 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlessio Del Bue
Contrastive Gaussian Clustering: Weakly Supervised 3D Scene Segmentation
Apr 19, 2024
We introduce Contrastive Gaussian Clustering, a novel approach capable of provide segmentation masks from any viewpoint and of enabling 3D segmentation of the scene. Recent works in novel-view synthesis have shown how to model the appearance of a scene via a cloud of 3D Gaussians, and how to generate accurate images from a given viewpoint by projecting on it the Gaussians before $\alpha$ blending their color. Following this example, we train a model to include also a segmentation feature vector for each Gaussian. These can then be used for 3D scene segmentation, by clustering Gaussians according to their feature vectors; and to generate 2D segmentation masks, by projecting the Gaussians on a plane and $\alpha$ blending over their segmentation features. Using a combination of contrastive learning and spatial regularization, our method can be trained on inconsistent 2D segmentation masks, and still learn to generate segmentation masks consistent across all views. Moreover, the resulting model is extremely accurate, improving the IoU accuracy of the predicted masks by $+8\%$ over the state of the art. Code and trained models will be released soon.
Uncertainty-guided Open-Set Source-Free Unsupervised Domain Adaptation with Target-private Class Segregation
Apr 16, 2024Standard Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target but usually requires simultaneous access to both source and target data. Moreover, UDA approaches commonly assume that source and target domains share the same labels space. Yet, these two assumptions are hardly satisfied in real-world scenarios. This paper considers the more challenging Source-Free Open-set Domain Adaptation (SF-OSDA) setting, where both assumptions are dropped. We propose a novel approach for SF-OSDA that exploits the granularity of target-private categories by segregating their samples into multiple unknown classes. Starting from an initial clustering-based assignment, our method progressively improves the segregation of target-private samples by refining their pseudo-labels with the guide of an uncertainty-based sample selection module. Additionally, we propose a novel contrastive loss, named NL-InfoNCELoss, that, integrating negative learning into self-supervised contrastive learning, enhances the model robustness to noisy pseudo-labels. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed method over existing approaches, establishing new state-of-the-art performance. Notably, additional analyses show that our method is able to learn the underlying semantics of novel classes, opening the possibility to perform novel class discovery.
HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Apr 01, 2024We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
IFFNeRF: Initialisation Free and Fast 6DoF pose estimation from a single image and a NeRF model
Mar 19, 2024



We introduce IFFNeRF to estimate the six degrees-of-freedom (6DoF) camera pose of a given image, building on the Neural Radiance Fields (NeRF) formulation. IFFNeRF is specifically designed to operate in real-time and eliminates the need for an initial pose guess that is proximate to the sought solution. IFFNeRF utilizes the Metropolis-Hasting algorithm to sample surface points from within the NeRF model. From these sampled points, we cast rays and deduce the color for each ray through pixel-level view synthesis. The camera pose can then be estimated as the solution to a Least Squares problem by selecting correspondences between the query image and the resulting bundle. We facilitate this process through a learned attention mechanism, bridging the query image embedding with the embedding of parameterized rays, thereby matching rays pertinent to the image. Through synthetic and real evaluation settings, we show that our method can improve the angular and translation error accuracy by 80.1% and 67.3%, respectively, compared to iNeRF while performing at 34fps on consumer hardware and not requiring the initial pose guess.
PRAGO: Differentiable Multi-View Pose Optimization From Objectness Detections
Mar 15, 2024



Robustly estimating camera poses from a set of images is a fundamental task which remains challenging for differentiable methods, especially in the case of small and sparse camera pose graphs. To overcome this challenge, we propose Pose-refined Rotation Averaging Graph Optimization (PRAGO). From a set of objectness detections on unordered images, our method reconstructs the rotational pose, and in turn, the absolute pose, in a differentiable manner benefiting from the optimization of a sequence of geometrical tasks. We show how our objectness pose-refinement module in PRAGO is able to refine the inherent ambiguities in pairwise relative pose estimation without removing edges and avoiding making early decisions on the viability of graph edges. PRAGO then refines the absolute rotations through iterative graph construction, reweighting the graph edges to compute the final rotational pose, which can be converted into absolute poses using translation averaging. We show that PRAGO is able to outperform non-differentiable solvers on small and sparse scenes extracted from 7-Scenes achieving a relative improvement of 21% for rotations while achieving similar translation estimates.
Mind the Error! Detection and Localization of Instruction Errors in Vision-and-Language Navigation
Mar 15, 2024
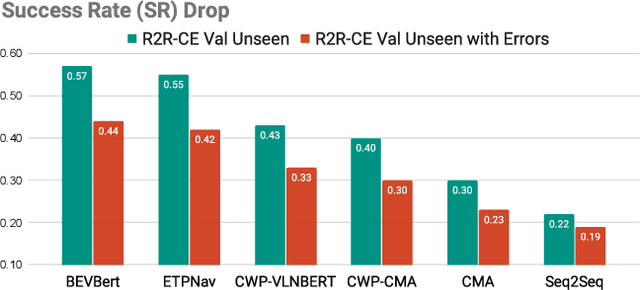
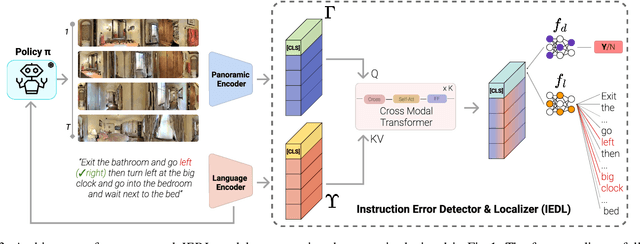
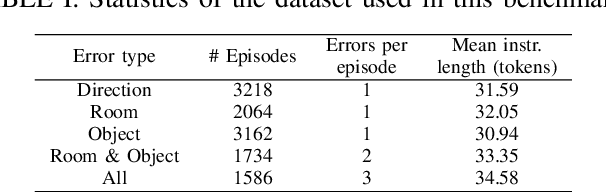
Vision-and-Language Navigation in Continuous Environments (VLN-CE) is one of the most intuitive yet challenging embodied AI tasks. Agents are tasked to navigate towards a target goal by executing a set of low-level actions, following a series of natural language instructions. All VLN-CE methods in the literature assume that language instructions are exact. However, in practice, instructions given by humans can contain errors when describing a spatial environment due to inaccurate memory or confusion. Current VLN-CE benchmarks do not address this scenario, making the state-of-the-art methods in VLN-CE fragile in the presence of erroneous instructions from human users. For the first time, we propose a novel benchmark dataset that introduces various types of instruction errors considering potential human causes. This benchmark provides valuable insight into the robustness of VLN systems in continuous environments. We observe a noticeable performance drop (up to -25%) in Success Rate when evaluating the state-of-the-art VLN-CE methods on our benchmark. Moreover, we formally define the task of Instruction Error Detection and Localization, and establish an evaluation protocol on top of our benchmark dataset. We also propose an effective method, based on a cross-modal transformer architecture, that achieves the best performance in error detection and localization, compared to baselines. Surprisingly, our proposed method has revealed errors in the validation set of the two commonly used datasets for VLN-CE, i.e., R2R-CE and RxR-CE, demonstrating the utility of our technique in other tasks. Code and dataset will be made available upon acceptance at https://intelligolabs.github.io/R2RIE-CE
Towards the Reusability and Compositionality of Causal Representations
Mar 14, 2024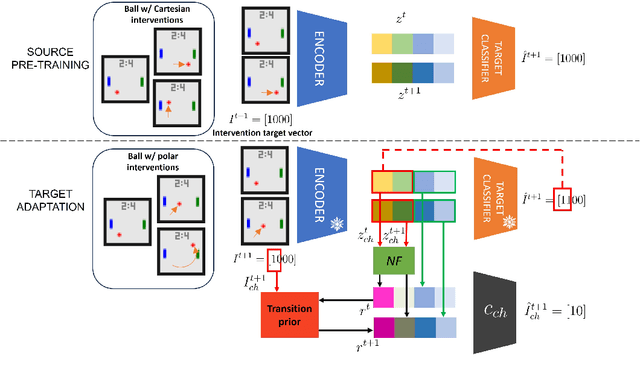
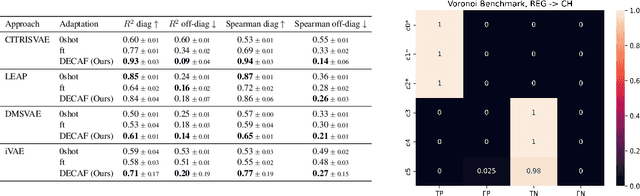
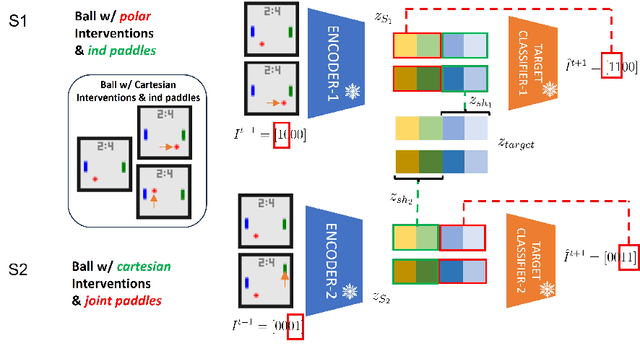

Causal Representation Learning (CRL) aims at identifying high-level causal factors and their relationships from high-dimensional observations, e.g., images. While most CRL works focus on learning causal representations in a single environment, in this work we instead propose a first step towards learning causal representations from temporal sequences of images that can be adapted in a new environment, or composed across multiple related environments. In particular, we introduce DECAF, a framework that detects which causal factors can be reused and which need to be adapted from previously learned causal representations. Our approach is based on the availability of intervention targets, that indicate which variables are perturbed at each time step. Experiments on three benchmark datasets show that integrating our framework with four state-of-the-art CRL approaches leads to accurate representations in a new environment with only a few samples.
DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly
Feb 29, 2024Reassembly tasks play a fundamental role in many fields and multiple approaches exist to solve specific reassembly problems. In this context, we posit that a general unified model can effectively address them all, irrespective of the input data type (images, 3D, etc.). We introduce DiffAssemble, a Graph Neural Network (GNN)-based architecture that learns to solve reassembly tasks using a diffusion model formulation. Our method treats the elements of a set, whether pieces of 2D patch or 3D object fragments, as nodes of a spatial graph. Training is performed by introducing noise into the position and rotation of the elements and iteratively denoising them to reconstruct the coherent initial pose. DiffAssemble achieves state-of-the-art (SOTA) results in most 2D and 3D reassembly tasks and is the first learning-based approach that solves 2D puzzles for both rotation and translation. Furthermore, we highlight its remarkable reduction in run-time, performing 11 times faster than the quickest optimization-based method for puzzle solving. Code available at https://github.com/IIT-PAVIS/DiffAssemble
mmFUSION: Multimodal Fusion for 3D Objects Detection
Nov 07, 2023Multi-sensor fusion is essential for accurate 3D object detection in self-driving systems. Camera and LiDAR are the most commonly used sensors, and usually, their fusion happens at the early or late stages of 3D detectors with the help of regions of interest (RoIs). On the other hand, fusion at the intermediate level is more adaptive because it does not need RoIs from modalities but is complex as the features of both modalities are presented from different points of view. In this paper, we propose a new intermediate-level multi-modal fusion (mmFUSION) approach to overcome these challenges. First, the mmFUSION uses separate encoders for each modality to compute features at a desired lower space volume. Second, these features are fused through cross-modality and multi-modality attention mechanisms proposed in mmFUSION. The mmFUSION framework preserves multi-modal information and learns to complement modalities' deficiencies through attention weights. The strong multi-modal features from the mmFUSION framework are fed to a simple 3D detection head for 3D predictions. We evaluate mmFUSION on the KITTI and NuScenes dataset where it performs better than available early, intermediate, late, and even two-stage based fusion schemes. The code with the mmdetection3D project plugin will be publicly available soon.
Learnable Data Augmentation for One-Shot Unsupervised Domain Adaptation
Oct 03, 2023



This paper presents a classification framework based on learnable data augmentation to tackle the One-Shot Unsupervised Domain Adaptation (OS-UDA) problem. OS-UDA is the most challenging setting in Domain Adaptation, as only one single unlabeled target sample is assumed to be available for model adaptation. Driven by such single sample, our method LearnAug-UDA learns how to augment source data, making it perceptually similar to the target. As a result, a classifier trained on such augmented data will generalize well for the target domain. To achieve this, we designed an encoder-decoder architecture that exploits a perceptual loss and style transfer strategies to augment the source data. Our method achieves state-of-the-art performance on two well-known Domain Adaptation benchmarks, DomainNet and VisDA. The project code is available at https://github.com/IIT-PAVIS/LearnAug-UDA