 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrancesco Taioli
Mind the Error! Detection and Localization of Instruction Errors in Vision-and-Language Navigation
Mar 15, 2024

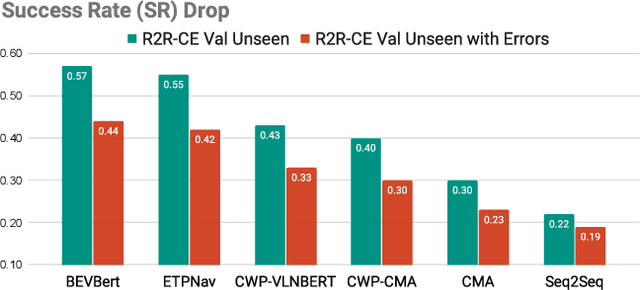
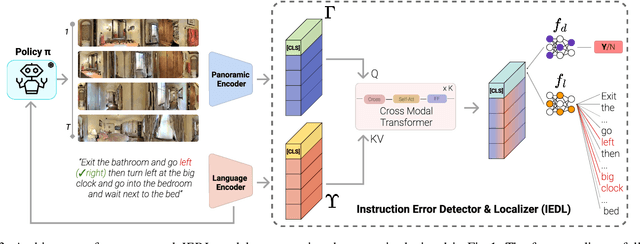
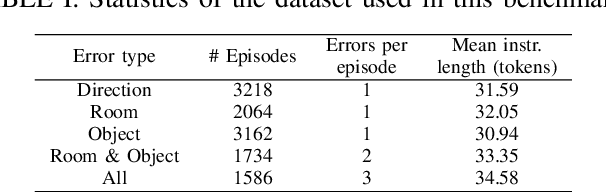
Vision-and-Language Navigation in Continuous Environments (VLN-CE) is one of the most intuitive yet challenging embodied AI tasks. Agents are tasked to navigate towards a target goal by executing a set of low-level actions, following a series of natural language instructions. All VLN-CE methods in the literature assume that language instructions are exact. However, in practice, instructions given by humans can contain errors when describing a spatial environment due to inaccurate memory or confusion. Current VLN-CE benchmarks do not address this scenario, making the state-of-the-art methods in VLN-CE fragile in the presence of erroneous instructions from human users. For the first time, we propose a novel benchmark dataset that introduces various types of instruction errors considering potential human causes. This benchmark provides valuable insight into the robustness of VLN systems in continuous environments. We observe a noticeable performance drop (up to -25%) in Success Rate when evaluating the state-of-the-art VLN-CE methods on our benchmark. Moreover, we formally define the task of Instruction Error Detection and Localization, and establish an evaluation protocol on top of our benchmark dataset. We also propose an effective method, based on a cross-modal transformer architecture, that achieves the best performance in error detection and localization, compared to baselines. Surprisingly, our proposed method has revealed errors in the validation set of the two commonly used datasets for VLN-CE, i.e., R2R-CE and RxR-CE, demonstrating the utility of our technique in other tasks. Code and dataset will be made available upon acceptance at https://intelligolabs.github.io/R2RIE-CE
Language-enhanced RNR-Map: Querying Renderable Neural Radiance Field maps with natural language
Aug 17, 2023



We present Le-RNR-Map, a Language-enhanced Renderable Neural Radiance map for Visual Navigation with natural language query prompts. The recently proposed RNR-Map employs a grid structure comprising latent codes positioned at each pixel. These latent codes, which are derived from image observation, enable: i) image rendering given a camera pose, since they are converted to Neural Radiance Field; ii) image navigation and localization with astonishing accuracy. On top of this, we enhance RNR-Map with CLIP-based embedding latent codes, allowing natural language search without additional label data. We evaluate the effectiveness of this map in single and multi-object searches. We also investigate its compatibility with a Large Language Model as an "affordance query resolver". Code and videos are available at https://intelligolabs.github.io/Le-RNR-Map/
Unsupervised Active Visual Search with Monte Carlo planning under Uncertain Detections
Mar 06, 2023



We propose a solution for Active Visual Search of objects in an environment, whose 2D floor map is the only known information. Our solution has three key features that make it more plausible and robust to detector failures compared to state-of-the-art methods: (i) it is unsupervised as it does not need any training sessions. (ii) During the exploration, a probability distribution on the 2D floor map is updated according to an intuitive mechanism, while an improved belief update increases the effectiveness of the agent's exploration. (iii) We incorporate the awareness that an object detector may fail into the aforementioned probability modelling by exploiting the success statistics of a specific detector. Our solution is dubbed POMP-BE-PD (Pomcp-based Online Motion Planning with Belief by Exploration and Probabilistic Detection). It uses the current pose of an agent and an RGB-D observation to learn an optimal search policy, exploiting a POMDP solved by a Monte-Carlo planning approach. On the Active Vision Database benchmark, we increase the average success rate over all the environments by a significant 35% while decreasing the average path length by 4% with respect to competing methods. Thus, our results are state-of-the-art, even without using any training procedure.