 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJin Wang
Research on emotionally intelligent dialogue generation based on automatic dialogue system
Apr 17, 2024
Automated dialogue systems are important applications of artificial intelligence, and traditional systems struggle to understand user emotions and provide empathetic feedback. This study integrates emotional intelligence technology into automated dialogue systems and creates a dialogue generation model with emotional intelligence through deep learning and natural language processing techniques. The model can detect and understand a wide range of emotions and specific pain signals in real time, enabling the system to provide empathetic interaction. By integrating the results of the study "Can artificial intelligence detect pain and express pain empathy?", the model's ability to understand the subtle elements of pain empathy has been enhanced, setting higher standards for emotional intelligence dialogue systems. The project aims to provide theoretical understanding and practical suggestions to integrate advanced emotional intelligence capabilities into dialogue systems, thereby improving user experience and interaction quality.
HiGraphDTI: Hierarchical Graph Representation Learning for Drug-Target Interaction Prediction
Apr 16, 2024The discovery of drug-target interactions (DTIs) plays a crucial role in pharmaceutical development. The deep learning model achieves more accurate results in DTI prediction due to its ability to extract robust and expressive features from drug and target chemical structures. However, existing deep learning methods typically generate drug features via aggregating molecular atom representations, ignoring the chemical properties carried by motifs, i.e., substructures of the molecular graph. The atom-drug double-level molecular representation learning can not fully exploit structure information and fails to interpret the DTI mechanism from the motif perspective. In addition, sequential model-based target feature extraction either fuses limited contextual information or requires expensive computational resources. To tackle the above issues, we propose a hierarchical graph representation learning-based DTI prediction method (HiGraphDTI). Specifically, HiGraphDTI learns hierarchical drug representations from triple-level molecular graphs to thoroughly exploit chemical information embedded in atoms, motifs, and molecules. Then, an attentional feature fusion module incorporates information from different receptive fields to extract expressive target features.Last, the hierarchical attention mechanism identifies crucial molecular segments, which offers complementary views for interpreting interaction mechanisms. The experiment results not only demonstrate the superiority of HiGraphDTI to the state-of-the-art methods, but also confirm the practical ability of our model in interaction interpretation and new DTI discovery.
The application of Augmented Reality (AR) in Remote Work and Education
Apr 16, 2024With the rapid advancement of technology, Augmented Reality (AR) technology, known for its ability to deeply integrate virtual information with the real world, is gradually transforming traditional work modes and teaching methods. Particularly in the realms of remote work and online education, AR technology demonstrates a broad spectrum of application prospects. This paper delves into the application potential and actual effects of AR technology in remote work and education. Through a systematic literature review, this study outlines the key features, advantages, and challenges of AR technology. Based on theoretical analysis, it discusses the scientific basis and technical support that AR technology provides for enhancing remote work efficiency and promoting innovation in educational teaching models. Additionally, by designing an empirical research plan and analyzing experimental data, this article reveals the specific performance and influencing factors of AR technology in practical applications. Finally, based on the results of the experiments, this research summarizes the application value of AR technology in remote work and education, looks forward to its future development trends, and proposes forward-looking research directions and strategic suggestions, offering empirical foundation and theoretical guidance for further promoting the in-depth application of AR technology in related fields.
Event-assisted Low-Light Video Object Segmentation
Apr 02, 2024In the realm of video object segmentation (VOS), the challenge of operating under low-light conditions persists, resulting in notably degraded image quality and compromised accuracy when comparing query and memory frames for similarity computation. Event cameras, characterized by their high dynamic range and ability to capture motion information of objects, offer promise in enhancing object visibility and aiding VOS methods under such low-light conditions. This paper introduces a pioneering framework tailored for low-light VOS, leveraging event camera data to elevate segmentation accuracy. Our approach hinges on two pivotal components: the Adaptive Cross-Modal Fusion (ACMF) module, aimed at extracting pertinent features while fusing image and event modalities to mitigate noise interference, and the Event-Guided Memory Matching (EGMM) module, designed to rectify the issue of inaccurate matching prevalent in low-light settings. Additionally, we present the creation of a synthetic LLE-DAVIS dataset and the curation of a real-world LLE-VOS dataset, encompassing frames and events. Experimental evaluations corroborate the efficacy of our method across both datasets, affirming its effectiveness in low-light scenarios.
Multi-Label Adaptive Batch Selection by Highlighting Hard and Imbalanced Samples
Mar 27, 2024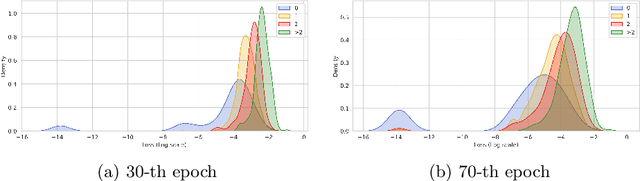
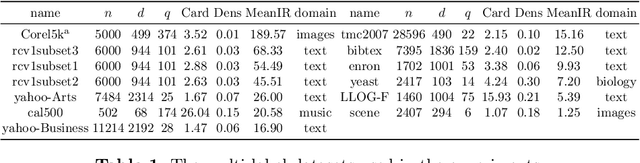

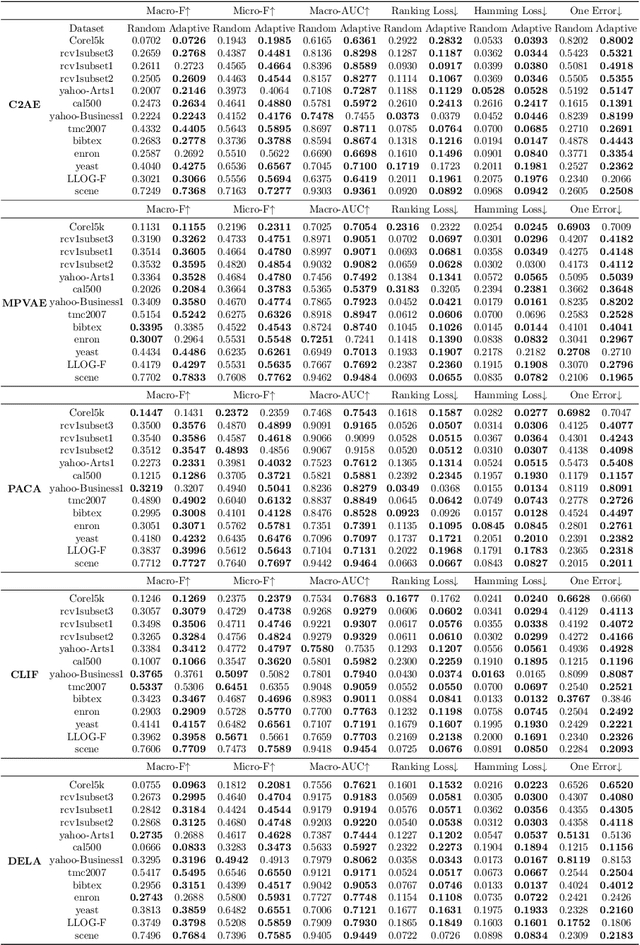
Deep neural network models have demonstrated their effectiveness in classifying multi-label data from various domains. Typically, they employ a training mode that combines mini-batches with optimizers, where each sample is randomly selected with equal probability when constructing mini-batches. However, the intrinsic class imbalance in multi-label data may bias the model towards majority labels, since samples relevant to minority labels may be underrepresented in each mini-batch. Meanwhile, during the training process, we observe that instances associated with minority labels tend to induce greater losses. Existing heuristic batch selection methods, such as priority selection of samples with high contribution to the objective function, i.e., samples with high loss, have been proven to accelerate convergence while reducing the loss and test error in single-label data. However, batch selection methods have not yet been applied and validated in multi-label data. In this study, we introduce a simple yet effective adaptive batch selection algorithm tailored to multi-label deep learning models. It adaptively selects each batch by prioritizing hard samples related to minority labels. A variant of our method also takes informative label correlations into consideration. Comprehensive experiments combining five multi-label deep learning models on thirteen benchmark datasets show that our method converges faster and performs better than random batch selection.
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024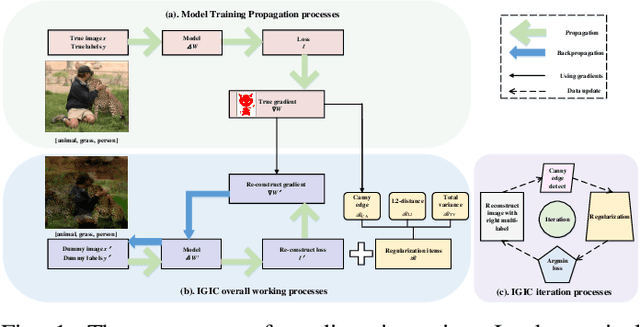
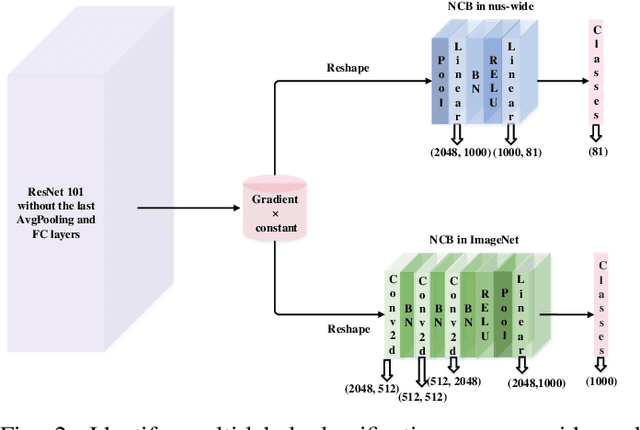


As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
RAF-GI: Towards Robust, Accurate and Fast-Convergent Gradient Inversion Attack in Federated Learning
Mar 13, 2024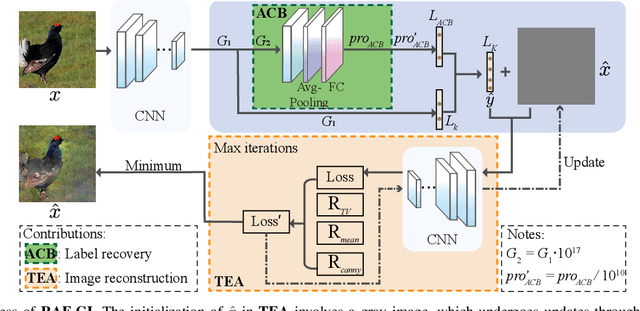


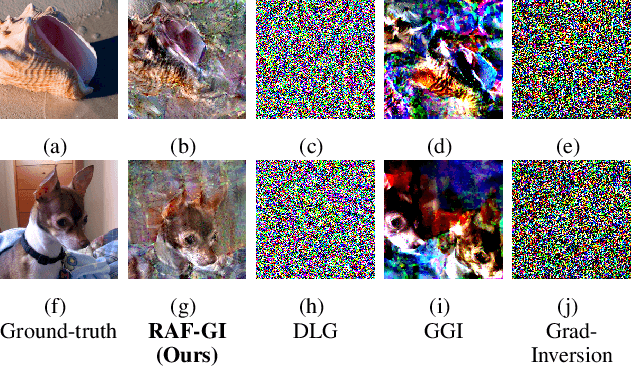
Federated learning (FL) empowers privacy-preservation in model training by only exposing users' model gradients. Yet, FL users are susceptible to the gradient inversion (GI) attack which can reconstruct ground-truth training data such as images based on model gradients. However, reconstructing high-resolution images by existing GI attack works faces two challenges: inferior accuracy and slow-convergence, especially when the context is complicated, e.g., the training batch size is much greater than 1 on each FL user. To address these challenges, we present a Robust, Accurate and Fast-convergent GI attack algorithm, called RAF-GI, with two components: 1) Additional Convolution Block (ACB) which can restore labels with up to 20% improvement compared with existing works; 2) Total variance, three-channel mEan and cAnny edge detection regularization term (TEA), which is a white-box attack strategy to reconstruct images based on labels inferred by ACB. Moreover, RAF-GI is robust that can still accurately reconstruct ground-truth data when the users' training batch size is no more than 48. Our experimental results manifest that RAF-GI can diminish 94% time costs while achieving superb inversion quality in ImageNet dataset. Notably, with a batch size of 1, RAF-GI exhibits a 7.89 higher Peak Signal-to-Noise Ratio (PSNR) compared to the state-of-the-art baselines.
Personalized LoRA for Human-Centered Text Understanding
Mar 10, 2024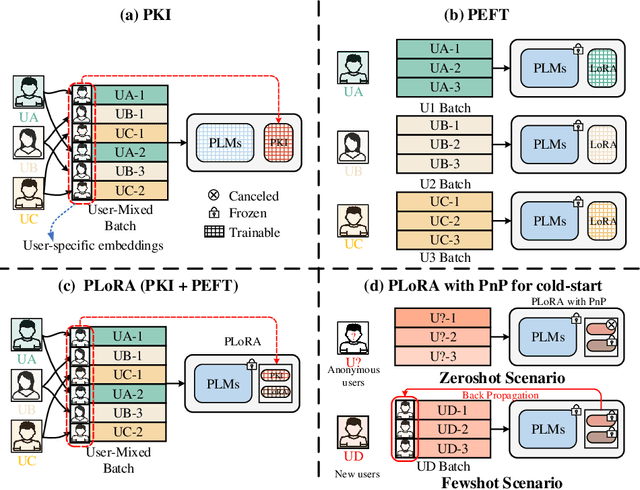
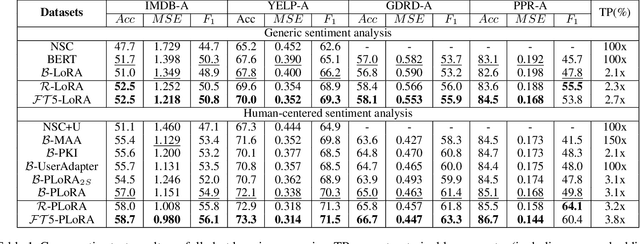
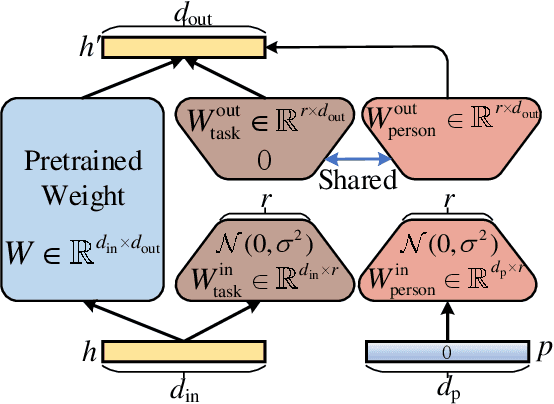
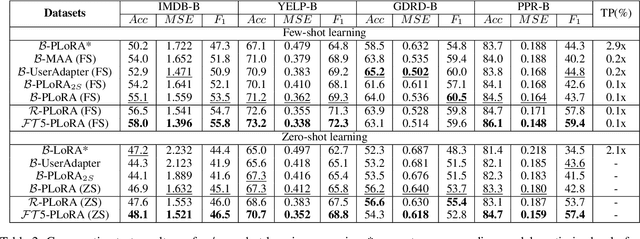
Effectively and efficiently adapting a pre-trained language model (PLM) for human-centered text understanding (HCTU) is challenging since user tokens are million-level in most personalized applications and do not have concrete explicit semantics. A standard and parameter-efficient approach (e.g., LoRA) necessitates memorizing numerous suits of adapters for each user. In this work, we introduce a personalized LoRA (PLoRA) with a plug-and-play (PnP) framework for the HCTU task. PLoRA is effective, parameter-efficient, and dynamically deploying in PLMs. Moreover, a personalized dropout and a mutual information maximizing strategies are adopted and hence the proposed PLoRA can be well adapted to few/zero-shot learning scenarios for the cold-start issue. Experiments conducted on four benchmark datasets show that the proposed method outperforms existing methods in full/few/zero-shot learning scenarios for the HCTU task, even though it has fewer trainable parameters. For reproducibility, the code for this paper is available at: https://github.com/yoyo-yun/PLoRA.
Brain-inspired and Self-based Artificial Intelligence
Feb 29, 2024The question "Can machines think?" and the Turing Test to assess whether machines could achieve human-level intelligence is one of the roots of AI. With the philosophical argument "I think, therefore I am", this paper challenge the idea of a "thinking machine" supported by current AIs since there is no sense of self in them. Current artificial intelligence is only seemingly intelligent information processing and does not truly understand or be subjectively aware of oneself and perceive the world with the self as human intelligence does. In this paper, we introduce a Brain-inspired and Self-based Artificial Intelligence (BriSe AI) paradigm. This BriSe AI paradigm is dedicated to coordinating various cognitive functions and learning strategies in a self-organized manner to build human-level AI models and robotic applications. Specifically, BriSe AI emphasizes the crucial role of the Self in shaping the future AI, rooted with a practical hierarchical Self framework, including Perception and Learning, Bodily Self, Autonomous Self, Social Self, and Conceptual Self. The hierarchical framework of the Self highlights self-based environment perception, self-bodily modeling, autonomous interaction with the environment, social interaction and collaboration with others, and even more abstract understanding of the Self. Furthermore, the positive mutual promotion and support among multiple levels of Self, as well as between Self and learning, enhance the BriSe AI's conscious understanding of information and flexible adaptation to complex environments, serving as a driving force propelling BriSe AI towards real Artificial General Intelligence.
UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
Nov 28, 2023Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.