 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTong Qiao
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024
Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Apr 08, 2024The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9\times$ speedup and $98.2\%$ energy reduction compared to existing approaches across various applications and system configurations.
Architectural Implications of GNN Aggregation Programming Abstractions
Oct 21, 2023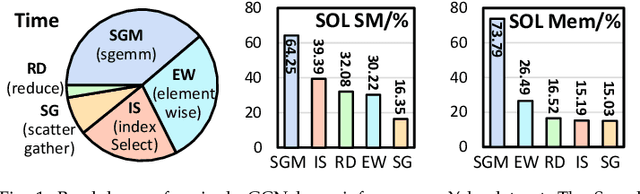


Graph neural networks (GNNs) have gained significant popularity due to the powerful capability to extract useful representations from graph data. As the need for efficient GNN computation intensifies, a variety of programming abstractions designed for optimizing GNN Aggregation have emerged to facilitate acceleration. However, there is no comprehensive evaluation and analysis upon existing abstractions, thus no clear consensus on which approach is better. In this letter, we classify existing programming abstractions for GNN Aggregation by the dimension of data organization and propagation method. By constructing these abstractions on a state-of-the-art GNN library, we perform a thorough and detailed characterization study to compare their performance and efficiency, and provide several insights on future GNN acceleration based on our analysis.
Hardware-Aware Graph Neural Network Automated Design for Edge Computing Platforms
Mar 20, 2023
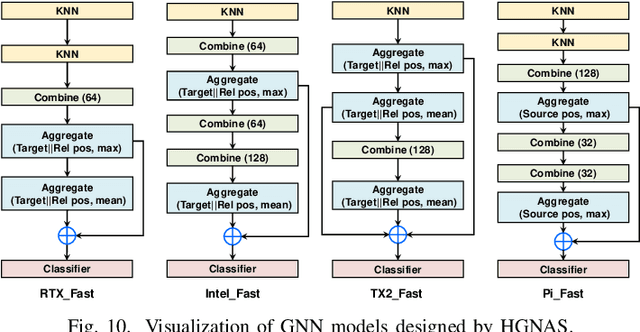

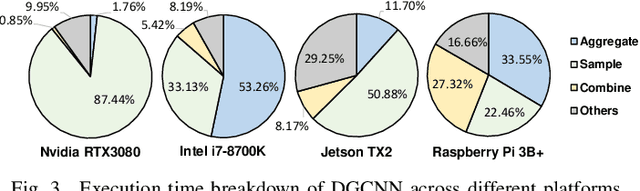
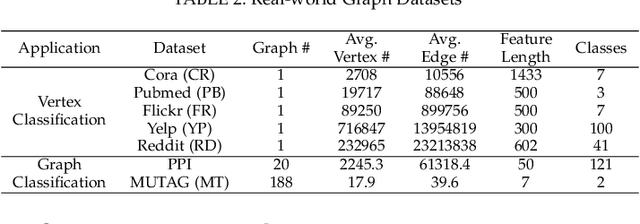
Graph neural networks (GNNs) have emerged as a popular strategy for handling non-Euclidean data due to their state-of-the-art performance. However, most of the current GNN model designs mainly focus on task accuracy, lacking in considering hardware resources limitation and real-time requirements of edge application scenarios. Comprehensive profiling of typical GNN models indicates that their execution characteristics are significantly affected across different computing platforms, which demands hardware awareness for efficient GNN designs. In this work, HGNAS is proposed as the first Hardware-aware Graph Neural Architecture Search framework targeting resource constraint edge devices. By decoupling the GNN paradigm, HGNAS constructs a fine-grained design space and leverages an efficient multi-stage search strategy to explore optimal architectures within a few GPU hours. Moreover, HGNAS achieves hardware awareness during the GNN architecture design by leveraging a hardware performance predictor, which could balance the GNN model accuracy and efficiency corresponding to the characteristics of targeted devices. Experimental results show that HGNAS can achieve about $10.6\times$ speedup and $88.2\%$ peak memory reduction with a negligible accuracy loss compared to DGCNN on various edge devices, including Nvidia RTX3080, Jetson TX2, Intel i7-8700K and Raspberry Pi 3B+.
Optimizing Memory Efficiency of Graph Neural Networks on Edge Computing Platforms
Apr 12, 2021



Graph neural networks (GNN) have achieved state-of-the-art performance on various industrial tasks. However, the poor efficiency of GNN inference and frequent Out-Of-Memory (OOM) problem limit the successful application of GNN on edge computing platforms. To tackle these problems, a feature decomposition approach is proposed for memory efficiency optimization of GNN inference. The proposed approach could achieve outstanding optimization on various GNN models, covering a wide range of datasets, which speeds up the inference by up to 3x. Furthermore, the proposed feature decomposition could significantly reduce the peak memory usage (up to 5x in memory efficiency improvement) and mitigate OOM problems during GNN inference.