 07, 2023Recently, diffusion models have made remarkable progress in text-to-image (T2I) generation, synthesizing images with high fidelity and diverse contents. Despite this advancement, latent space smoothness within diffusion models remains largely unexplored. Smooth latent spaces ensure that a perturbation on an input latent corresponds to a steady change in the output image. This property proves beneficial in downstream tasks, including image interpolation, inversion, and editing. In this work, we expose the non-smoothness of diffusion latent spaces by observing noticeable visual fluctuations resulting from minor latent variations. To tackle this issue, we propose Smooth Diffusion, a new category of diffusion models that can be simultaneously high-performing and smooth. Specifically, we introduce Step-wise Variation Regularization to enforce the proportion between the variations of an arbitrary input latent and that of the output image is a constant at any diffusion training step. In addition, we devise an interpolation standard deviation (ISTD) metric to effectively assess the latent space smoothness of a diffusion model. Extensive quantitative and qualitative experiments demonstrate that Smooth Diffusion stands out as a more desirable solution not only in T2I generation but also across various downstream tasks. Smooth Diffusion is implemented as a plug-and-play Smooth-LoRA to work with various community models. Code is available at https://github.com/SHI-Labs/Smooth-Diffusion.
Interactive Neural Painting
Jul 31, 2023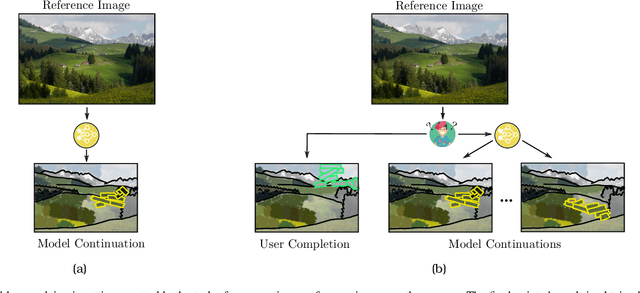
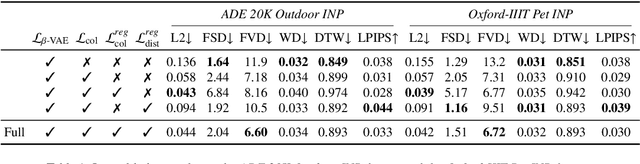
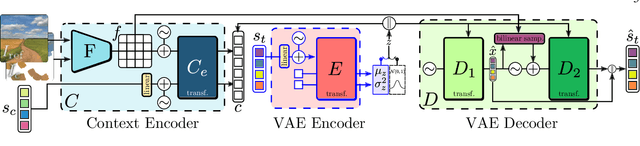
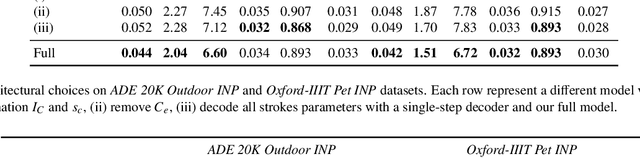
In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the users creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art. Additional details, code and examples are available at https://helia95.github.io/inp-website.
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Jul 20, 2023

Have you ever imagined how it would look if we placed new objects into paintings? For example, what would it look like if we placed a basketball into Claude Monet's ``Water Lilies, Evening Effect''? We propose Reference-based Painterly Inpainting, a novel task that crosses the wild reference domain gap and implants novel objects into artworks. Although previous works have examined reference-based inpainting, they are not designed for large domain discrepancies between the target and the reference, such as inpainting an artistic image using a photorealistic reference. This paper proposes a novel diffusion framework, dubbed RefPaint, to ``inpaint more wildly'' by taking such references with large domain gaps. Built with an image-conditioned diffusion model, we introduce a ladder-side branch and a masked fusion mechanism to work with the inpainting mask. By decomposing the CLIP image embeddings at inference time, one can manipulate the strength of semantic and style information with ease. Experiments demonstrate that our proposed RefPaint framework produces significantly better results than existing methods. Our method enables creative painterly image inpainting with reference objects that would otherwise be difficult to achieve. Project page: https://vita-group.github.io/RefPaint/
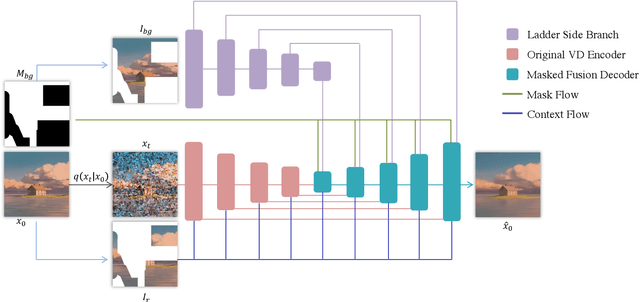
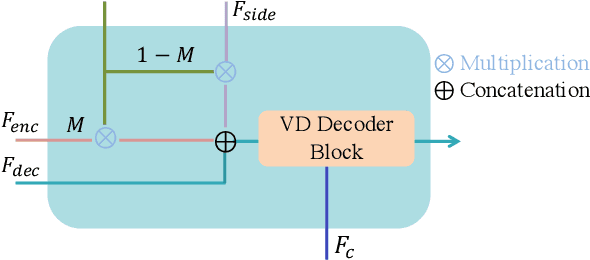
Prompt-Free Diffusion: Taking "Text" out of Text-to-Image Diffusion Models
May 25, 2023
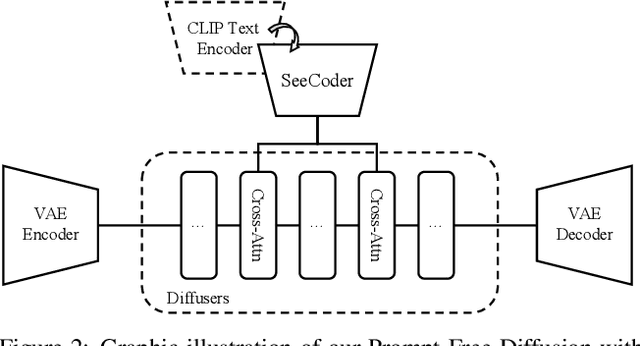
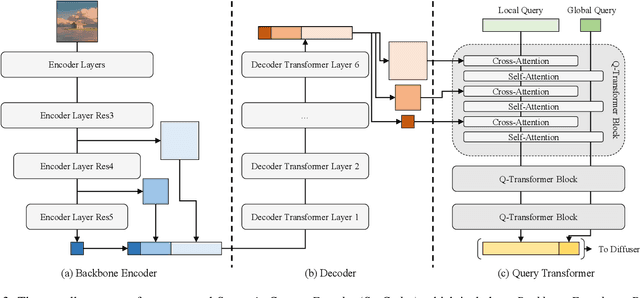

Text-to-image (T2I) research has grown explosively in the past year, owing to the large-scale pre-trained diffusion models and many emerging personalization and editing approaches. Yet, one pain point persists: the text prompt engineering, and searching high-quality text prompts for customized results is more art than science. Moreover, as commonly argued: "an image is worth a thousand words" - the attempt to describe a desired image with texts often ends up being ambiguous and cannot comprehensively cover delicate visual details, hence necessitating more additional controls from the visual domain. In this paper, we take a bold step forward: taking "Text" out of a pre-trained T2I diffusion model, to reduce the burdensome prompt engineering efforts for users. Our proposed framework, Prompt-Free Diffusion, relies on only visual inputs to generate new images: it takes a reference image as "context", an optional image structural conditioning, and an initial noise, with absolutely no text prompt. The core architecture behind the scene is Semantic Context Encoder (SeeCoder), substituting the commonly used CLIP-based or LLM-based text encoder. The reusability of SeeCoder also makes it a convenient drop-in component: one can also pre-train a SeeCoder in one T2I model and reuse it for another. Through extensive experiments, Prompt-Free Diffusion is experimentally found to (i) outperform prior exemplar-based image synthesis approaches; (ii) perform on par with state-of-the-art T2I models using prompts following the best practice; and (iii) be naturally extensible to other downstream applications such as anime figure generation and virtual try-on, with promising quality. Our code and models are open-sourced at https://github.com/SHI-Labs/Prompt-Free-Diffusion.
Zero-shot Generative Model Adaptation via Image-specific Prompt Learning
Apr 06, 2023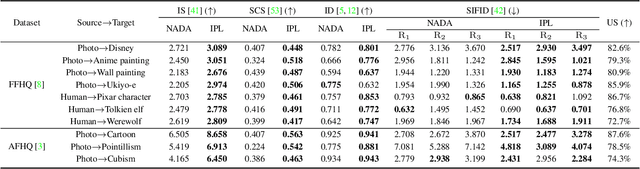
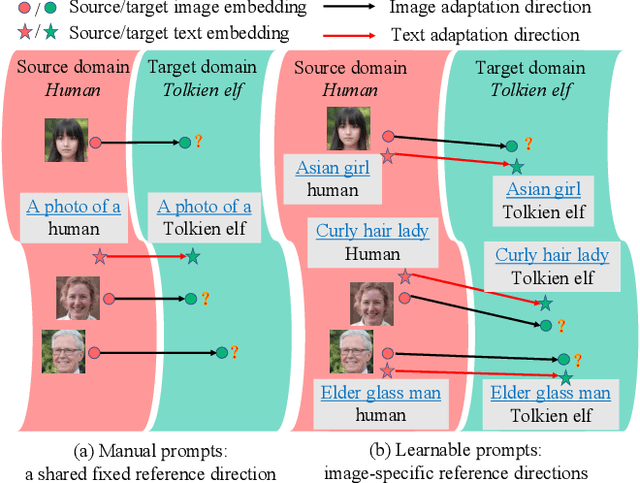
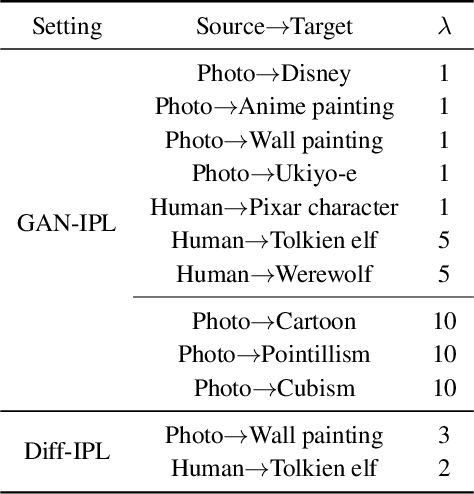
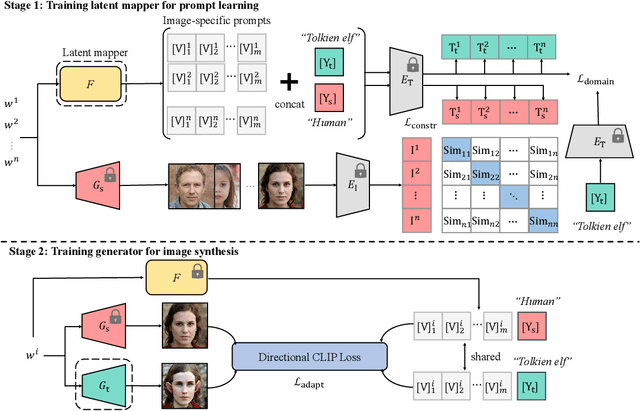
Recently, CLIP-guided image synthesis has shown appealing performance on adapting a pre-trained source-domain generator to an unseen target domain. It does not require any target-domain samples but only the textual domain labels. The training is highly efficient, e.g., a few minutes. However, existing methods still have some limitations in the quality of generated images and may suffer from the mode collapse issue. A key reason is that a fixed adaptation direction is applied for all cross-domain image pairs, which leads to identical supervision signals. To address this issue, we propose an Image-specific Prompt Learning (IPL) method, which learns specific prompt vectors for each source-domain image. This produces a more precise adaptation direction for every cross-domain image pair, endowing the target-domain generator with greatly enhanced flexibility. Qualitative and quantitative evaluations on various domains demonstrate that IPL effectively improves the quality and diversity of synthesized images and alleviates the mode collapse. Moreover, IPL is independent of the structure of the generative model, such as generative adversarial networks or diffusion models. Code is available at https://github.com/Picsart-AI-Research/IPL-Zero-Shot-Generative-Model-Adaptation.
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
Mar 30, 2023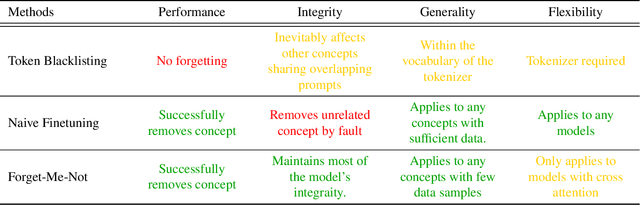
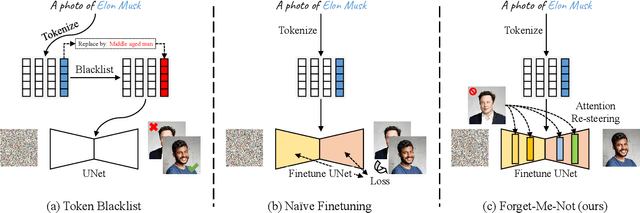
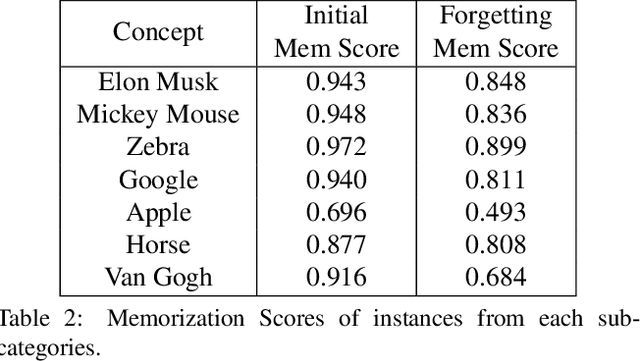
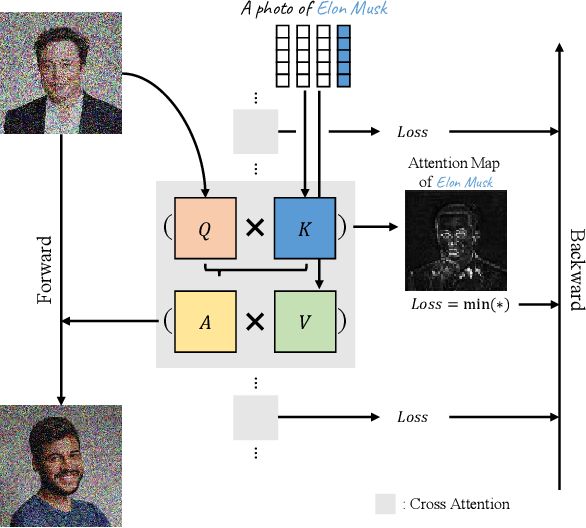
The unlearning problem of deep learning models, once primarily an academic concern, has become a prevalent issue in the industry. The significant advances in text-to-image generation techniques have prompted global discussions on privacy, copyright, and safety, as numerous unauthorized personal IDs, content, artistic creations, and potentially harmful materials have been learned by these models and later utilized to generate and distribute uncontrolled content. To address this challenge, we propose \textbf{Forget-Me-Not}, an efficient and low-cost solution designed to safely remove specified IDs, objects, or styles from a well-configured text-to-image model in as little as 30 seconds, without impairing its ability to generate other content. Alongside our method, we introduce the \textbf{Memorization Score (M-Score)} and \textbf{ConceptBench} to measure the models' capacity to generate general concepts, grouped into three primary categories: ID, object, and style. Using M-Score and ConceptBench, we demonstrate that Forget-Me-Not can effectively eliminate targeted concepts while maintaining the model's performance on other concepts. Furthermore, Forget-Me-Not offers two practical extensions: a) removal of potentially harmful or NSFW content, and b) enhancement of model accuracy, inclusion and diversity through \textbf{concept correction and disentanglement}. It can also be adapted as a lightweight model patch for Stable Diffusion, allowing for concept manipulation and convenient distribution. To encourage future research in this critical area and promote the development of safe and inclusive generative models, we will open-source our code and ConceptBench at \href{https://github.com/SHI-Labs/Forget-Me-Not}{https://github.com/SHI-Labs/Forget-Me-Not}.
Versatile Diffusion: Text, Images and Variations All in One Diffusion Model
Nov 20, 2022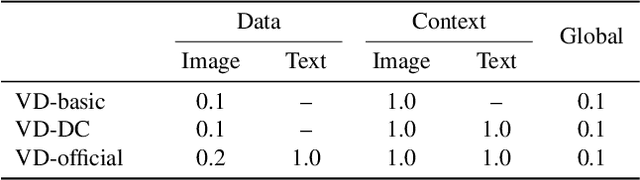
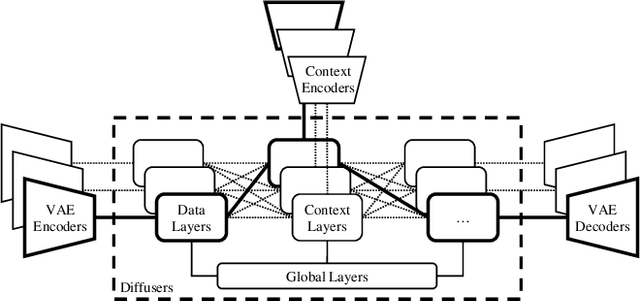
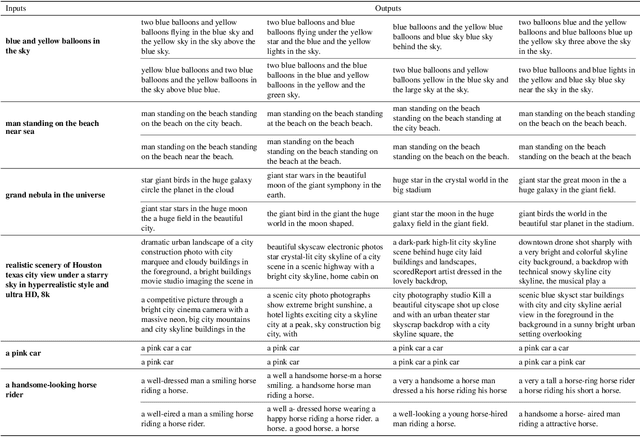
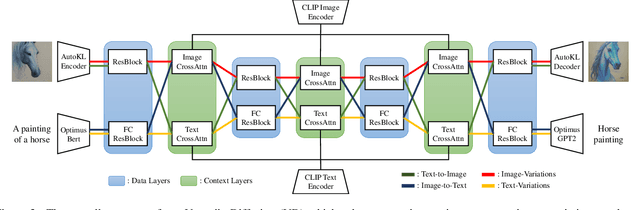
The recent advances in diffusion models have set an impressive milestone in many generation tasks. Trending works such as DALL-E2, Imagen, and Stable Diffusion have attracted great interest in academia and industry. Despite the rapid landscape changes, recent new approaches focus on extensions and performance rather than capacity, thus requiring separate models for separate tasks. In this work, we expand the existing single-flow diffusion pipeline into a multi-flow network, dubbed Versatile Diffusion (VD), that handles text-to-image, image-to-text, image-variation, and text-variation in one unified model. Moreover, we generalize VD to a unified multi-flow multimodal diffusion framework with grouped layers, swappable streams, and other propositions that can process modalities beyond images and text. Through our experiments, we demonstrate that VD and its underlying framework have the following merits: a) VD handles all subtasks with competitive quality; b) VD initiates novel extensions and applications such as disentanglement of style and semantic, image-text dual-guided generation, etc.; c) Through these experiments and applications, VD provides more semantic insights of the generated outputs. Our code and models are open-sourced at https://github.com/SHI-Labs/Versatile-Diffusion.
StyleNAT: Giving Each Head a New Perspective
Nov 10, 2022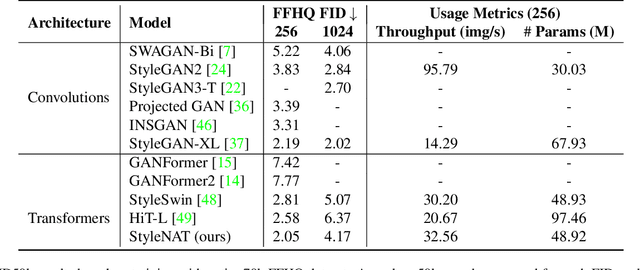
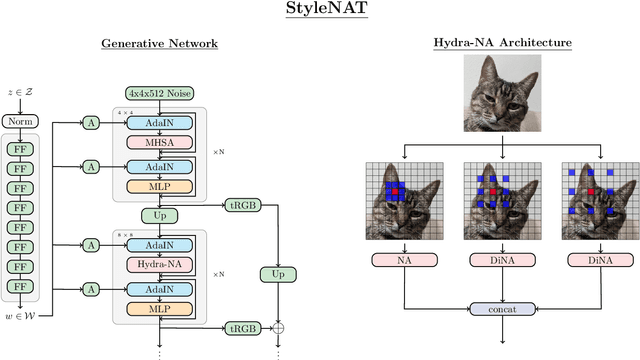
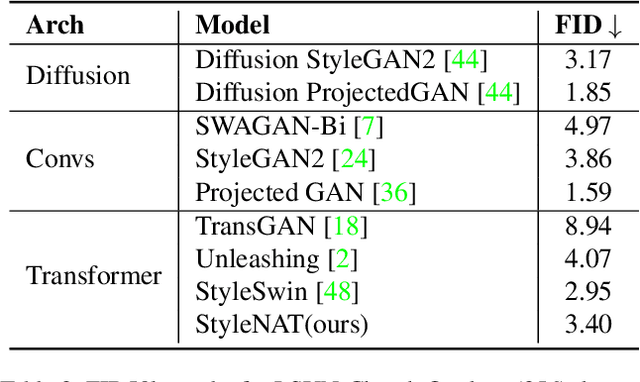
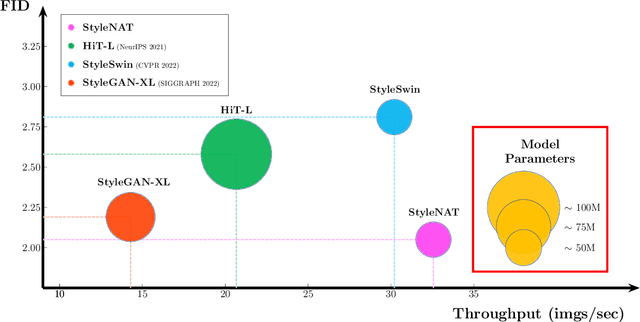
Image generation has been a long sought-after but challenging task, and performing the generation task in an efficient manner is similarly difficult. Often researchers attempt to create a "one size fits all" generator, where there are few differences in the parameter space for drastically different datasets. Herein, we present a new transformer-based framework, dubbed StyleNAT, targeting high-quality image generation with superior efficiency and flexibility. At the core of our model, is a carefully designed framework that partitions attention heads to capture local and global information, which is achieved through using Neighborhood Attention (NA). With different heads able to pay attention to varying receptive fields, the model is able to better combine this information, and adapt, in a highly flexible manner, to the data at hand. StyleNAT attains a new SOTA FID score on FFHQ-256 with 2.046, beating prior arts with convolutional models such as StyleGAN-XL and transformers such as HIT and StyleSwin, and a new transformer SOTA on FFHQ-1024 with an FID score of 4.174. These results show a 6.4% improvement on FFHQ-256 scores when compared to StyleGAN-XL with a 28% reduction in the number of parameters and 56% improvement in sampling throughput. Code and models will be open-sourced at https://github.com/SHI-Labs/StyleNAT .