 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXuan Song
A Phone-based Distributed Ambient Temperature Measurement System with An Efficient Label-free Automated Training Strategy
Apr 16, 2024
Enhancing the energy efficiency of buildings significantly relies on monitoring indoor ambient temperature. The potential limitations of conventional temperature measurement techniques, together with the omnipresence of smartphones, have redirected researchers' attention towards the exploration of phone-based ambient temperature estimation technology. Nevertheless, numerous obstacles remain to be addressed in order to achieve a practical implementation of this technology. This study proposes a distributed phone-based ambient temperature estimation system which enables collaboration between multiple phones to accurately measure the ambient temperature in each small area of an indoor space. Besides, it offers a secure, efficient, and cost-effective training strategy to train a new estimation model for each newly added phone, eliminating the need for manual collection of labeled data. This innovative training strategy can yield a high-performing estimation model for a new phone with just 5 data points, requiring only a few iterations. Meanwhile, by crowdsourcing, our system automatically provides accurate inferred labels for all newly collected data. We also highlight the potential of integrating federated learning into our system to ensure privacy protection at the end of this study. We believe this study has the potential to advance the practical application of phone-based ambient temperature measurement, facilitating energy-saving efforts in buildings.
TrafPS: A Shapley-based Visual Analytics Approach to Interpret Traffic
Mar 07, 2024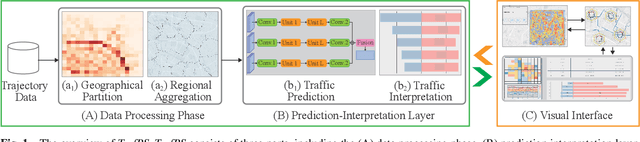

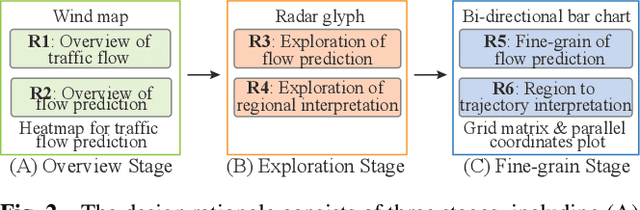

Recent achievements in deep learning (DL) have shown its potential for predicting traffic flows. Such predictions are beneficial for understanding the situation and making decisions in traffic control. However, most state-of-the-art DL models are considered "black boxes" with little to no transparency for end users with respect to the underlying mechanisms. Some previous work tried to "open the black boxes" and increase the interpretability of how predictions are generated. However, it still remains challenging to handle complex models on large-scale spatio-temporal data and discover salient spatial and temporal patterns that significantly influence traffic flows. To overcome the challenges, we present TrafPS, a visual analytics approach for interpreting traffic prediction outcomes to support decision-making in traffic management and urban planning. The measurements, region SHAP and trajectory SHAP, are proposed to quantify the impact of flow patterns on urban traffic at different levels. Based on the task requirement from the domain experts, we employ an interactive visual interface for multi-aspect exploration and analysis of significant flow patterns. Two real-world case studies demonstrate the effectiveness of TrafPS in identifying key routes and decision-making support for urban planning.
The Bigger the Better? Rethinking the Effective Model Scale in Long-term Time Series Forecasting
Feb 03, 2024Long-term time series forecasting (LTSF) represents a critical frontier in time series analysis, distinguished by its focus on extensive input sequences, in contrast to the constrained lengths typical of traditional approaches. While longer sequences inherently convey richer information, potentially enhancing predictive precision, prevailing techniques often respond by escalating model complexity. These intricate models can inflate into millions of parameters, incorporating parameter-intensive elements like positional encodings, feed-forward networks and self-attention mechanisms. This complexity, however, leads to prohibitive model scale, particularly given the time series data's semantic simplicity. Motivated by the pursuit of parsimony, our research employs conditional correlation and auto-correlation as investigative tools, revealing significant redundancies within the input data. Leveraging these insights, we introduce the HDformer, a lightweight Transformer variant enhanced with hierarchical decomposition. This novel architecture not only inverts the prevailing trend toward model expansion but also accomplishes precise forecasting with drastically fewer computations and parameters. Remarkably, HDformer outperforms existing state-of-the-art LTSF models, while requiring over 99\% fewer parameters. Through this work, we advocate a paradigm shift in LTSF, emphasizing the importance to tailor the model to the inherent dynamics of time series data-a timely reminder that in the realm of LTSF, bigger is not invariably better.
Spatio-Temporal-Decoupled Masked Pre-training for Traffic Forecasting
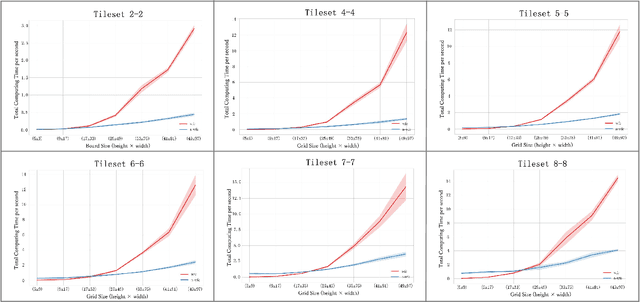
Dec 01, 2023Accurate forecasting of multivariate traffic flow time series remains challenging due to substantial spatio-temporal heterogeneity and complex long-range correlative patterns. To address this, we propose Spatio-Temporal-Decoupled Masked Pre-training (STD-MAE), a novel framework that employs masked autoencoders to learn and encode complex spatio-temporal dependencies via pre-training. Specifically, we use two decoupled masked autoencoders to reconstruct the traffic data along spatial and temporal axes using a self-supervised pre-training approach. These mask reconstruction mechanisms capture the long-range correlations in space and time separately. The learned hidden representations are then used to augment the downstream spatio-temporal traffic predictor. A series of quantitative and qualitative evaluations on four widely-used traffic benchmarks (PEMS03, PEMS04, PEMS07, and PEMS08) are conducted to verify the state-of-the-art performance, with STD-MAE explicitly enhancing the downstream spatio-temporal models' ability to capture long-range intricate spatial and temporal patterns. Codes are available at https://github.com/Jimmy-7664/STD_MAE.
Hyper-Relational Knowledge Graph Neural Network for Next POI
Nov 28, 2023With the advancement of mobile technology, Point of Interest (POI) recommendation systems in Location-based Social Networks (LBSN) have brought numerous benefits to both users and companies. Many existing works employ Knowledge Graph (KG) to alleviate the data sparsity issue in LBSN. These approaches primarily focus on modeling the pair-wise relations in LBSN to enrich the semantics and thereby relieve the data sparsity issue. However, existing approaches seldom consider the hyper-relations in LBSN, such as the mobility relation (a 3-ary relation: user-POI-time). This makes the model hard to exploit the semantics accurately. In addition, prior works overlook the rich structural information inherent in KG, which consists of higher-order relations and can further alleviate the impact of data sparsity.To this end, we propose a Hyper-Relational Knowledge Graph Neural Network (HKGNN) model. In HKGNN, a Hyper-Relational Knowledge Graph (HKG) that models the LBSN data is constructed to maintain and exploit the rich semantics of hyper-relations. Then we proposed a Hypergraph Neural Network to utilize the structural information of HKG in a cohesive way. In addition, a self-attention network is used to leverage sequential information and make personalized recommendations. Furthermore, side information, essential in reducing data sparsity by providing background knowledge of POIs, is not fully utilized in current methods. In light of this, we extended the current dataset with available side information to further lessen the impact of data sparsity. Results of experiments on four real-world LBSN datasets demonstrate the effectiveness of our approach compared to existing state-of-the-art methods.
MemDA: Forecasting Urban Time Series with Memory-based Drift Adaptation
Sep 25, 2023


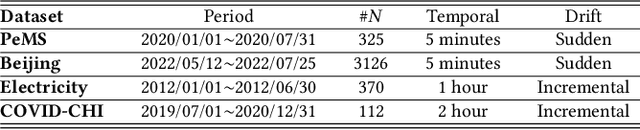
Urban time series data forecasting featuring significant contributions to sustainable development is widely studied as an essential task of the smart city. However, with the dramatic and rapid changes in the world environment, the assumption that data obey Independent Identically Distribution is undermined by the subsequent changes in data distribution, known as concept drift, leading to weak replicability and transferability of the model over unseen data. To address the issue, previous approaches typically retrain the model, forcing it to fit the most recent observed data. However, retraining is problematic in that it leads to model lag, consumption of resources, and model re-invalidation, causing the drift problem to be not well solved in realistic scenarios. In this study, we propose a new urban time series prediction model for the concept drift problem, which encodes the drift by considering the periodicity in the data and makes on-the-fly adjustments to the model based on the drift using a meta-dynamic network. Experiments on real-world datasets show that our design significantly outperforms state-of-the-art methods and can be well generalized to existing prediction backbones by reducing their sensitivity to distribution changes.
Curriculum Reinforcement Learning via Morphology-Environment Co-Evolution
Sep 21, 2023Throughout long history, natural species have learned to survive by evolving their physical structures adaptive to the environment changes. In contrast, current reinforcement learning (RL) studies mainly focus on training an agent with a fixed morphology (e.g., skeletal structure and joint attributes) in a fixed environment, which can hardly generalize to changing environments or new tasks. In this paper, we optimize an RL agent and its morphology through ``morphology-environment co-evolution (MECE)'', in which the morphology keeps being updated to adapt to the changing environment, while the environment is modified progressively to bring new challenges and stimulate the improvement of the morphology. This leads to a curriculum to train generalizable RL, whose morphology and policy are optimized for different environments. Instead of hand-crafting the curriculum, we train two policies to automatically change the morphology and the environment. To this end, (1) we develop two novel and effective rewards for the two policies, which are solely based on the learning dynamics of the RL agent; (2) we design a scheduler to automatically determine when to change the environment and the morphology. In experiments on two classes of tasks, the morphology and RL policies trained via MECE exhibit significantly better generalization performance in unseen test environments than SOTA morphology optimization methods. Our ablation studies on the two MECE policies further show that the co-evolution between the morphology and environment is the key to the success.
STAEformer: Spatio-Temporal Adaptive Embedding Makes Vanilla Transformer SOTA for Traffic Forecasting
Aug 26, 2023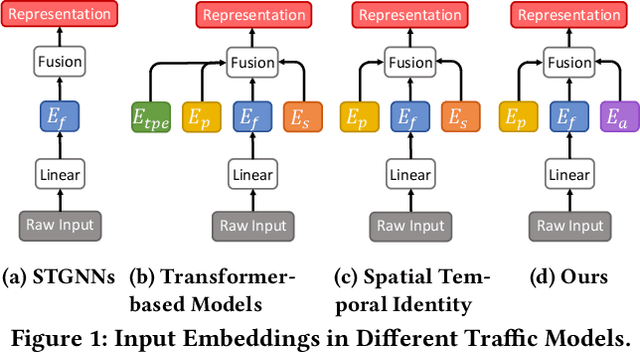
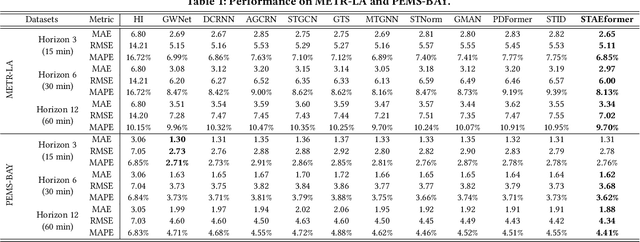
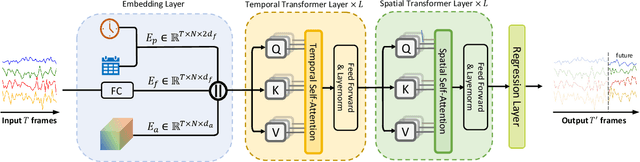
With the rapid development of the Intelligent Transportation System (ITS), accurate traffic forecasting has emerged as a critical challenge. The key bottleneck lies in capturing the intricate spatio-temporal traffic patterns. In recent years, numerous neural networks with complicated architectures have been proposed to address this issue. However, the advancements in network architectures have encountered diminishing performance gains. In this study, we present a novel component called spatio-temporal adaptive embedding that can yield outstanding results with vanilla transformers. Our proposed Spatio-Temporal Adaptive Embedding transformer (STAEformer) achieves state-of-the-art performance on five real-world traffic forecasting datasets. Further experiments demonstrate that spatio-temporal adaptive embedding plays a crucial role in traffic forecasting by effectively capturing intrinsic spatio-temporal relations and chronological information in traffic time series.
Extend Wave Function Collapse to Large-Scale Content Generation
Aug 14, 2023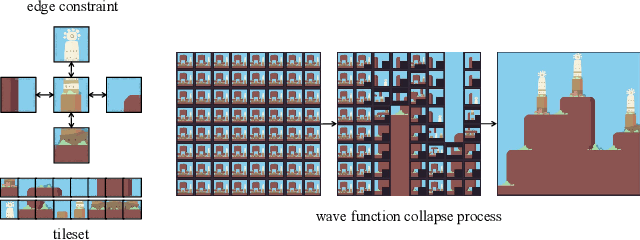
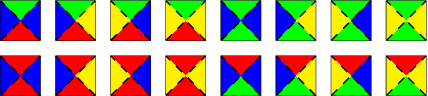

Wave Function Collapse (WFC) is a widely used tile-based algorithm in procedural content generation, including textures, objects, and scenes. However, the current WFC algorithm and related research lack the ability to generate commercialized large-scale or infinite content due to constraint conflict and time complexity costs. This paper proposes a Nested WFC (N-WFC) algorithm framework to reduce time complexity. To avoid conflict and backtracking problems, we offer a complete and sub-complete tileset preparation strategy, which requires only a small number of tiles to generate aperiodic and deterministic infinite content. We also introduce the weight-brush system that combines N-WFC and sub-complete tileset, proving its suitability for game design. Our contribution addresses WFC's challenge in massive content generation and provides a theoretical basis for implementing concrete games.
Learning Gaussian Mixture Representations for Tensor Time Series Forecasting
Jun 07, 2023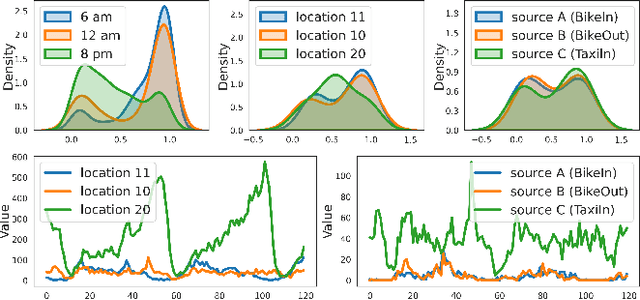
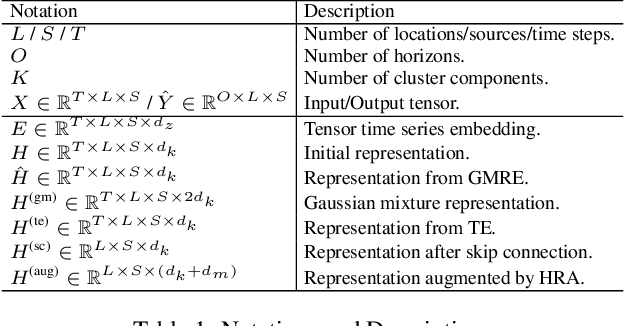
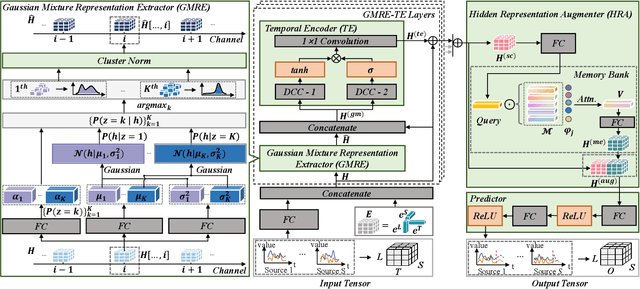

Tensor time series (TTS) data, a generalization of one-dimensional time series on a high-dimensional space, is ubiquitous in real-world scenarios, especially in monitoring systems involving multi-source spatio-temporal data (e.g., transportation demands and air pollutants). Compared to modeling time series or multivariate time series, which has received much attention and achieved tremendous progress in recent years, tensor time series has been paid less effort. Properly coping with the tensor time series is a much more challenging task, due to its high-dimensional and complex inner structure. In this paper, we develop a novel TTS forecasting framework, which seeks to individually model each heterogeneity component implied in the time, the location, and the source variables. We name this framework as GMRL, short for Gaussian Mixture Representation Learning. Experiment results on two real-world TTS datasets verify the superiority of our approach compared with the state-of-the-art baselines. Code and data are published on https://github.com/beginner-sketch/GMRL.