 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiang He
Neuro-Vision to Language: Image Reconstruction and Language enabled Interaction via Brain Recordings
May 01, 2024
Decoding non-invasive brain recordings is crucial for advancing our understanding of human cognition, yet faces challenges from individual differences and complex neural signal representations. Traditional methods require custom models and extensive trials, and lack interpretability in visual reconstruction tasks. Our framework integrating integrates 3D brain structures with visual semantics by Vision Transformer 3D. The unified feature extractor aligns fMRI features with multiple levels of visual embeddings efficiently, removing the need for individual-specific models and allowing extraction from single-trial data. This extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with various fMRI-image related textual data to support multimodal large model development. The integration with LLMs enhances decoding capabilities, enabling tasks like brain captioning, question-answering, detailed descriptions, complex reasoning, and visual reconstruction. Our approach not only shows superior performance across these tasks but also precisely identifies and manipulates language-based concepts within brain signals, enhancing interpretability and providing deeper neural process insights. These advances significantly broaden non-invasive brain decoding applicability in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
Light-weight Retinal Layer Segmentation with Global Reasoning
Apr 25, 2024Automatic retinal layer segmentation with medical images, such as optical coherence tomography (OCT) images, serves as an important tool for diagnosing ophthalmic diseases. However, it is challenging to achieve accurate segmentation due to low contrast and blood flow noises presented in the images. In addition, the algorithm should be light-weight to be deployed for practical clinical applications. Therefore, it is desired to design a light-weight network with high performance for retinal layer segmentation. In this paper, we propose LightReSeg for retinal layer segmentation which can be applied to OCT images. Specifically, our approach follows an encoder-decoder structure, where the encoder part employs multi-scale feature extraction and a Transformer block for fully exploiting the semantic information of feature maps at all scales and making the features have better global reasoning capabilities, while the decoder part, we design a multi-scale asymmetric attention (MAA) module for preserving the semantic information at each encoder scale. The experiments show that our approach achieves a better segmentation performance compared to the current state-of-the-art method TransUnet with 105.7M parameters on both our collected dataset and two other public datasets, with only 3.3M parameters.
SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
Mar 28, 2024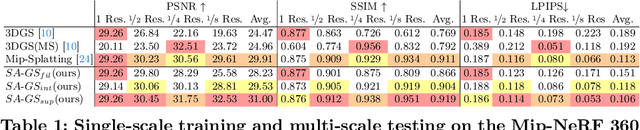
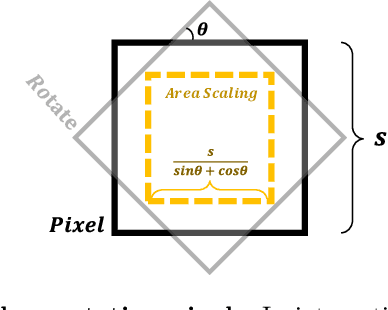

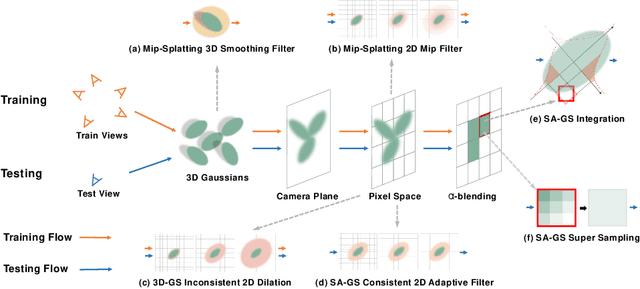
In this paper, we present a Scale-adaptive method for Anti-aliasing Gaussian Splatting (SA-GS). While the state-of-the-art method Mip-Splatting needs modifying the training procedure of Gaussian splatting, our method functions at test-time and is training-free. Specifically, SA-GS can be applied to any pretrained Gaussian splatting field as a plugin to significantly improve the field's anti-alising performance. The core technique is to apply 2D scale-adaptive filters to each Gaussian during test time. As pointed out by Mip-Splatting, observing Gaussians at different frequencies leads to mismatches between the Gaussian scales during training and testing. Mip-Splatting resolves this issue using 3D smoothing and 2D Mip filters, which are unfortunately not aware of testing frequency. In this work, we show that a 2D scale-adaptive filter that is informed of testing frequency can effectively match the Gaussian scale, thus making the Gaussian primitive distribution remain consistent across different testing frequencies. When scale inconsistency is eliminated, sampling rates smaller than the scene frequency result in conventional jaggedness, and we propose to integrate the projected 2D Gaussian within each pixel during testing. This integration is actually a limiting case of super-sampling, which significantly improves anti-aliasing performance over vanilla Gaussian Splatting. Through extensive experiments using various settings and both bounded and unbounded scenes, we show SA-GS performs comparably with or better than Mip-Splatting. Note that super-sampling and integration are only effective when our scale-adaptive filtering is activated. Our codes, data and models are available at https://github.com/zsy1987/SA-GS.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
Efficient Training Spiking Neural Networks with Parallel Spiking Unit
Feb 02, 2024Efficient parallel computing has become a pivotal element in advancing artificial intelligence. Yet, the deployment of Spiking Neural Networks (SNNs) in this domain is hampered by their inherent sequential computational dependency. This constraint arises from the need for each time step's processing to rely on the preceding step's outcomes, significantly impeding the adaptability of SNN models to massively parallel computing environments. Addressing this challenge, our paper introduces the innovative Parallel Spiking Unit (PSU) and its two derivatives, the Input-aware PSU (IPSU) and Reset-aware PSU (RPSU). These variants skillfully decouple the leaky integration and firing mechanisms in spiking neurons while probabilistically managing the reset process. By preserving the fundamental computational attributes of the spiking neuron model, our approach enables the concurrent computation of all membrane potential instances within the SNN, facilitating parallel spike output generation and substantially enhancing computational efficiency. Comprehensive testing across various datasets, including static and sequential images, Dynamic Vision Sensor (DVS) data, and speech datasets, demonstrates that the PSU and its variants not only significantly boost performance and simulation speed but also augment the energy efficiency of SNNs through enhanced sparsity in neural activity. These advancements underscore the potential of our method in revolutionizing SNN deployment for high-performance parallel computing applications.
A Survey on Deep Neural Network Partition over Cloud, Edge and End Devices
Apr 20, 2023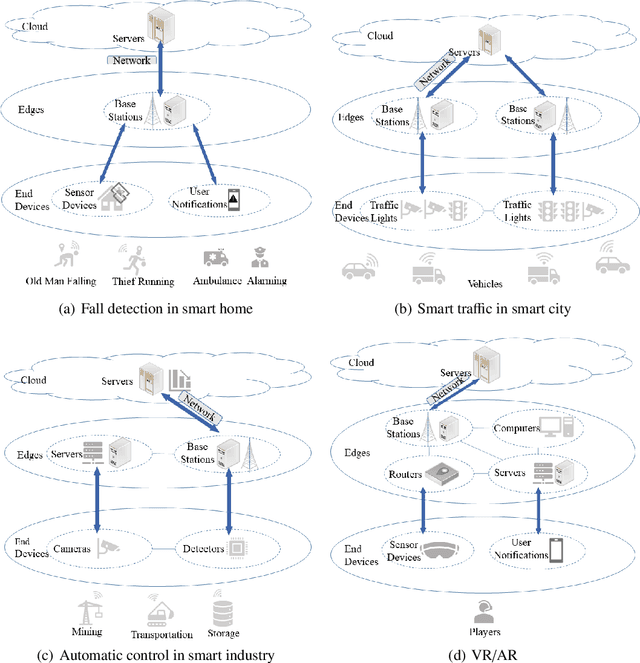
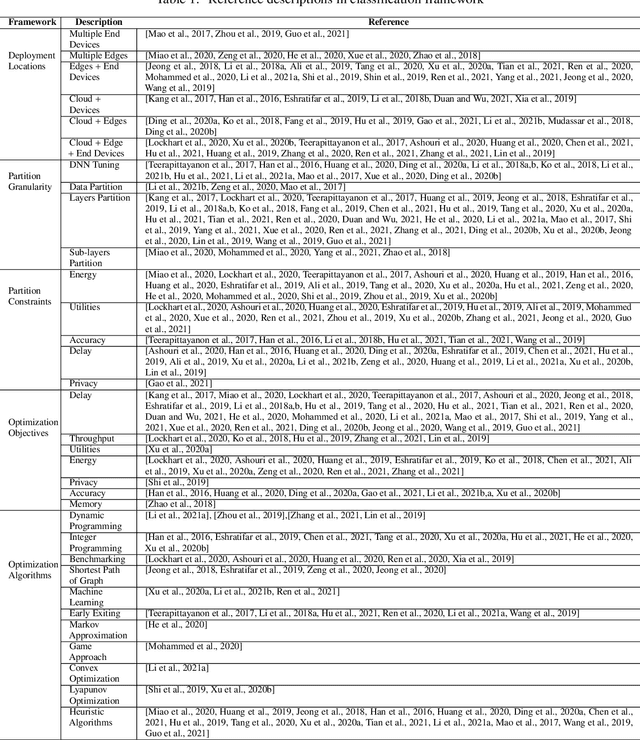
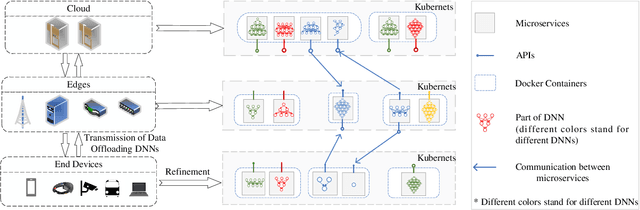
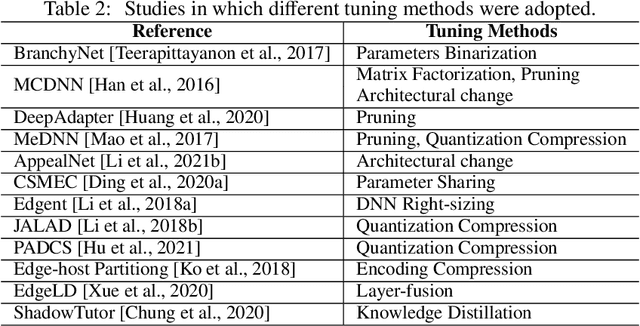
Deep neural network (DNN) partition is a research problem that involves splitting a DNN into multiple parts and offloading them to specific locations. Because of the recent advancement in multi-access edge computing and edge intelligence, DNN partition has been considered as a powerful tool for improving DNN inference performance when the computing resources of edge and end devices are limited and the remote transmission of data from these devices to clouds is costly. This paper provides a comprehensive survey on the recent advances and challenges in DNN partition approaches over the cloud, edge, and end devices based on a detailed literature collection. We review how DNN partition works in various application scenarios, and provide a unified mathematical model of the DNN partition problem. We developed a five-dimensional classification framework for DNN partition approaches, consisting of deployment locations, partition granularity, partition constraints, optimization objectives, and optimization algorithms. Each existing DNN partition approache can be perfectly defined in this framework by instantiating each dimension into specific values. In addition, we suggest a set of metrics for comparing and evaluating the DNN partition approaches. Based on this, we identify and discuss research challenges that have not yet been investigated or fully addressed. We hope that this work helps DNN partition researchers by highlighting significant future research directions in this domain.
Improving the Performance of Spiking Neural Networks on Event-based Datasets with Knowledge Transfer
Mar 23, 2023
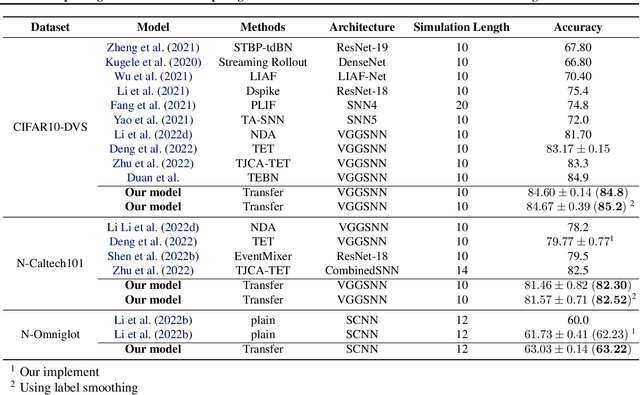
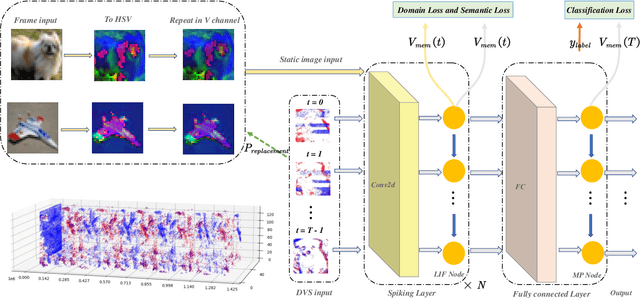
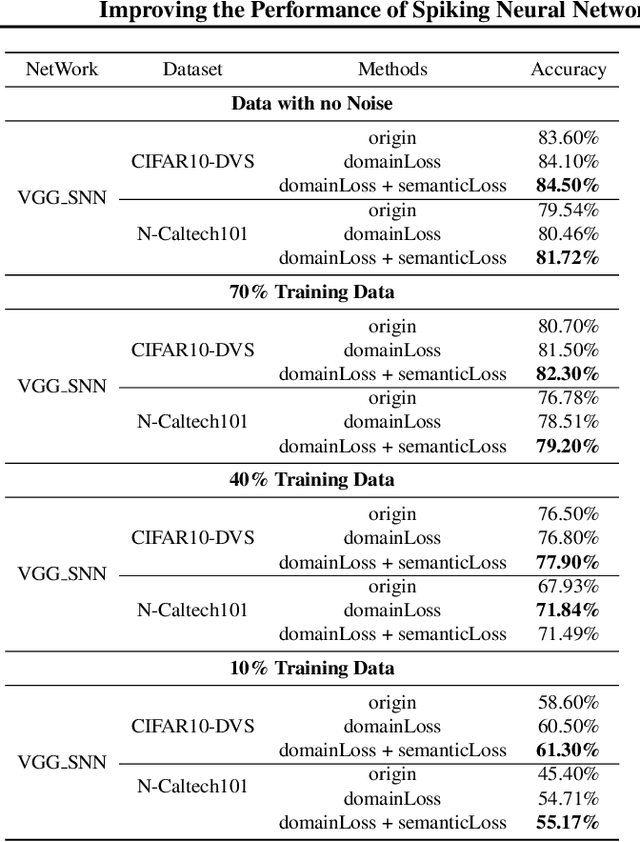
Spiking neural networks (SNNs) have rich spatial-temporal dynamics, which are suitable for processing neuromorphic, event-based data. However, event-based datasets are usually less annotated than static datasets used in traditional deep learning. Small data scale makes SNNs prone to overfitting and limits the performance of the SNN. To enhance the generalizability of SNNs on event-based datasets, we propose a knowledge-transfer framework that leverages static images to assist in the training on neuromorphic datasets. Our method proposes domain loss and semantic loss to exploit both domain-invariant and unique features of these two domains, providing SNNs with more generalized knowledge for subsequent targeted training on neuromorphic data. Specifically, domain loss aligns the feature space and aims to capture common features between static and event-based images, while semantic loss emphasizes that the differences between samples from different categories should be as large as possible. Experimental results demonstrate that our method outperforms existing methods on all mainstream neuromorphic vision datasets. In particular, we achieve significant performance improvement of 2.7\% and 9.8\% when using only 10\% training data of CIFAR10-DVS and N-Caltech 101 datasets, respectively.
MSAT: Biologically Inspired Multi-Stage Adaptive Threshold for Conversion of Spiking Neural Networks
Mar 23, 2023
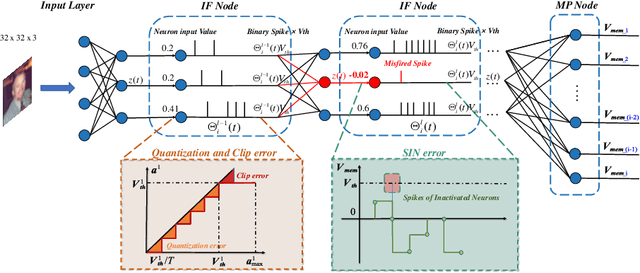
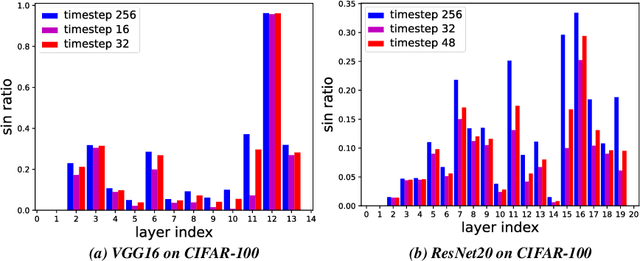
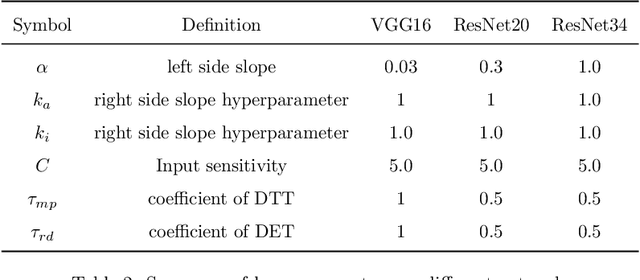
Spiking Neural Networks (SNNs) can do inference with low power consumption due to their spike sparsity. ANN-SNN conversion is an efficient way to achieve deep SNNs by converting well-trained Artificial Neural Networks (ANNs). However, the existing methods commonly use constant threshold for conversion, which prevents neurons from rapidly delivering spikes to deeper layers and causes high time delay. In addition, the same response for different inputs may result in information loss during the information transmission. Inspired by the biological model mechanism, we propose a multi-stage adaptive threshold (MSAT). Specifically, for each neuron, the dynamic threshold varies with firing history and input properties and is positively correlated with the average membrane potential and negatively correlated with the rate of depolarization. The self-adaptation to membrane potential and input allows a timely adjustment of the threshold to fire spike faster and transmit more information. Moreover, we analyze the Spikes of Inactivated Neurons error which is pervasive in early time steps and propose spike confidence accordingly as a measurement of confidence about the neurons that correctly deliver spikes. We use such spike confidence in early time steps to determine whether to elicit spike to alleviate this error. Combined with the proposed method, we examine the performance on non-trivial datasets CIFAR-10, CIFAR-100, and ImageNet. We also conduct sentiment classification and speech recognition experiments on the IDBM and Google speech commands datasets respectively. Experiments show near-lossless and lower latency ANN-SNN conversion. To the best of our knowledge, this is the first time to build a biologically inspired multi-stage adaptive threshold for converted SNN, with comparable performance to state-of-the-art methods while improving energy efficiency.
Spike Calibration: Fast and Accurate Conversion of Spiking Neural Network for Object Detection and Segmentation
Jul 06, 2022
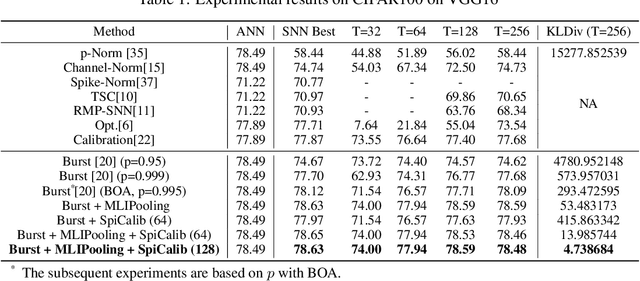
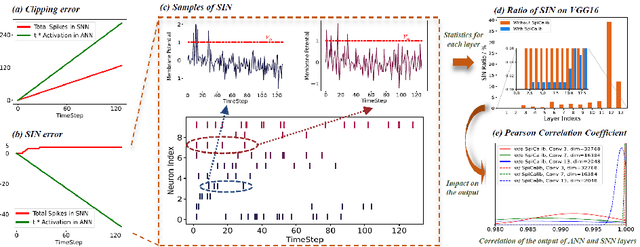
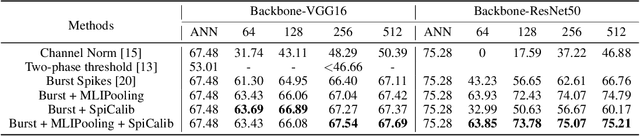
Spiking neural network (SNN) has been attached to great importance due to the properties of high biological plausibility and low energy consumption on neuromorphic hardware. As an efficient method to obtain deep SNN, the conversion method has exhibited high performance on various large-scale datasets. However, it typically suffers from severe performance degradation and high time delays. In particular, most of the previous work focuses on simple classification tasks while ignoring the precise approximation to ANN output. In this paper, we first theoretically analyze the conversion errors and derive the harmful effects of time-varying extremes on synaptic currents. We propose the Spike Calibration (SpiCalib) to eliminate the damage of discrete spikes to the output distribution and modify the LIPooling to allow conversion of the arbitrary MaxPooling layer losslessly. Moreover, Bayesian optimization for optimal normalization parameters is proposed to avoid empirical settings. The experimental results demonstrate the state-of-the-art performance on classification, object detection, and segmentation tasks. To the best of our knowledge, this is the first time to obtain SNN comparable to ANN on these tasks simultaneously. Moreover, we only need 1/50 inference time of the previous work on the detection task and can achieve the same performance under 0.492$\times$ energy consumption of ANN on the segmentation task.
Magic Pyramid: Accelerating Inference with Early Exiting and Token Pruning
Oct 30, 2021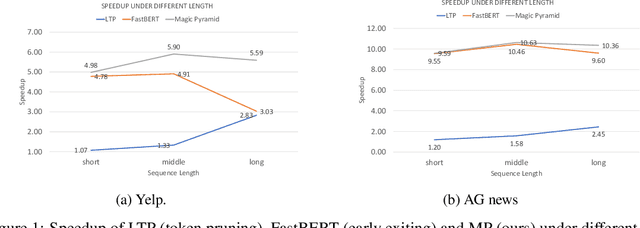
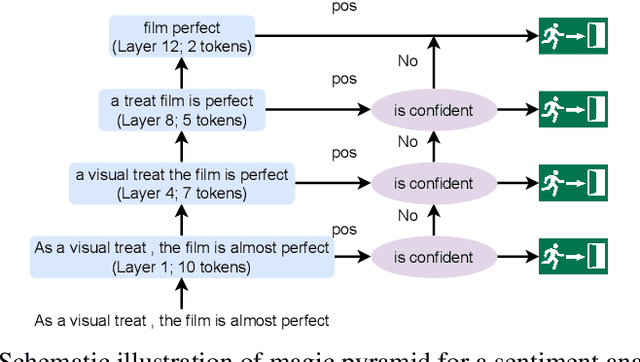
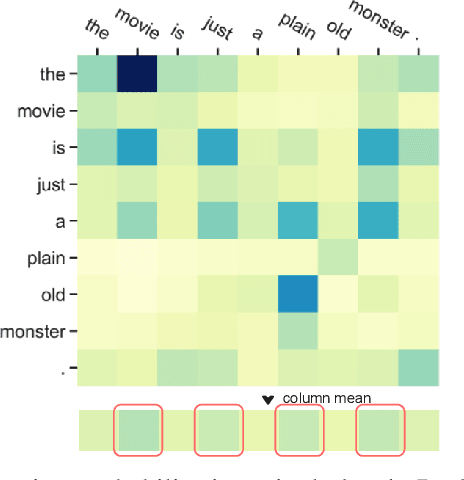
Pre-training and then fine-tuning large language models is commonly used to achieve state-of-the-art performance in natural language processing (NLP) tasks. However, most pre-trained models suffer from low inference speed. Deploying such large models to applications with latency constraints is challenging. In this work, we focus on accelerating the inference via conditional computations. To achieve this, we propose a novel idea, Magic Pyramid (MP), to reduce both width-wise and depth-wise computation via token pruning and early exiting for Transformer-based models, particularly BERT. The former manages to save the computation via removing non-salient tokens, while the latter can fulfill the computation reduction by terminating the inference early before reaching the final layer, if the exiting condition is met. Our empirical studies demonstrate that compared to previous state of arts, MP is not only able to achieve a speed-adjustable inference but also to surpass token pruning and early exiting by reducing up to 70% giga floating point operations (GFLOPs) with less than 0.5% accuracy drop. Token pruning and early exiting express distinctive preferences to sequences with different lengths. However, MP is capable of achieving an average of 8.06x speedup on two popular text classification tasks, regardless of the sizes of the inputs.