 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuobin Shen
Neuro-Vision to Language: Image Reconstruction and Language enabled Interaction via Brain Recordings
May 01, 2024
Decoding non-invasive brain recordings is crucial for advancing our understanding of human cognition, yet faces challenges from individual differences and complex neural signal representations. Traditional methods require custom models and extensive trials, and lack interpretability in visual reconstruction tasks. Our framework integrating integrates 3D brain structures with visual semantics by Vision Transformer 3D. The unified feature extractor aligns fMRI features with multiple levels of visual embeddings efficiently, removing the need for individual-specific models and allowing extraction from single-trial data. This extractor consolidates multi-level visual features into one network, simplifying integration with Large Language Models (LLMs). Additionally, we have enhanced the fMRI dataset with various fMRI-image related textual data to support multimodal large model development. The integration with LLMs enhances decoding capabilities, enabling tasks like brain captioning, question-answering, detailed descriptions, complex reasoning, and visual reconstruction. Our approach not only shows superior performance across these tasks but also precisely identifies and manipulates language-based concepts within brain signals, enhancing interpretability and providing deeper neural process insights. These advances significantly broaden non-invasive brain decoding applicability in neuroscience and human-computer interaction, setting the stage for advanced brain-computer interfaces and cognitive models.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
TIM: An Efficient Temporal Interaction Module for Spiking Transformer
Jan 23, 2024Spiking Neural Networks (SNNs), as the third generation of neural networks, have gained prominence for their biological plausibility and computational efficiency, especially in processing diverse datasets. The integration of attention mechanisms, inspired by advancements in neural network architectures, has led to the development of Spiking Transformers. These have shown promise in enhancing SNNs' capabilities, particularly in the realms of both static and neuromorphic datasets. Despite their progress, a discernible gap exists in these systems, specifically in the Spiking Self Attention (SSA) mechanism's effectiveness in leveraging the temporal processing potential of SNNs. To address this, we introduce the Temporal Interaction Module (TIM), a novel, convolution-based enhancement designed to augment the temporal data processing abilities within SNN architectures. TIM's integration into existing SNN frameworks is seamless and efficient, requiring minimal additional parameters while significantly boosting their temporal information handling capabilities. Through rigorous experimentation, TIM has demonstrated its effectiveness in exploiting temporal information, leading to state-of-the-art performance across various neuromorphic datasets.
Astrocyte-Enabled Advancements in Spiking Neural Networks for Large Language Modeling
Dec 26, 2023Within the complex neuroarchitecture of the brain, astrocytes play crucial roles in development, structure, and metabolism. These cells regulate neural activity through tripartite synapses, directly impacting cognitive processes such as learning and memory. Despite the growing recognition of astrocytes' significance, traditional Spiking Neural Network (SNN) models remain predominantly neuron-centric, overlooking the profound influence of astrocytes on neural dynamics. Inspired by these biological insights, we have developed an Astrocyte-Modulated Spiking Unit (AM-SU), an innovative framework that integrates neuron-astrocyte interactions into the computational paradigm, demonstrating wide applicability across various hardware platforms. Our Astrocyte-Modulated Spiking Neural Network (AstroSNN) exhibits exceptional performance in tasks involving memory retention and natural language generation, particularly in handling long-term dependencies and complex linguistic structures. The design of AstroSNN not only enhances its biological authenticity but also introduces novel computational dynamics, enabling more effective processing of complex temporal dependencies. Furthermore, AstroSNN shows low latency, high throughput, and reduced memory usage in practical applications, making it highly suitable for resource-constrained environments. By successfully integrating astrocytic dynamics into intelligent neural networks, our work narrows the gap between biological plausibility and neural modeling, laying the groundwork for future biologically-inspired neural computing research that includes both neurons and astrocytes.
Is Conventional SNN Really Efficient? A Perspective from Network Quantization
Nov 17, 2023Spiking Neural Networks (SNNs) have been widely praised for their high energy efficiency and immense potential. However, comprehensive research that critically contrasts and correlates SNNs with quantized Artificial Neural Networks (ANNs) remains scant, often leading to skewed comparisons lacking fairness towards ANNs. This paper introduces a unified perspective, illustrating that the time steps in SNNs and quantized bit-widths of activation values present analogous representations. Building on this, we present a more pragmatic and rational approach to estimating the energy consumption of SNNs. Diverging from the conventional Synaptic Operations (SynOps), we champion the "Bit Budget" concept. This notion permits an intricate discourse on strategically allocating computational and storage resources between weights, activation values, and temporal steps under stringent hardware constraints. Guided by the Bit Budget paradigm, we discern that pivoting efforts towards spike patterns and weight quantization, rather than temporal attributes, elicits profound implications for model performance. Utilizing the Bit Budget for holistic design consideration of SNNs elevates model performance across diverse data types, encompassing static imagery and neuromorphic datasets. Our revelations bridge the theoretical chasm between SNNs and quantized ANNs and illuminate a pragmatic trajectory for future endeavors in energy-efficient neural computations.
FireFly v2: Advancing Hardware Support for High-Performance Spiking Neural Network with a Spatiotemporal FPGA Accelerator
Sep 28, 2023Spiking Neural Networks (SNNs) are expected to be a promising alternative to Artificial Neural Networks (ANNs) due to their strong biological interpretability and high energy efficiency. Specialized SNN hardware offers clear advantages over general-purpose devices in terms of power and performance. However, there's still room to advance hardware support for state-of-the-art (SOTA) SNN algorithms and improve computation and memory efficiency. As a further step in supporting high-performance SNNs on specialized hardware, we introduce FireFly v2, an FPGA SNN accelerator that can address the issue of non-spike operation in current SOTA SNN algorithms, which presents an obstacle in the end-to-end deployment onto existing SNN hardware. To more effectively align with the SNN characteristics, we design a spatiotemporal dataflow that allows four dimensions of parallelism and eliminates the need for membrane potential storage, enabling on-the-fly spike processing and spike generation. To further improve hardware acceleration performance, we develop a high-performance spike computing engine as a backend based on a systolic array operating at 500-600MHz. To the best of our knowledge, FireFly v2 achieves the highest clock frequency among all FPGA-based implementations. Furthermore, it stands as the first SNN accelerator capable of supporting non-spike operations, which are commonly used in advanced SNN algorithms. FireFly v2 has doubled the throughput and DSP efficiency when compared to our previous version of FireFly and it exhibits 1.33 times the DSP efficiency and 1.42 times the power efficiency compared to the current most advanced FPGA accelerators.
Metaplasticity: Unifying Learning and Homeostatic Plasticity in Spiking Neural Networks
Aug 23, 2023



The natural evolution of the human brain has given rise to multiple forms of synaptic plasticity, allowing for dynamic changes to adapt to an ever-evolving world. The evolutionary development of synaptic plasticity has spurred our exploration of biologically plausible optimization and learning algorithms for Spiking Neural Networks (SNNs). Present neural networks rely on the direct training of synaptic weights, which ultimately leads to fixed connections and hampers their ability to adapt to dynamic real-world environments. To address this challenge, we introduce the application of metaplasticity -- a sophisticated mechanism involving the learning of plasticity rules rather than direct modifications of synaptic weights. Metaplasticity dynamically combines different plasticity rules, effectively enhancing working memory, multitask generalization, and adaptability while uncovering potential associations between various forms of plasticity and cognitive functions. By integrating metaplasticity into SNNs, we demonstrate the enhanced adaptability and cognitive capabilities within artificial intelligence systems. This computational perspective unveils the learning mechanisms of the brain, marking a significant step in the profound intersection of neuroscience and artificial intelligence.
Enhancing Efficient Continual Learning with Dynamic Structure Development of Spiking Neural Networks
Aug 09, 2023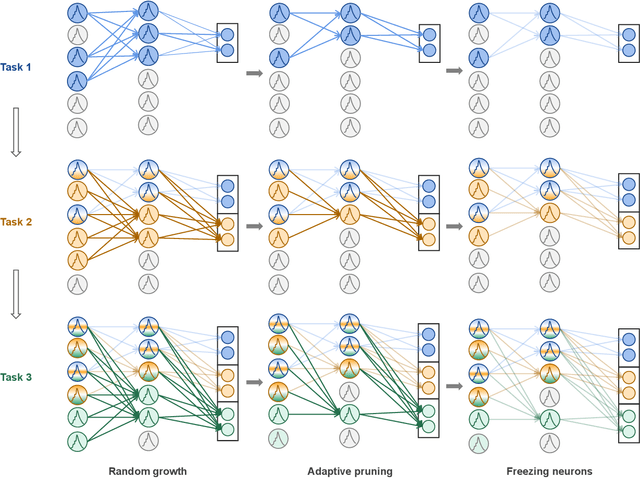
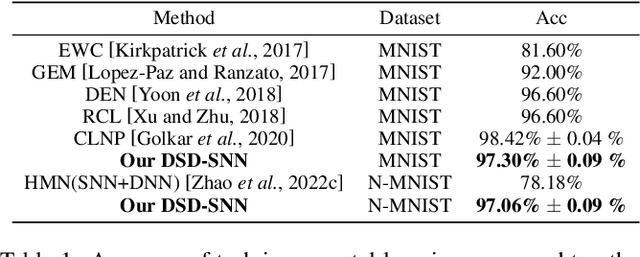
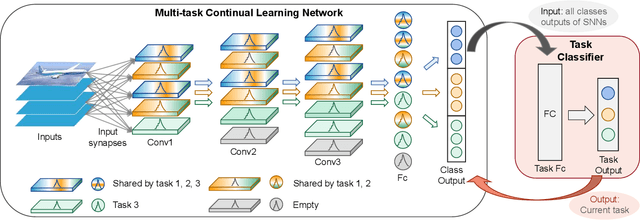
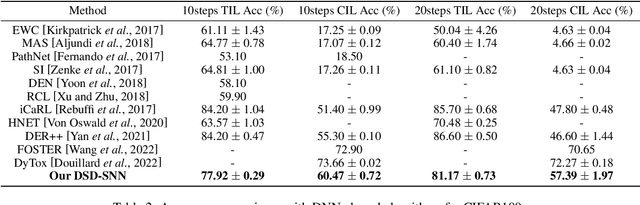
Children possess the ability to learn multiple cognitive tasks sequentially, which is a major challenge toward the long-term goal of artificial general intelligence. Existing continual learning frameworks are usually applicable to Deep Neural Networks (DNNs) and lack the exploration on more brain-inspired, energy-efficient Spiking Neural Networks (SNNs). Drawing on continual learning mechanisms during child growth and development, we propose Dynamic Structure Development of Spiking Neural Networks (DSD-SNN) for efficient and adaptive continual learning. When learning a sequence of tasks, the DSD-SNN dynamically assigns and grows new neurons to new tasks and prunes redundant neurons, thereby increasing memory capacity and reducing computational overhead. In addition, the overlapping shared structure helps to quickly leverage all acquired knowledge to new tasks, empowering a single network capable of supporting multiple incremental tasks (without the separate sub-network mask for each task). We validate the effectiveness of the proposed model on multiple class incremental learning and task incremental learning benchmarks. Extensive experiments demonstrated that our model could significantly improve performance, learning speed and memory capacity, and reduce computational overhead. Besides, our DSD-SNN model achieves comparable performance with the DNNs-based methods, and significantly outperforms the state-of-the-art (SOTA) performance for existing SNNs-based continual learning methods.
Bullying10K: A Neuromorphic Dataset towards Privacy-Preserving Bullying Recognition
Jun 20, 2023



The prevalence of violence in daily life poses significant threats to individuals' physical and mental well-being. Using surveillance cameras in public spaces has proven effective in proactively deterring and preventing such incidents. However, concerns regarding privacy invasion have emerged due to their widespread deployment. To address the problem, we leverage Dynamic Vision Sensors (DVS) cameras to detect violent incidents and preserve privacy since it captures pixel brightness variations instead of static imagery. We introduce the Bullying10K dataset, encompassing various actions, complex movements, and occlusions from real-life scenarios. It provides three benchmarks for evaluating different tasks: action recognition, temporal action localization, and pose estimation. With 10,000 event segments, totaling 12 billion events and 255 GB of data, Bullying10K contributes significantly by balancing violence detection and personal privacy persevering. And it also poses a challenge to the neuromorphic dataset. It will serve as a valuable resource for training and developing privacy-protecting video systems. The Bullying10K opens new possibilities for innovative approaches in these domains.
Improving Stability and Performance of Spiking Neural Networks through Enhancing Temporal Consistency
May 23, 2023



Spiking neural networks have gained significant attention due to their brain-like information processing capabilities. The use of surrogate gradients has made it possible to train spiking neural networks with backpropagation, leading to impressive performance in various tasks. However, spiking neural networks trained with backpropagation typically approximate actual labels using the average output, often necessitating a larger simulation timestep to enhance the network's performance. This delay constraint poses a challenge to the further advancement of SNNs. Current training algorithms tend to overlook the differences in output distribution at various timesteps. Particularly for neuromorphic datasets, inputs at different timesteps can cause inconsistencies in output distribution, leading to a significant deviation from the optimal direction when combining optimization directions from different moments. To tackle this issue, we have designed a method to enhance the temporal consistency of outputs at different timesteps. We have conducted experiments on static datasets such as CIFAR10, CIFAR100, and ImageNet. The results demonstrate that our algorithm can achieve comparable performance to other optimal SNN algorithms. Notably, our algorithm has achieved state-of-the-art performance on neuromorphic datasets DVS-CIFAR10 and N-Caltech101, and can achieve superior performance in the test phase with timestep T=1.