 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYifan Jiang
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
Apr 24, 2024
While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.
SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense
Apr 22, 2024While vertical thinking relies on logical and commonsense reasoning, lateral thinking requires systems to defy commonsense associations and overwrite them through unconventional thinking. Lateral thinking has been shown to be challenging for current models but has received little attention. A recent benchmark, BRAINTEASER, aims to evaluate current models' lateral thinking ability in a zero-shot setting. In this paper, we split the original benchmark to also support fine-tuning setting and present SemEval Task 9: BRAIN-TEASER(S), the first task at this competition designed to test the system's reasoning and lateral thinking ability. As a popular task, BRAINTEASER(S)'s two subtasks receive 483 team submissions from 182 participants during the competition. This paper provides a fine-grained system analysis of the competition results, together with a reflection on what this means for the ability of the systems to reason laterally. We hope that the BRAINTEASER(S) subtasks and findings in this paper can stimulate future work on lateral thinking and robust reasoning by computational models.
TrafPS: A Shapley-based Visual Analytics Approach to Interpret Traffic
Mar 07, 2024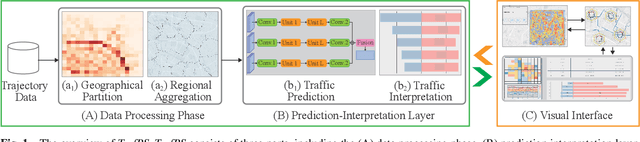

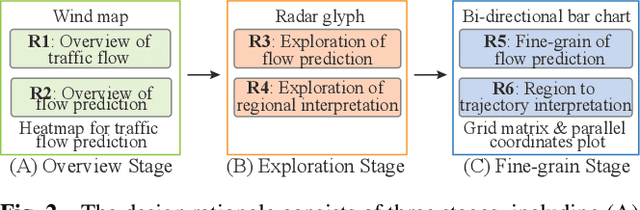

Recent achievements in deep learning (DL) have shown its potential for predicting traffic flows. Such predictions are beneficial for understanding the situation and making decisions in traffic control. However, most state-of-the-art DL models are considered "black boxes" with little to no transparency for end users with respect to the underlying mechanisms. Some previous work tried to "open the black boxes" and increase the interpretability of how predictions are generated. However, it still remains challenging to handle complex models on large-scale spatio-temporal data and discover salient spatial and temporal patterns that significantly influence traffic flows. To overcome the challenges, we present TrafPS, a visual analytics approach for interpreting traffic prediction outcomes to support decision-making in traffic management and urban planning. The measurements, region SHAP and trajectory SHAP, are proposed to quantify the impact of flow patterns on urban traffic at different levels. Based on the task requirement from the domain experts, we employ an interactive visual interface for multi-aspect exploration and analysis of significant flow patterns. Two real-world case studies demonstrate the effectiveness of TrafPS in identifying key routes and decision-making support for urban planning.
The Curious Case of Nonverbal Abstract Reasoning with Multi-Modal Large Language Models
Jan 22, 2024While large language models (LLMs) are still being adopted to new domains and utilized in novel applications, we are experiencing an influx of the new generation of foundation models, namely multi-modal large language models (MLLMs). These models integrate verbal and visual information, opening new possibilities to demonstrate more complex reasoning abilities at the intersection of the two modalities. However, despite the revolutionizing prospect of MLLMs, our understanding of their reasoning abilities is limited. In this study, we assess the nonverbal abstract reasoning abilities of open-source and closed-source MLLMs using variations of Raven's Progressive Matrices. Our experiments expose the difficulty of solving such problems while showcasing the immense gap between open-source and closed-source models. We also reveal critical shortcomings with individual visual and textual modules, subjecting the models to low-performance ceilings. Finally, to improve MLLMs' performance, we experiment with various methods, such as Chain-of-Thought prompting, resulting in a significant (up to 100%) boost in performance.
UAV-enabled Integrated Sensing and Communication: Tracking Design and Optimization
Jan 15, 2024Integrated sensing and communications (ISAC) enabled by unmanned aerial vehicles (UAVs) is a promising technology to facilitate target tracking applications. In contrast to conventional UAV-based ISAC system designs that mainly focus on estimating the target position, the target velocity estimation also needs to be considered due to its crucial impacts on link maintenance and real-time response, which requires new designs on resource allocation and tracking scheme. In this paper, we propose an extended Kalman filtering-based tracking scheme for a UAV-enabled ISAC system where a UAV tracks a moving object and also communicates with a device attached to the object. Specifically, a weighted sum of predicted posterior Cram\'er-Rao bound (PCRB) for object relative position and velocity estimation is minimized by optimizing the UAV trajectory, where an efficient solution is obtained based on the successive convex approximation method. Furthermore, under a special case with the measurement mean square error (MSE), the optimal relative motion state is obtained and proved to keep a fixed elevation angle and zero relative velocity. Numerical results validate that the obtained solution to the predicted PCRB minimization can be approximated by the optimal relative motion state when predicted measurement MSE dominates the predicted PCRBs, as well as the effectiveness of the proposed tracking scheme. Moreover, three interesting trade-offs on system performance resulted from the fixed elevation angle are illustrated.
VASE: Object-Centric Appearance and Shape Manipulation of Real Videos
Jan 04, 2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object's appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities. Further details, code and examples are available on our project page: https://helia95.github.io/vase-website/
Efficient-NeRF2NeRF: Streamlining Text-Driven 3D Editing with Multiview Correspondence-Enhanced Diffusion Models
Dec 26, 2023
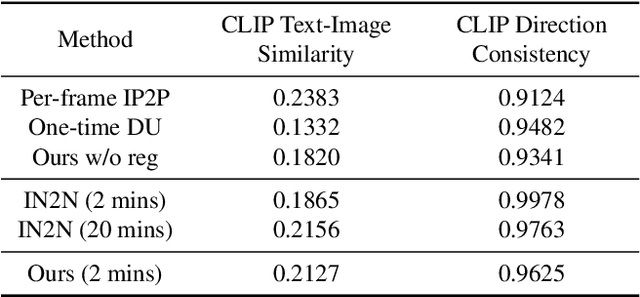
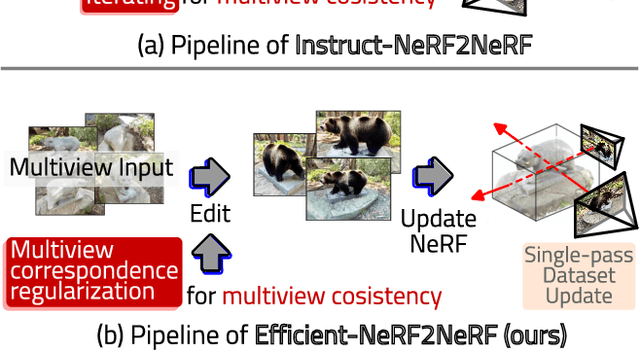
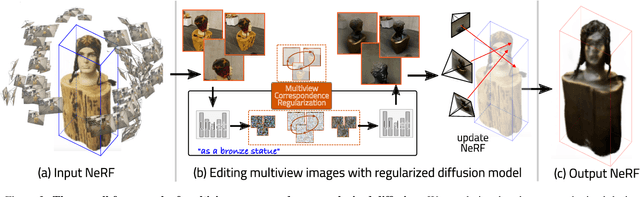
The advancement of text-driven 3D content editing has been blessed by the progress from 2D generative diffusion models. However, a major obstacle hindering the widespread adoption of 3D content editing is its time-intensive processing. This challenge arises from the iterative and refining steps required to achieve consistent 3D outputs from 2D image-based generative models. Recent state-of-the-art methods typically require optimization time ranging from tens of minutes to several hours to edit a 3D scene using a single GPU. In this work, we propose that by incorporating correspondence regularization into diffusion models, the process of 3D editing can be significantly accelerated. This approach is inspired by the notion that the estimated samples during diffusion should be multiview-consistent during the diffusion generation process. By leveraging this multiview consistency, we can edit 3D content at a much faster speed. In most scenarios, our proposed technique brings a 10$\times$ speed-up compared to the baseline method and completes the editing of a 3D scene in 2 minutes with comparable quality.
FSGS: Real-Time Few-shot View Synthesis using Gaussian Splatting
Dec 01, 2023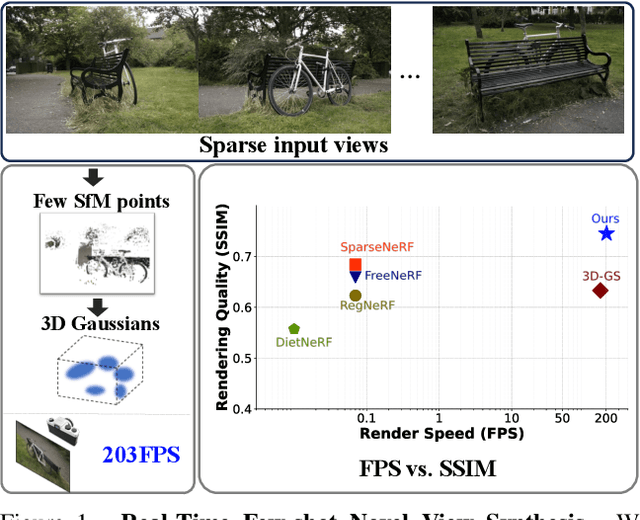
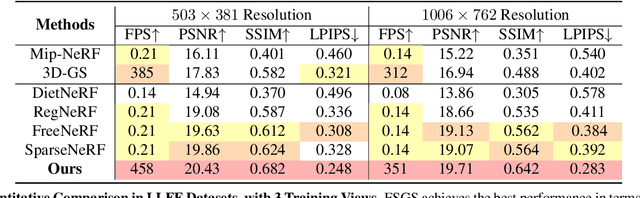
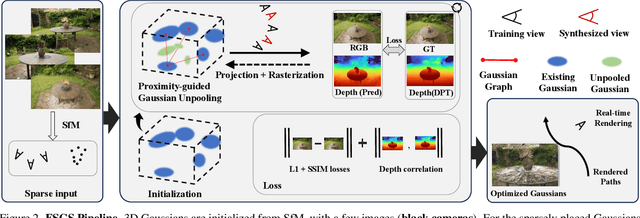
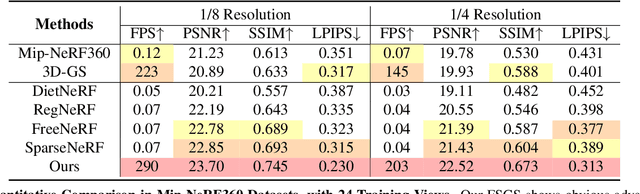
Novel view synthesis from limited observations remains an important and persistent task. However, high efficiency in existing NeRF-based few-shot view synthesis is often compromised to obtain an accurate 3D representation. To address this challenge, we propose a few-shot view synthesis framework based on 3D Gaussian Splatting that enables real-time and photo-realistic view synthesis with as few as three training views. The proposed method, dubbed FSGS, handles the extremely sparse initialized SfM points with a thoughtfully designed Gaussian Unpooling process. Our method iteratively distributes new Gaussians around the most representative locations, subsequently infilling local details in vacant areas. We also integrate a large-scale pre-trained monocular depth estimator within the Gaussians optimization process, leveraging online augmented views to guide the geometric optimization towards an optimal solution. Starting from sparse points observed from limited input viewpoints, our FSGS can accurately grow into unseen regions, comprehensively covering the scene and boosting the rendering quality of novel views. Overall, FSGS achieves state-of-the-art performance in both accuracy and rendering efficiency across diverse datasets, including LLFF, Mip-NeRF360, and Blender. Project website: https://zehaozhu.github.io/FSGS/.
BRAINTEASER: Lateral Thinking Puzzles for Large Language Models
Oct 10, 2023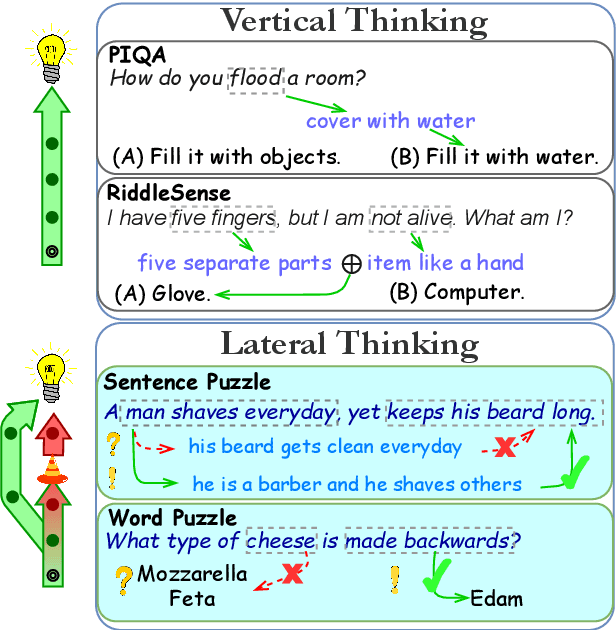
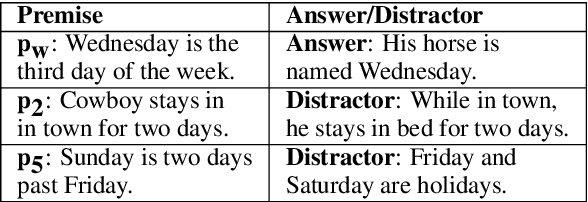


The success of language models has inspired the NLP community to attend to tasks that require implicit and complex reasoning, relying on human-like commonsense mechanisms. While such vertical thinking tasks have been relatively popular, lateral thinking puzzles have received little attention. To bridge this gap, we devise BRAINTEASER: a multiple-choice Question Answering task designed to test the model's ability to exhibit lateral thinking and defy default commonsense associations. We design a three-step procedure for creating the first lateral thinking benchmark, consisting of data collection, distractor generation, and generation of adversarial examples, leading to 1,100 puzzles with high-quality annotations. To assess the consistency of lateral reasoning by models, we enrich BRAINTEASER based on a semantic and contextual reconstruction of its questions. Our experiments with state-of-the-art instruction- and commonsense language models reveal a significant gap between human and model performance, which is further widened when consistency across adversarial formats is considered. We make all of our code and data available to stimulate work on developing and evaluating lateral thinking models.
Drag View: Generalizable Novel View Synthesis with Unposed Imagery
Oct 05, 2023

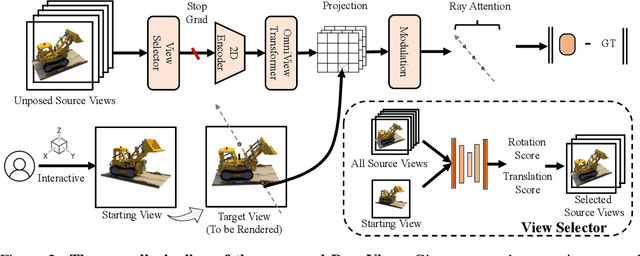
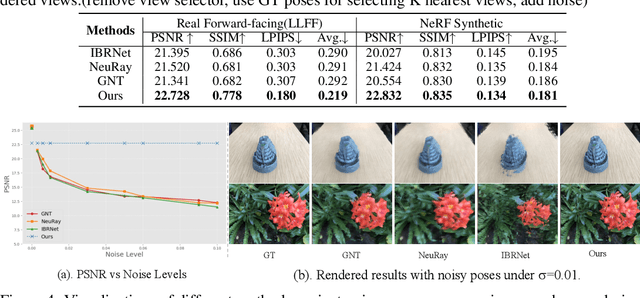
We introduce DragView, a novel and interactive framework for generating novel views of unseen scenes. DragView initializes the new view from a single source image, and the rendering is supported by a sparse set of unposed multi-view images, all seamlessly executed within a single feed-forward pass. Our approach begins with users dragging a source view through a local relative coordinate system. Pixel-aligned features are obtained by projecting the sampled 3D points along the target ray onto the source view. We then incorporate a view-dependent modulation layer to effectively handle occlusion during the projection. Additionally, we broaden the epipolar attention mechanism to encompass all source pixels, facilitating the aggregation of initialized coordinate-aligned point features from other unposed views. Finally, we employ another transformer to decode ray features into final pixel intensities. Crucially, our framework does not rely on either 2D prior models or the explicit estimation of camera poses. During testing, DragView showcases the capability to generalize to new scenes unseen during training, also utilizing only unposed support images, enabling the generation of photo-realistic new views characterized by flexible camera trajectories. In our experiments, we conduct a comprehensive comparison of the performance of DragView with recent scene representation networks operating under pose-free conditions, as well as with generalizable NeRFs subject to noisy test camera poses. DragView consistently demonstrates its superior performance in view synthesis quality, while also being more user-friendly. Project page: https://zhiwenfan.github.io/DragView/.