 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLourdes Agapito
HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Apr 01, 2024
We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
NViST: In the Wild New View Synthesis from a Single Image with Transformers
Dec 13, 2023We propose NViST, a transformer-based model for novel-view synthesis from a single image, trained on a large-scale dataset of in-the-wild images with complex backgrounds. NViST transforms image inputs directly into a radiance field, adopting a scalable transformer-based architecture. In practice, NViST exploits the self-supervised features learnt by a masked autoencoder (MAE), and learns a novel decoder that translates features to 3D tokens via cross-attention and adaptive layer normalization. Our model is efficient at inference since only a single forward-pass is needed to predict a 3D representation, unlike methods that require test-time optimization or sampling such as 3D-aware diffusion models. We tackle further limitations of current new-view synthesis models. First, unlike most generative models that are trained in a category-specific manner, often on synthetic datasets or on masked inputs, our model is trained on MVImgNet, a large-scale dataset of real-world, casually-captured videos containing hundreds of object categories with diverse backgrounds. Secondly, our model does not require canonicalization of the training data - i.e. aligning all objects with a frontal view - only needing relative pose at training time which removes a substantial barrier to it being used on casually captured datasets. We show results on unseen objects and categories on MVImgNet and even casual phone captures. We conduct qualitative and quantitative evaluations on MVImgNet and ShapeNet to show that our model represents a step forward towards enabling true in-the-wild novel-view synthesis from a single image.
MonoNPHM: Dynamic Head Reconstruction from Monocular Videos
Dec 11, 2023We present Monocular Neural Parametric Head Models (MonoNPHM) for dynamic 3D head reconstructions from monocular RGB videos. To this end, we propose a latent appearance space that parameterizes a texture field on top of a neural parametric model. We constrain predicted color values to be correlated with the underlying geometry such that gradients from RGB effectively influence latent geometry codes during inverse rendering. To increase the representational capacity of our expression space, we augment our backward deformation field with hyper-dimensions, thus improving color and geometry representation in topologically challenging expressions. Using MonoNPHM as a learned prior, we approach the task of 3D head reconstruction using signed distance field based volumetric rendering. By numerically inverting our backward deformation field, we incorporated a landmark loss using facial anchor points that are closely tied to our canonical geometry representation. To evaluate the task of dynamic face reconstruction from monocular RGB videos we record 20 challenging Kinect sequences under casual conditions. MonoNPHM outperforms all baselines with a significant margin, and makes an important step towards easily accessible neural parametric face models through RGB tracking.
MorpheuS: Neural Dynamic 360° Surface Reconstruction from Monocular RGB-D Video
Dec 01, 2023Neural rendering has demonstrated remarkable success in dynamic scene reconstruction. Thanks to the expressiveness of neural representations, prior works can accurately capture the motion and achieve high-fidelity reconstruction of the target object. Despite this, real-world video scenarios often feature large unobserved regions where neural representations struggle to achieve realistic completion. To tackle this challenge, we introduce MorpheuS, a framework for dynamic 360{\deg} surface reconstruction from a casually captured RGB-D video. Our approach models the target scene as a canonical field that encodes its geometry and appearance, in conjunction with a deformation field that warps points from the current frame to the canonical space. We leverage a view-dependent diffusion prior and distill knowledge from it to achieve realistic completion of unobserved regions. Experimental results on various real-world and synthetic datasets show that our method can achieve high-fidelity 360{\deg} surface reconstruction of a deformable object from a monocular RGB-D video.
DynamicSurf: Dynamic Neural RGB-D Surface Reconstruction with an Optimizable Feature Grid
Nov 14, 2023We propose DynamicSurf, a model-free neural implicit surface reconstruction method for high-fidelity 3D modelling of non-rigid surfaces from monocular RGB-D video. To cope with the lack of multi-view cues in monocular sequences of deforming surfaces, one of the most challenging settings for 3D reconstruction, DynamicSurf exploits depth, surface normals, and RGB losses to improve reconstruction fidelity and optimisation time. DynamicSurf learns a neural deformation field that maps a canonical representation of the surface geometry to the current frame. We depart from current neural non-rigid surface reconstruction models by designing the canonical representation as a learned feature grid which leads to faster and more accurate surface reconstruction than competing approaches that use a single MLP. We demonstrate DynamicSurf on public datasets and show that it can optimize sequences of varying frames with $6\times$ speedup over pure MLP-based approaches while achieving comparable results to the state-of-the-art methods. Project is available at https://mirgahney.github.io//DynamicSurf.io/.
Task-guided Domain Gap Reduction for Monocular Depth Prediction in Endoscopy
Oct 02, 2023Colorectal cancer remains one of the deadliest cancers in the world. In recent years computer-aided methods have aimed to enhance cancer screening and improve the quality and availability of colonoscopies by automatizing sub-tasks. One such task is predicting depth from monocular video frames, which can assist endoscopic navigation. As ground truth depth from standard in-vivo colonoscopy remains unobtainable due to hardware constraints, two approaches have aimed to circumvent the need for real training data: supervised methods trained on labeled synthetic data and self-supervised models trained on unlabeled real data. However, self-supervised methods depend on unreliable loss functions that struggle with edges, self-occlusion, and lighting inconsistency. Methods trained on synthetic data can provide accurate depth for synthetic geometries but do not use any geometric supervisory signal from real data and overfit to synthetic anatomies and properties. This work proposes a novel approach to leverage labeled synthetic and unlabeled real data. While previous domain adaptation methods indiscriminately enforce the distributions of both input data modalities to coincide, we focus on the end task, depth prediction, and translate only essential information between the input domains. Our approach results in more resilient and accurate depth maps of real colonoscopy sequences.
* First Data Engineering in Medical Imaging Workshop at MICCAI 2023
RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation
Aug 31, 2023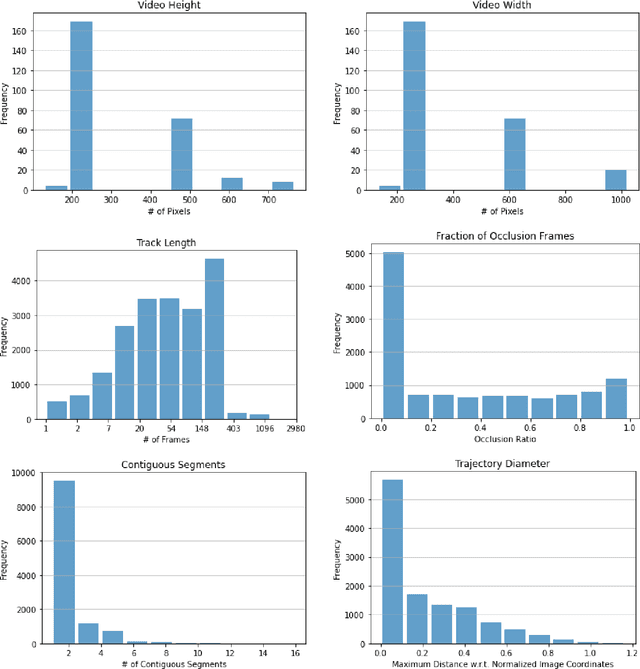
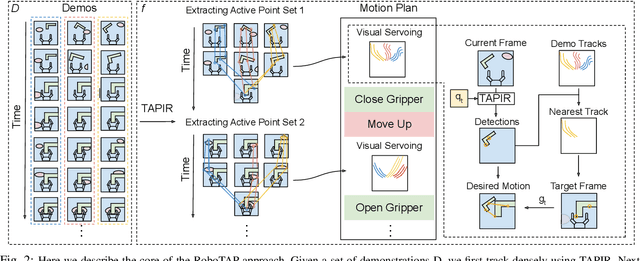


For robots to be useful outside labs and specialized factories we need a way to teach them new useful behaviors quickly. Current approaches lack either the generality to onboard new tasks without task-specific engineering, or else lack the data-efficiency to do so in an amount of time that enables practical use. In this work we explore dense tracking as a representational vehicle to allow faster and more general learning from demonstration. Our approach utilizes Track-Any-Point (TAP) models to isolate the relevant motion in a demonstration, and parameterize a low-level controller to reproduce this motion across changes in the scene configuration. We show this results in robust robot policies that can solve complex object-arrangement tasks such as shape-matching, stacking, and even full path-following tasks such as applying glue and sticking objects together, all from demonstrations that can be collected in minutes.
SeMLaPS: Real-time Semantic Mapping with Latent Prior Networks and Quasi-Planar Segmentation
Jun 28, 2023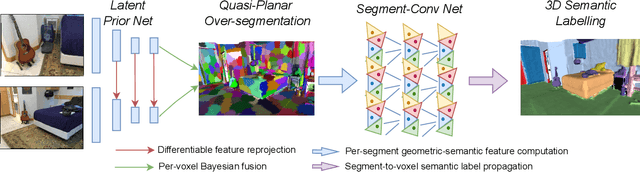
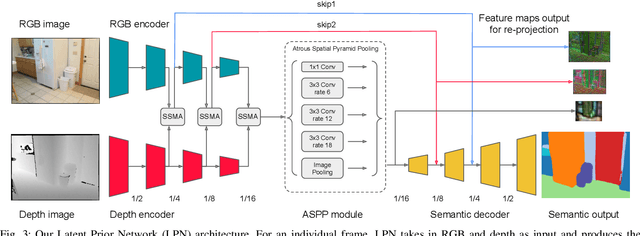
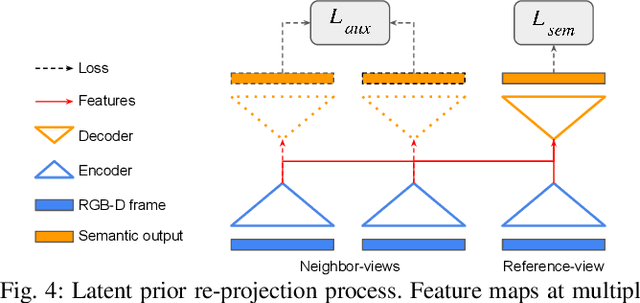
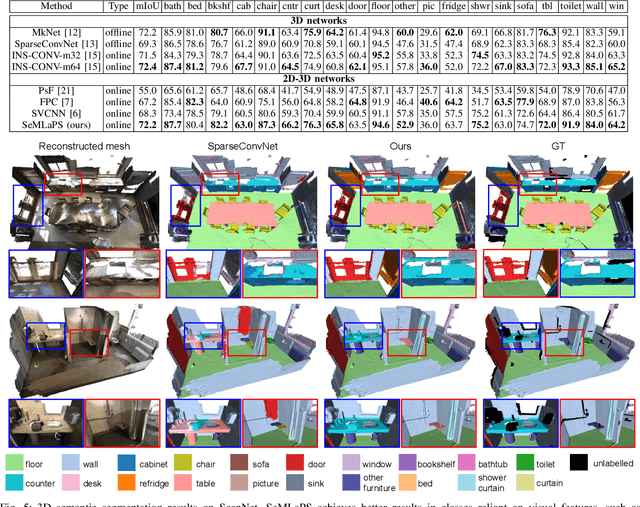
The availability of real-time semantics greatly improves the core geometric functionality of SLAM systems, enabling numerous robotic and AR/VR applications. We present a new methodology for real-time semantic mapping from RGB-D sequences that combines a 2D neural network and a 3D network based on a SLAM system with 3D occupancy mapping. When segmenting a new frame we perform latent feature re-projection from previous frames based on differentiable rendering. Fusing re-projected feature maps from previous frames with current-frame features greatly improves image segmentation quality, compared to a baseline that processes images independently. For 3D map processing, we propose a novel geometric quasi-planar over-segmentation method that groups 3D map elements likely to belong to the same semantic classes, relying on surface normals. We also describe a novel neural network design for lightweight semantic map post-processing. Our system achieves state-of-the-art semantic mapping quality within 2D-3D networks-based systems and matches the performance of 3D convolutional networks on three real indoor datasets, while working in real-time. Moreover, it shows better cross-sensor generalization abilities compared to 3D CNNs, enabling training and inference with different depth sensors. Code and data will be released on project page: http://jingwenwang95.github.io/SeMLaPS
HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion
May 11, 2023
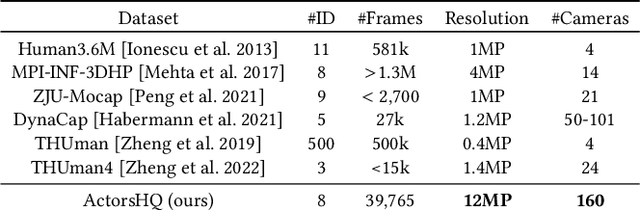

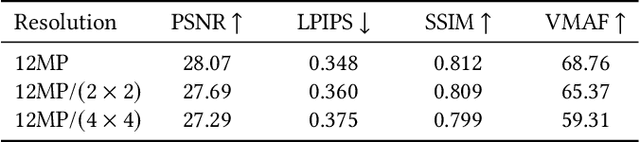
Representing human performance at high-fidelity is an essential building block in diverse applications, such as film production, computer games or videoconferencing. To close the gap to production-level quality, we introduce HumanRF, a 4D dynamic neural scene representation that captures full-body appearance in motion from multi-view video input, and enables playback from novel, unseen viewpoints. Our novel representation acts as a dynamic video encoding that captures fine details at high compression rates by factorizing space-time into a temporal matrix-vector decomposition. This allows us to obtain temporally coherent reconstructions of human actors for long sequences, while representing high-resolution details even in the context of challenging motion. While most research focuses on synthesizing at resolutions of 4MP or lower, we address the challenge of operating at 12MP. To this end, we introduce ActorsHQ, a novel multi-view dataset that provides 12MP footage from 160 cameras for 16 sequences with high-fidelity, per-frame mesh reconstructions. We demonstrate challenges that emerge from using such high-resolution data and show that our newly introduced HumanRF effectively leverages this data, making a significant step towards production-level quality novel view synthesis.
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Apr 27, 2023We present Co-SLAM, a neural RGB-D SLAM system based on a hybrid representation, that performs robust camera tracking and high-fidelity surface reconstruction in real time. Co-SLAM represents the scene as a multi-resolution hash-grid to exploit its high convergence speed and ability to represent high-frequency local features. In addition, Co-SLAM incorporates one-blob encoding, to encourage surface coherence and completion in unobserved areas. This joint parametric-coordinate encoding enables real-time and robust performance by bringing the best of both worlds: fast convergence and surface hole filling. Moreover, our ray sampling strategy allows Co-SLAM to perform global bundle adjustment over all keyframes instead of requiring keyframe selection to maintain a small number of active keyframes as competing neural SLAM approaches do. Experimental results show that Co-SLAM runs at 10-17Hz and achieves state-of-the-art scene reconstruction results, and competitive tracking performance in various datasets and benchmarks (ScanNet, TUM, Replica, Synthetic RGBD). Project page: https://hengyiwang.github.io/projects/CoSLAM