 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenyan Cong
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Mar 29, 2024
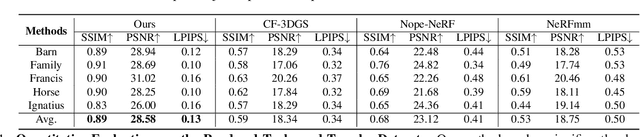
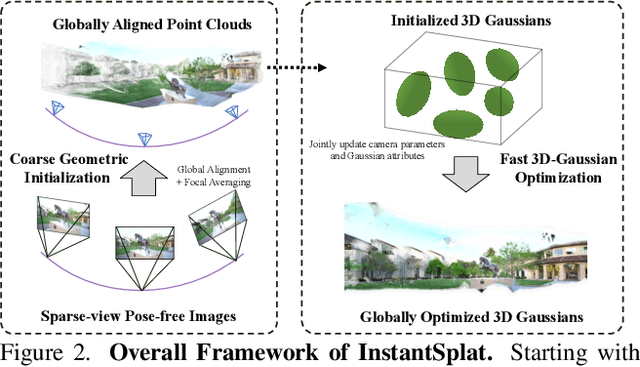
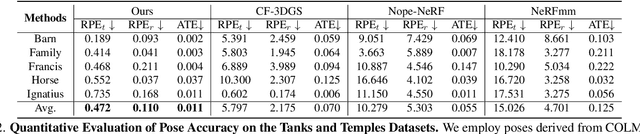

While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts
Aug 22, 2023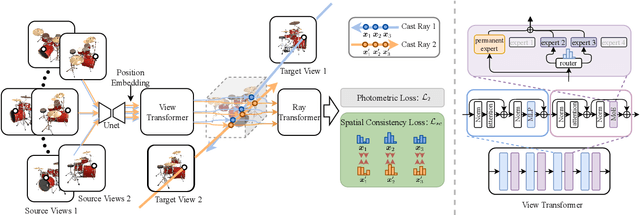
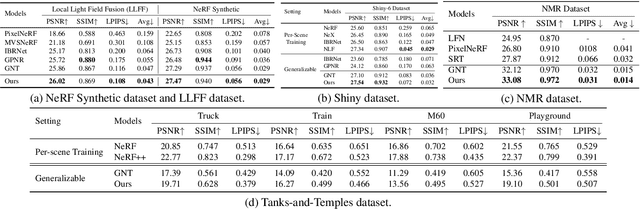

Cross-scene generalizable NeRF models, which can directly synthesize novel views of unseen scenes, have become a new spotlight of the NeRF field. Several existing attempts rely on increasingly end-to-end "neuralized" architectures, i.e., replacing scene representation and/or rendering modules with performant neural networks such as transformers, and turning novel view synthesis into a feed-forward inference pipeline. While those feedforward "neuralized" architectures still do not fit diverse scenes well out of the box, we propose to bridge them with the powerful Mixture-of-Experts (MoE) idea from large language models (LLMs), which has demonstrated superior generalization ability by balancing between larger overall model capacity and flexible per-instance specialization. Starting from a recent generalizable NeRF architecture called GNT, we first demonstrate that MoE can be neatly plugged in to enhance the model. We further customize a shared permanent expert and a geometry-aware consistency loss to enforce cross-scene consistency and spatial smoothness respectively, which are essential for generalizable view synthesis. Our proposed model, dubbed GNT with Mixture-of-View-Experts (GNT-MOVE), has experimentally shown state-of-the-art results when transferring to unseen scenes, indicating remarkably better cross-scene generalization in both zero-shot and few-shot settings. Our codes are available at https://github.com/VITA-Group/GNT-MOVE.
Deep Image Harmonization with Learnable Augmentation
Aug 01, 2023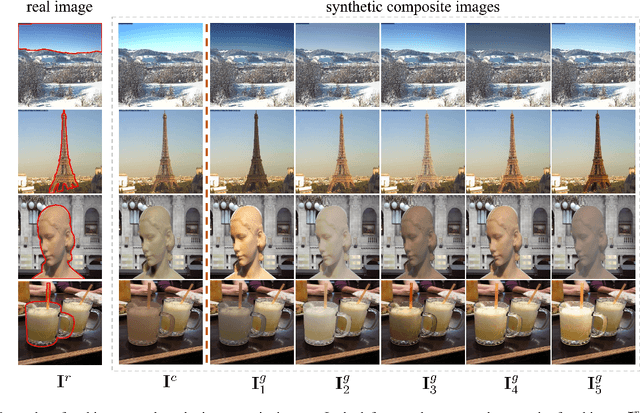
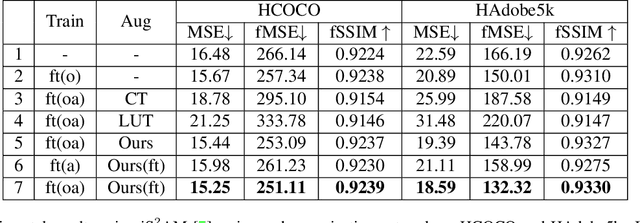


The goal of image harmonization is adjusting the foreground appearance in a composite image to make the whole image harmonious. To construct paired training images, existing datasets adopt different ways to adjust the illumination statistics of foregrounds of real images to produce synthetic composite images. However, different datasets have considerable domain gap and the performances on small-scale datasets are limited by insufficient training data. In this work, we explore learnable augmentation to enrich the illumination diversity of small-scale datasets for better harmonization performance. In particular, our designed SYthetic COmposite Network (SycoNet) takes in a real image with foreground mask and a random vector to learn suitable color transformation, which is applied to the foreground of this real image to produce a synthetic composite image. Comprehensive experiments demonstrate the effectiveness of our proposed learnable augmentation for image harmonization. The code of SycoNet is released at https://github.com/bcmi/SycoNet-Adaptive-Image-Harmonization.
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Jul 20, 2023
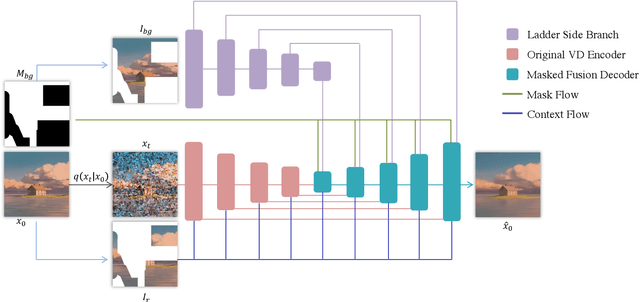

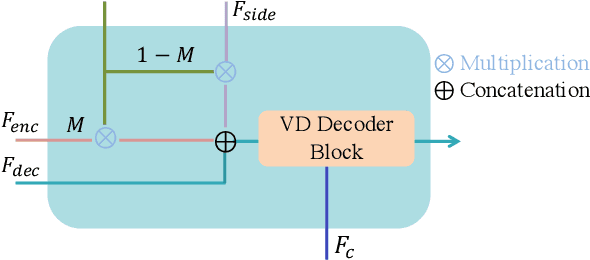
Have you ever imagined how it would look if we placed new objects into paintings? For example, what would it look like if we placed a basketball into Claude Monet's ``Water Lilies, Evening Effect''? We propose Reference-based Painterly Inpainting, a novel task that crosses the wild reference domain gap and implants novel objects into artworks. Although previous works have examined reference-based inpainting, they are not designed for large domain discrepancies between the target and the reference, such as inpainting an artistic image using a photorealistic reference. This paper proposes a novel diffusion framework, dubbed RefPaint, to ``inpaint more wildly'' by taking such references with large domain gaps. Built with an image-conditioned diffusion model, we introduce a ladder-side branch and a masked fusion mechanism to work with the inpainting mask. By decomposing the CLIP image embeddings at inference time, one can manipulate the strength of semantic and style information with ease. Experiments demonstrate that our proposed RefPaint framework produces significantly better results than existing methods. Our method enables creative painterly image inpainting with reference objects that would otherwise be difficult to achieve. Project page: https://vita-group.github.io/RefPaint/
Deep Video Harmonization with Color Mapping Consistency
May 02, 2022


Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Moreover, we consider the temporal consistency in video harmonization task. Unlike previous works which establish the spatial correspondence, we design a novel framework based on the assumption of color mapping consistency, which leverages the color mapping of neighboring frames to refine the current frame. Extensive experiments on our HYouTube dataset prove the effectiveness of our proposed framework. Our dataset and code are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube.
HYouTube: Video Harmonization Dataset
Sep 18, 2021

Video composition aims to generate a composite video by combining the foreground of one video with the background of another video, but the inserted foreground may be incompatible with the background in terms of color and illumination. Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Considering the domain gap between real composite videos and synthetic composite videos, we additionally create 100 real composite videos via copy-and-paste. Datasets are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021



Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
Making Images Real Again: A Comprehensive Survey on Deep Image Composition
Jun 28, 2021



As a common image editing operation, image composition aims to cut the foreground from one image and paste it on another image, resulting in a composite image. However, there are many issues that could make the composite images unrealistic. These issues can be summarized as the inconsistency between foreground and background, which include appearance inconsistency (e.g., incompatible color and illumination) and geometry inconsistency (e.g., unreasonable size and location). Previous works on image composition target at one or more issues. Since each individual issue is a complicated problem, there are some research directions (e.g., image harmonization, object placement) which focus on only one issue. By putting all the efforts together, we can acquire realistic composite images. Sometimes, we expect the composite images to be not only realistic but also aesthetic, in which case aesthetic evaluation needs to be considered. In this survey, we summarize the datasets and methods for the above research directions. We also discuss the limitations and potential directions to facilitate the future research for image composition. Finally, as a double-edged sword, image composition may also have negative effect on our lives (e.g., fake news) and thus it is imperative to develop algorithms to fight against composite images. Datasets and codes for image composition are summarized at https://github.com/bcmi/Awesome-Image-Composition.
Deep Image Harmonization by Bridging the Reality Gap
Mar 31, 2021
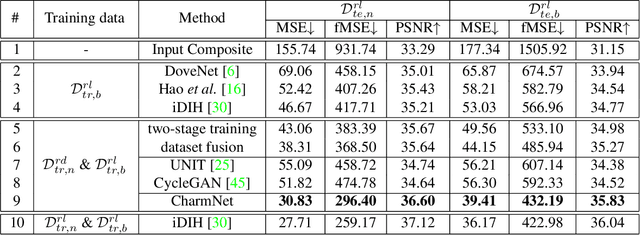
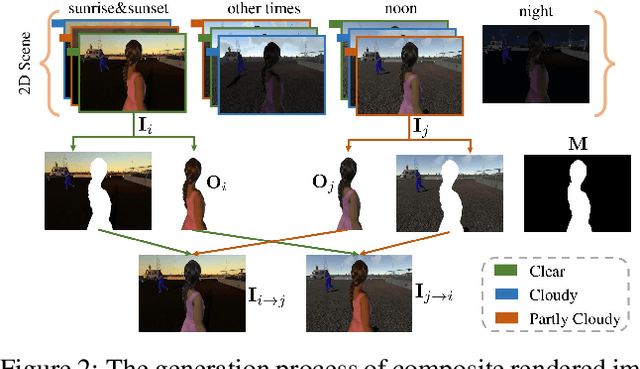

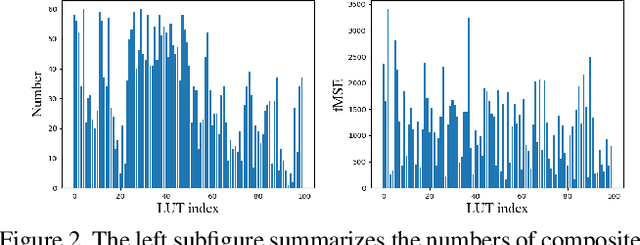
Image harmonization has been significantly advanced with large-scale harmonization dataset. However, the current way to build dataset is still labor-intensive, which adversely affects the extendability of dataset. To address this problem, we propose to construct a large-scale rendered harmonization dataset RHHarmony with fewer human efforts to augment the existing real-world dataset. To leverage both real-world images and rendered images, we propose a cross-domain harmonization network CharmNet to bridge the domain gap between two domains. Moreover, we also employ well-designed style classifiers and losses to facilitate cross-domain knowledge transfer. Extensive experiments demonstrate the potential of using rendered images for image harmonization and the effectiveness of our proposed network. Our dataset and code are available at https://github.com/bcmi/Rendered_Image_Harmonization_Datasets.
BargainNet: Background-Guided Domain Translation for Image Harmonization
Sep 19, 2020



Image composition is a fundamental operation in image editing field. However, unharmonious foreground and background downgrade the quality of composite image. Image harmonization, which adjusts the foreground to improve the consistency, is an essential yet challenging task. Previous deep learning based methods mainly focus on directly learning the mapping from composite image to real image, while ignoring the crucial guidance role that background plays. In this work, with the assumption that the foreground needs to be translated to the same domain as background, we formulate image harmonization task as background-guided domain translation. Therefore, we propose an image harmonization network with a novel domain code extractor and well-tailored triplet losses, which could capture the background domain information to guide the foreground harmonization. Extensive experiments on the existing image harmonization benchmark demonstrate the effectiveness of our proposed method.