 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAo Zhou
HiGraphDTI: Hierarchical Graph Representation Learning for Drug-Target Interaction Prediction
Apr 16, 2024
The discovery of drug-target interactions (DTIs) plays a crucial role in pharmaceutical development. The deep learning model achieves more accurate results in DTI prediction due to its ability to extract robust and expressive features from drug and target chemical structures. However, existing deep learning methods typically generate drug features via aggregating molecular atom representations, ignoring the chemical properties carried by motifs, i.e., substructures of the molecular graph. The atom-drug double-level molecular representation learning can not fully exploit structure information and fails to interpret the DTI mechanism from the motif perspective. In addition, sequential model-based target feature extraction either fuses limited contextual information or requires expensive computational resources. To tackle the above issues, we propose a hierarchical graph representation learning-based DTI prediction method (HiGraphDTI). Specifically, HiGraphDTI learns hierarchical drug representations from triple-level molecular graphs to thoroughly exploit chemical information embedded in atoms, motifs, and molecules. Then, an attentional feature fusion module incorporates information from different receptive fields to extract expressive target features.Last, the hierarchical attention mechanism identifies crucial molecular segments, which offers complementary views for interpreting interaction mechanisms. The experiment results not only demonstrate the superiority of HiGraphDTI to the state-of-the-art methods, but also confirm the practical ability of our model in interaction interpretation and new DTI discovery.
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Apr 08, 2024The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9\times$ speedup and $98.2\%$ energy reduction compared to existing approaches across various applications and system configurations.
Multi-Label Adaptive Batch Selection by Highlighting Hard and Imbalanced Samples
Mar 27, 2024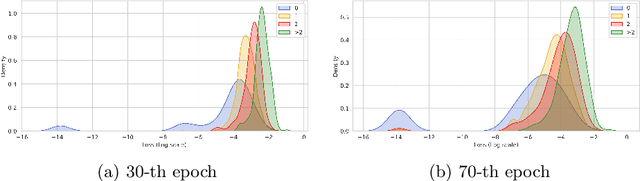

Deep neural network models have demonstrated their effectiveness in classifying multi-label data from various domains. Typically, they employ a training mode that combines mini-batches with optimizers, where each sample is randomly selected with equal probability when constructing mini-batches. However, the intrinsic class imbalance in multi-label data may bias the model towards majority labels, since samples relevant to minority labels may be underrepresented in each mini-batch. Meanwhile, during the training process, we observe that instances associated with minority labels tend to induce greater losses. Existing heuristic batch selection methods, such as priority selection of samples with high contribution to the objective function, i.e., samples with high loss, have been proven to accelerate convergence while reducing the loss and test error in single-label data. However, batch selection methods have not yet been applied and validated in multi-label data. In this study, we introduce a simple yet effective adaptive batch selection algorithm tailored to multi-label deep learning models. It adaptively selects each batch by prioritizing hard samples related to minority labels. A variant of our method also takes informative label correlations into consideration. Comprehensive experiments combining five multi-label deep learning models on thirteen benchmark datasets show that our method converges faster and performs better than random batch selection.
FedRDMA: Communication-Efficient Cross-Silo Federated LLM via Chunked RDMA Transmission
Mar 01, 2024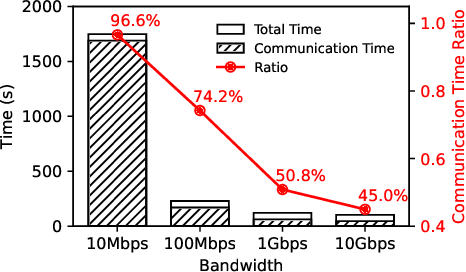

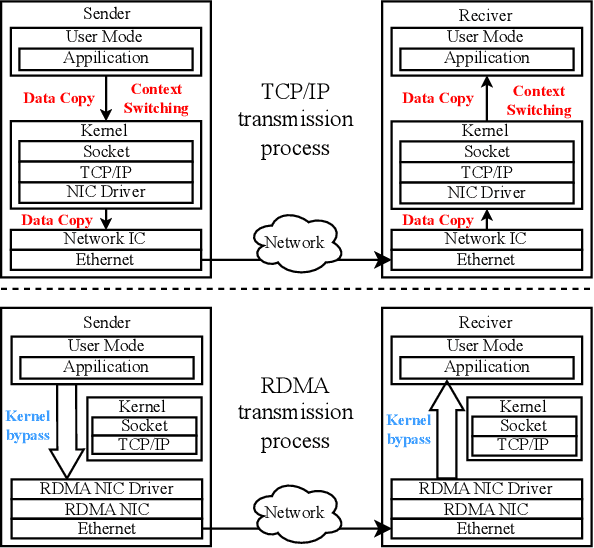
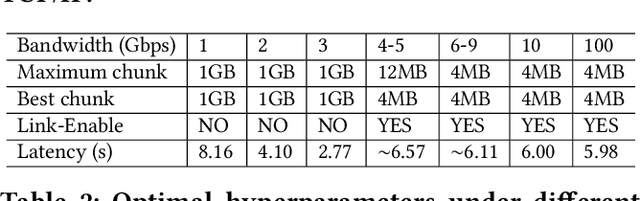
Communication overhead is a significant bottleneck in federated learning (FL), which has been exaggerated with the increasing size of AI models. In this paper, we propose FedRDMA, a communication-efficient cross-silo FL system that integrates RDMA into the FL communication protocol. To overcome the limitations of RDMA in wide-area networks (WANs), FedRDMA divides the updated model into chunks and designs a series of optimization techniques to improve the efficiency and robustness of RDMA-based communication. We implement FedRDMA atop the industrial federated learning framework and evaluate it on a real-world cross-silo FL scenario. The experimental results show that \sys can achieve up to 3.8$\times$ speedup in communication efficiency compared to traditional TCP/IP-based FL systems.
Architectural Implications of GNN Aggregation Programming Abstractions
Oct 21, 2023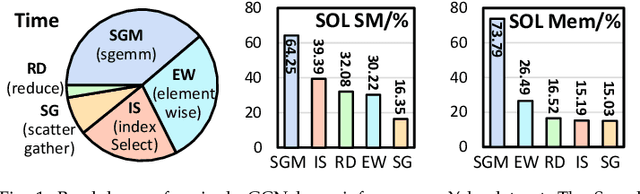


Graph neural networks (GNNs) have gained significant popularity due to the powerful capability to extract useful representations from graph data. As the need for efficient GNN computation intensifies, a variety of programming abstractions designed for optimizing GNN Aggregation have emerged to facilitate acceleration. However, there is no comprehensive evaluation and analysis upon existing abstractions, thus no clear consensus on which approach is better. In this letter, we classify existing programming abstractions for GNN Aggregation by the dimension of data organization and propagation method. By constructing these abstractions on a state-of-the-art GNN library, we perform a thorough and detailed characterization study to compare their performance and efficiency, and provide several insights on future GNN acceleration based on our analysis.
EdgeMoE: Fast On-Device Inference of MoE-based Large Language Models
Aug 28, 2023Large Language Models (LLMs) such as GPTs and LLaMa have ushered in a revolution in machine intelligence, owing to their exceptional capabilities in a wide range of machine learning tasks. However, the transition of LLMs from data centers to edge devices presents a set of challenges and opportunities. While this shift can enhance privacy and availability, it is hampered by the enormous parameter sizes of these models, leading to impractical runtime costs. In light of these considerations, we introduce EdgeMoE, the first on-device inference engine tailored for mixture-of-expert (MoE) LLMs, a popular variant of sparse LLMs that exhibit nearly constant computational complexity as their parameter size scales. EdgeMoE achieves both memory and computational efficiency by strategically partitioning the model across the storage hierarchy. Specifically, non-expert weights are stored in the device's memory, while expert weights are kept in external storage and are fetched into memory only when they are activated. This design is underpinned by a crucial insight that expert weights, though voluminous, are infrequently accessed due to sparse activation patterns. To further mitigate the overhead associated with expert I/O swapping, EdgeMoE incorporates two innovative techniques: (1) Expert-wise bitwidth adaptation: This method reduces the size of expert weights with an acceptable level of accuracy loss. (2) Expert management: It predicts the experts that will be activated in advance and preloads them into the compute-I/O pipeline, thus further optimizing the process. In empirical evaluations conducted on well-established MoE LLMs and various edge devices, EdgeMoE demonstrates substantial memory savings and performance improvements when compared to competitive baseline solutions.
Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms
Mar 20, 2023
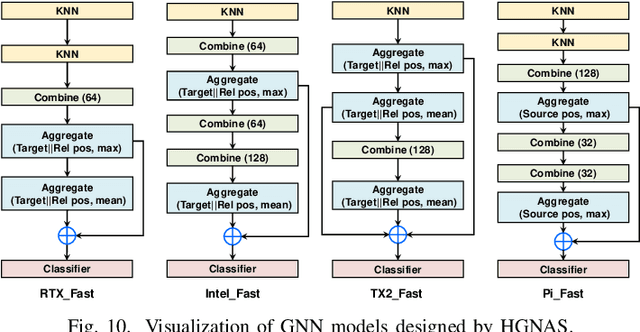

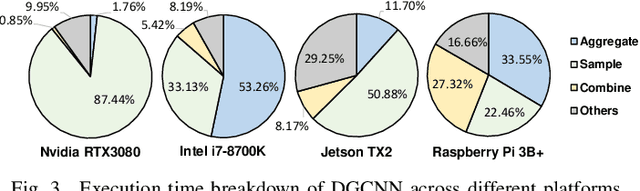
Graph neural networks (GNNs) have emerged as a popular strategy for handling non-Euclidean data due to their state-of-the-art performance. However, most of the current GNN model designs mainly focus on task accuracy, lacking in considering hardware resources limitation and real-time requirements of edge application scenarios. Comprehensive profiling of typical GNN models indicates that their execution characteristics are significantly affected across different computing platforms, which demands hardware awareness for efficient GNN designs. In this work, HGNAS is proposed as the first Hardware-aware Graph Neural Architecture Search framework targeting resource constraint edge devices. By decoupling the GNN paradigm, HGNAS constructs a fine-grained design space and leverages an efficient multi-stage search strategy to explore optimal architectures within a few GPU hours. Moreover, HGNAS achieves hardware awareness during the GNN architecture design by leveraging a hardware performance predictor, which could balance the GNN model accuracy and efficiency corresponding to the characteristics of targeted devices. Experimental results show that HGNAS can achieve about $10.6\times$ speedup and $88.2\%$ peak memory reduction with a negligible accuracy loss compared to DGCNN on various edge devices, including Nvidia RTX3080, Jetson TX2, Intel i7-8700K and Raspberry Pi 3B+.
Understanding and Optimizing Deep Learning Cold-Start Latency on Edge Devices
Jun 15, 2022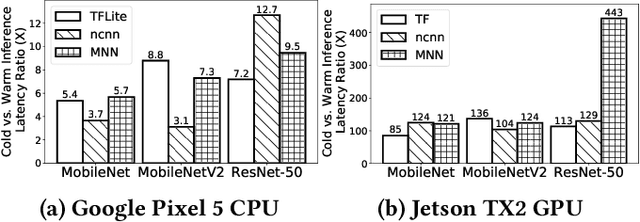
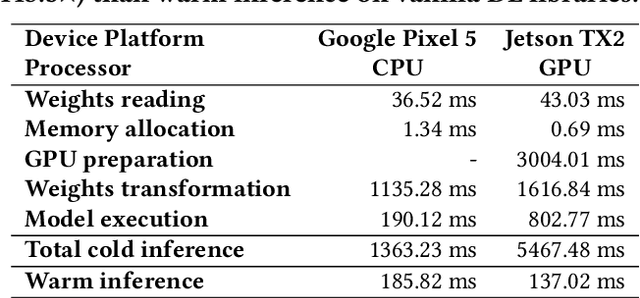
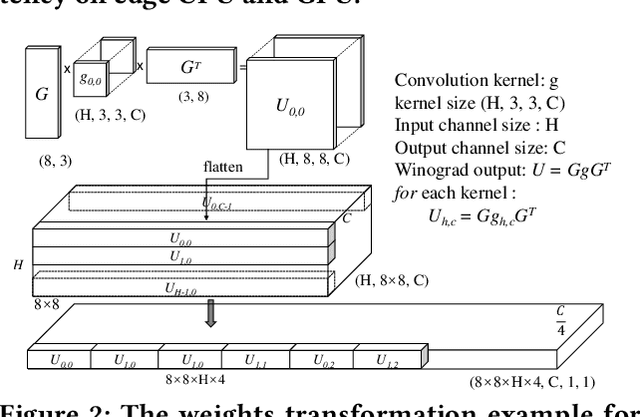
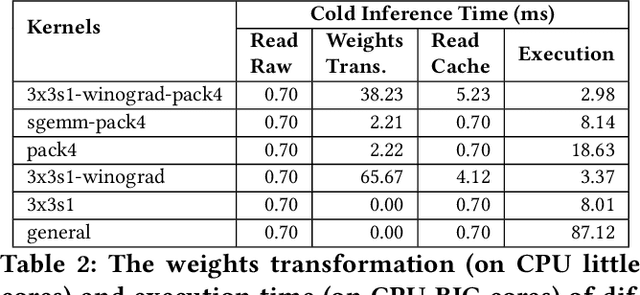
DNNs are ubiquitous on edge devices nowadays. With its increasing importance and use cases, it's not likely to pack all DNNs into device memory and expect that each inference has been warmed up. Therefore, cold inference, the process to read, initialize, and execute a DNN model, is becoming commonplace and its performance is urgently demanded to be optimized. To this end, we present NNV12, the first on-device inference engine that optimizes for cold inference NNV12 is built atop 3 novel optimization knobs: selecting a proper kernel (implementation) for each DNN operator, bypassing the weights transformation process by caching the post-transformed weights on disk, and pipelined execution of many kernels on asymmetric processors. To tackle with the huge search space, NNV12 employs a heuristic-based scheme to obtain a near-optimal kernel scheduling plan. We fully implement a prototype of NNV12 and evaluate its performance across extensive experiments. It shows that NNV12 achieves up to 15.2x and 401.5x compared to the state-of-the-art DNN engines on edge CPUs and GPUs, respectively.
A Comprehensive Benchmark of Deep Learning Libraries on Mobile Devices
Feb 14, 2022

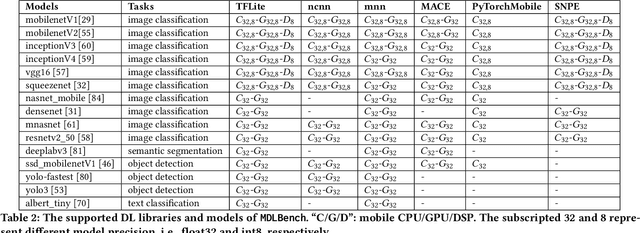

Deploying deep learning (DL) on mobile devices has been a notable trend in recent years. To support fast inference of on-device DL, DL libraries play a critical role as algorithms and hardware do. Unfortunately, no prior work ever dives deep into the ecosystem of modern DL libs and provides quantitative results on their performance. In this paper, we first build a comprehensive benchmark that includes 6 representative DL libs and 15 diversified DL models. We then perform extensive experiments on 10 mobile devices, which help reveal a complete landscape of the current mobile DL libs ecosystem. For example, we find that the best-performing DL lib is severely fragmented across different models and hardware, and the gap between those DL libs can be rather huge. In fact, the impacts of DL libs can overwhelm the optimizations from algorithms or hardware, e.g., model quantization and GPU/DSP-based heterogeneous computing. Finally, atop the observations, we summarize practical implications to different roles in the DL lib ecosystem.