 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaixin Ma
MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
Apr 24, 2024
While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.
SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense
Apr 22, 2024While vertical thinking relies on logical and commonsense reasoning, lateral thinking requires systems to defy commonsense associations and overwrite them through unconventional thinking. Lateral thinking has been shown to be challenging for current models but has received little attention. A recent benchmark, BRAINTEASER, aims to evaluate current models' lateral thinking ability in a zero-shot setting. In this paper, we split the original benchmark to also support fine-tuning setting and present SemEval Task 9: BRAIN-TEASER(S), the first task at this competition designed to test the system's reasoning and lateral thinking ability. As a popular task, BRAINTEASER(S)'s two subtasks receive 483 team submissions from 182 participants during the competition. This paper provides a fine-grained system analysis of the competition results, together with a reflection on what this means for the ability of the systems to reason laterally. We hope that the BRAINTEASER(S) subtasks and findings in this paper can stimulate future work on lateral thinking and robust reasoning by computational models.
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Jan 28, 2024The advancement of large language models (LLMs) leads to a new era marked by the development of autonomous applications in the real world, which drives innovation in the creation of advanced web-based agents. Existing web agents typically only handle one input modality and are evaluated only in simplified web simulators or static web snapshots, greatly limiting their applicability in real-world scenarios. To bridge this gap, we introduce WebVoyager, an innovative Large Multimodal Model (LMM) powered web agent that can complete user instructions end-to-end by interacting with real-world websites. Moreover, we propose a new evaluation protocol for web agents to address the challenges of automatic evaluation of open-ended web agent tasks, leveraging the robust multimodal comprehension capabilities of GPT-4V. We create a new benchmark by gathering real-world tasks from 15 widely used websites to evaluate our agents. We show that WebVoyager achieves a 55.7% task success rate, significantly surpassing the performance of both GPT-4 (All Tools) and the WebVoyager (text-only) setups, underscoring the exceptional capability of WebVoyager in practical applications. We found that our proposed automatic evaluation achieves 85.3% agreement with human judgment, paving the way for further development of web agents in a real-world setting.
Dense X Retrieval: What Retrieval Granularity Should We Use?
Dec 12, 2023Dense retrieval has become a prominent method to obtain relevant context or world knowledge in open-domain NLP tasks. When we use a learned dense retriever on a retrieval corpus at inference time, an often-overlooked design choice is the retrieval unit in which the corpus is indexed, e.g. document, passage, or sentence. We discover that the retrieval unit choice significantly impacts the performance of both retrieval and downstream tasks. Distinct from the typical approach of using passages or sentences, we introduce a novel retrieval unit, proposition, for dense retrieval. Propositions are defined as atomic expressions within text, each encapsulating a distinct factoid and presented in a concise, self-contained natural language format. We conduct an empirical comparison of different retrieval granularity. Our results reveal that proposition-based retrieval significantly outperforms traditional passage or sentence-based methods in dense retrieval. Moreover, retrieval by proposition also enhances the performance of downstream QA tasks, since the retrieved texts are more condensed with question-relevant information, reducing the need for lengthy input tokens and minimizing the inclusion of extraneous, irrelevant information.
Chain-of-Note: Enhancing Robustness in Retrieval-Augmented Language Models
Nov 15, 2023Retrieval-augmented language models (RALMs) represent a substantial advancement in the capabilities of large language models, notably in reducing factual hallucination by leveraging external knowledge sources. However, the reliability of the retrieved information is not always guaranteed. The retrieval of irrelevant data can lead to misguided responses, and potentially causing the model to overlook its inherent knowledge, even when it possesses adequate information to address the query. Moreover, standard RALMs often struggle to assess whether they possess adequate knowledge, both intrinsic and retrieved, to provide an accurate answer. In situations where knowledge is lacking, these systems should ideally respond with "unknown" when the answer is unattainable. In response to these challenges, we introduces Chain-of-Noting (CoN), a novel approach aimed at improving the robustness of RALMs in facing noisy, irrelevant documents and in handling unknown scenarios. The core idea of CoN is to generate sequential reading notes for retrieved documents, enabling a thorough evaluation of their relevance to the given question and integrating this information to formulate the final answer. We employed ChatGPT to create training data for CoN, which was subsequently trained on an LLaMa-2 7B model. Our experiments across four open-domain QA benchmarks show that RALMs equipped with CoN significantly outperform standard RALMs. Notably, CoN achieves an average improvement of +7.9 in EM score given entirely noisy retrieved documents and +10.5 in rejection rates for real-time questions that fall outside the pre-training knowledge scope.
BRAINTEASER: Lateral Thinking Puzzles for Large Language Models
Oct 10, 2023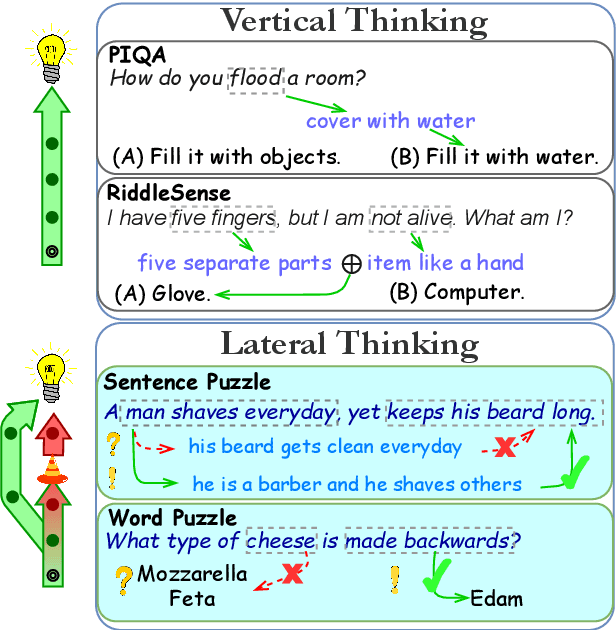
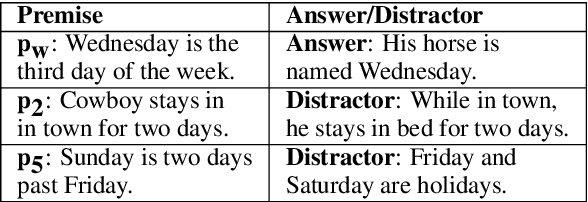


The success of language models has inspired the NLP community to attend to tasks that require implicit and complex reasoning, relying on human-like commonsense mechanisms. While such vertical thinking tasks have been relatively popular, lateral thinking puzzles have received little attention. To bridge this gap, we devise BRAINTEASER: a multiple-choice Question Answering task designed to test the model's ability to exhibit lateral thinking and defy default commonsense associations. We design a three-step procedure for creating the first lateral thinking benchmark, consisting of data collection, distractor generation, and generation of adversarial examples, leading to 1,100 puzzles with high-quality annotations. To assess the consistency of lateral reasoning by models, we enrich BRAINTEASER based on a semantic and contextual reconstruction of its questions. Our experiments with state-of-the-art instruction- and commonsense language models reveal a significant gap between human and model performance, which is further widened when consistency across adversarial formats is considered. We make all of our code and data available to stimulate work on developing and evaluating lateral thinking models.
LASER: LLM Agent with State-Space Exploration for Web Navigation
Sep 15, 2023Large language models (LLMs) have been successfully adapted for interactive decision-making tasks like web navigation. While achieving decent performance, previous methods implicitly assume a forward-only execution mode for the model, where they only provide oracle trajectories as in-context examples to teach the model how to reason in the interactive environment. Consequently, the model could not handle more challenging scenarios not covered in the in-context examples, e.g., mistakes, leading to sub-optimal performance. To address this issue, we propose to model the interactive task as state space exploration, where the LLM agent transitions among a pre-defined set of states by performing actions to complete the task. This formulation enables flexible back-tracking, allowing the model to easily recover from errors. We evaluate our proposed LLM Agent with State-Space ExploRation (LASER) on the WebShop task. Experimental results show that our LASER agent significantly outperforms previous methods and closes the gap with human performance on the web navigation task.
A Study of Situational Reasoning for Traffic Understanding
Jun 05, 2023



Intelligent Traffic Monitoring (ITMo) technologies hold the potential for improving road safety/security and for enabling smart city infrastructure. Understanding traffic situations requires a complex fusion of perceptual information with domain-specific and causal commonsense knowledge. Whereas prior work has provided benchmarks and methods for traffic monitoring, it remains unclear whether models can effectively align these information sources and reason in novel scenarios. To address this assessment gap, we devise three novel text-based tasks for situational reasoning in the traffic domain: i) BDD-QA, which evaluates the ability of Language Models (LMs) to perform situational decision-making, ii) TV-QA, which assesses LMs' abilities to reason about complex event causality, and iii) HDT-QA, which evaluates the ability of models to solve human driving exams. We adopt four knowledge-enhanced methods that have shown generalization capability across language reasoning tasks in prior work, based on natural language inference, commonsense knowledge-graph self-supervision, multi-QA joint training, and dense retrieval of domain information. We associate each method with a relevant knowledge source, including knowledge graphs, relevant benchmarks, and driving manuals. In extensive experiments, we benchmark various knowledge-aware methods against the three datasets, under zero-shot evaluation; we provide in-depth analyses of model performance on data partitions and examine model predictions categorically, to yield useful insights on traffic understanding, given different background knowledge and reasoning strategies.
Knowledge-enhanced Agents for Interactive Text Games
May 08, 2023



Communication via natural language is a crucial aspect of intelligence, and it requires computational models to learn and reason about world concepts, with varying levels of supervision. While there has been significant progress made on fully-supervised non-interactive tasks, such as question-answering and procedural text understanding, much of the community has turned to various sequential interactive tasks, as in semi-Markov text-based games, which have revealed limitations of existing approaches in terms of coherence, contextual awareness, and their ability to learn effectively from the environment. In this paper, we propose a framework for enabling improved functional grounding of agents in text-based games. Specifically, we consider two forms of domain knowledge that we inject into learning-based agents: memory of previous correct actions and affordances of relevant objects in the environment. Our framework supports three representative model classes: `pure' reinforcement learning (RL) agents, RL agents enhanced with knowledge graphs, and agents equipped with language models. Furthermore, we devise multiple injection strategies for the above domain knowledge types and agent architectures, including injection via knowledge graphs and augmentation of the existing input encoding strategies. We perform all experiments on the ScienceWorld text-based game environment, to illustrate the performance of various model configurations in challenging science-related instruction-following tasks. Our findings provide crucial insights on the development of effective natural language processing systems for interactive contexts.
Chain-of-Skills: A Configurable Model for Open-domain Question Answering
May 04, 2023
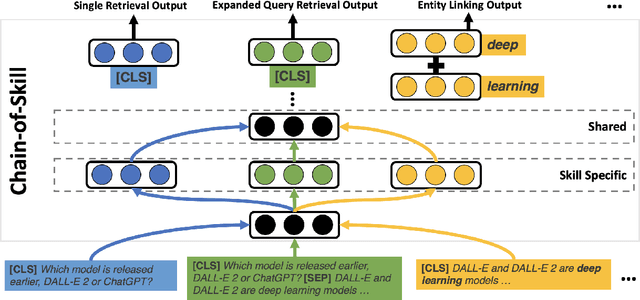
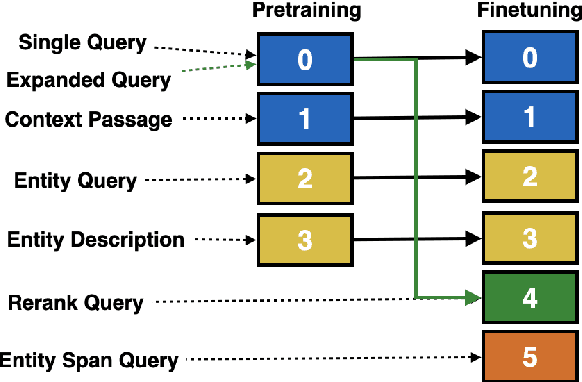

The retrieval model is an indispensable component for real-world knowledge-intensive tasks, e.g., open-domain question answering (ODQA). As separate retrieval skills are annotated for different datasets, recent work focuses on customized methods, limiting the model transferability and scalability. In this work, we propose a modular retriever where individual modules correspond to key skills that can be reused across datasets. Our approach supports flexible skill configurations based on the target domain to boost performance. To mitigate task interference, we design a novel modularization parameterization inspired by sparse Transformer. We demonstrate that our model can benefit from self-supervised pretraining on Wikipedia and fine-tuning using multiple ODQA datasets, both in a multi-task fashion. Our approach outperforms recent self-supervised retrievers in zero-shot evaluations and achieves state-of-the-art fine-tuned retrieval performance on NQ, HotpotQA and OTT-QA.