 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSida Peng
MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
Apr 26, 2024
This paper aims to generate materials for 3D meshes from text descriptions. Unlike existing methods that synthesize texture maps, we propose to generate segment-wise procedural material graphs as the appearance representation, which supports high-quality rendering and provides substantial flexibility in editing. Instead of relying on extensive paired data, i.e., 3D meshes with material graphs and corresponding text descriptions, to train a material graph generative model, we propose to leverage the pre-trained 2D diffusion model as a bridge to connect the text and material graphs. Specifically, our approach decomposes a shape into a set of segments and designs a segment-controlled diffusion model to synthesize 2D images that are aligned with mesh parts. Based on generated images, we initialize parameters of material graphs and fine-tune them through the differentiable rendering module to produce materials in accordance with the textual description. Extensive experiments demonstrate the superior performance of our framework in photorealism, resolution, and editability over existing methods. Project page: https://zhanghe3z.github.io/MaPa/
TELA: Text to Layer-wise 3D Clothed Human Generation
Apr 25, 2024This paper addresses the task of 3D clothed human generation from textural descriptions. Previous works usually encode the human body and clothes as a holistic model and generate the whole model in a single-stage optimization, which makes them struggle for clothing editing and meanwhile lose fine-grained control over the whole generation process. To solve this, we propose a layer-wise clothed human representation combined with a progressive optimization strategy, which produces clothing-disentangled 3D human models while providing control capacity for the generation process. The basic idea is progressively generating a minimal-clothed human body and layer-wise clothes. During clothing generation, a novel stratified compositional rendering method is proposed to fuse multi-layer human models, and a new loss function is utilized to help decouple the clothing model from the human body. The proposed method achieves high-quality disentanglement, which thereby provides an effective way for 3D garment generation. Extensive experiments demonstrate that our approach achieves state-of-the-art 3D clothed human generation while also supporting cloth editing applications such as virtual try-on. Project page: http://jtdong.com/tela_layer/
IntrinsicAnything: Learning Diffusion Priors for Inverse Rendering Under Unknown Illumination
Apr 17, 2024This paper aims to recover object materials from posed images captured under an unknown static lighting condition. Recent methods solve this task by optimizing material parameters through differentiable physically based rendering. However, due to the coupling between object geometry, materials, and environment lighting, there is inherent ambiguity during the inverse rendering process, preventing previous methods from obtaining accurate results. To overcome this ill-posed problem, our key idea is to learn the material prior with a generative model for regularizing the optimization process. We observe that the general rendering equation can be split into diffuse and specular shading terms, and thus formulate the material prior as diffusion models of albedo and specular. Thanks to this design, our model can be trained using the existing abundant 3D object data, and naturally acts as a versatile tool to resolve the ambiguity when recovering material representations from RGB images. In addition, we develop a coarse-to-fine training strategy that leverages estimated materials to guide diffusion models to satisfy multi-view consistent constraints, leading to more stable and accurate results. Extensive experiments on real-world and synthetic datasets demonstrate that our approach achieves state-of-the-art performance on material recovery. The code will be available at https://zju3dv.github.io/IntrinsicAnything.
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Mar 21, 2024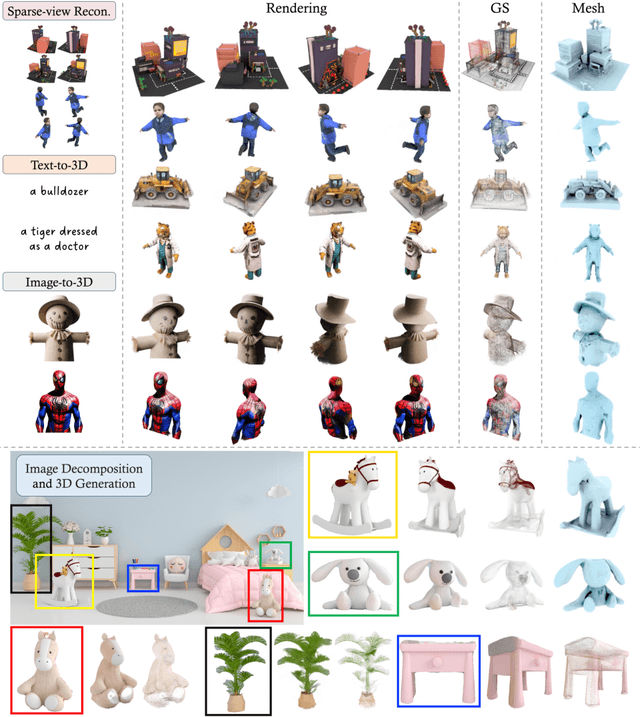
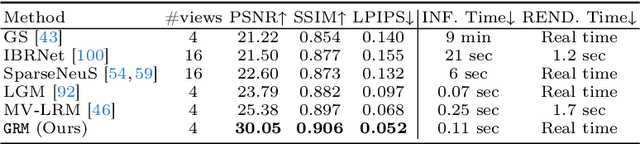

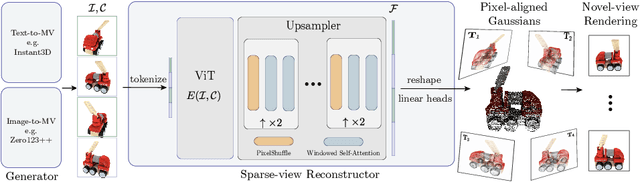
We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
GVGEN: Text-to-3D Generation with Volumetric Representation
Mar 19, 2024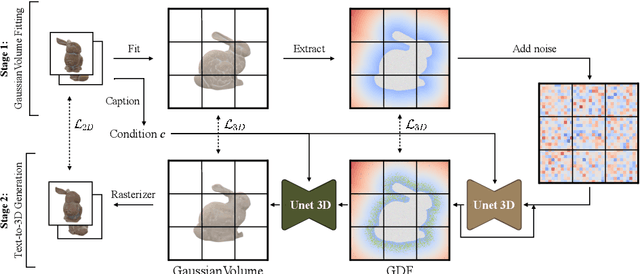
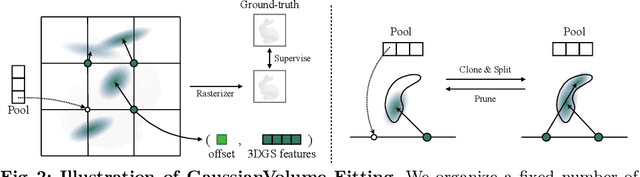


In recent years, 3D Gaussian splatting has emerged as a powerful technique for 3D reconstruction and generation, known for its fast and high-quality rendering capabilities. To address these shortcomings, this paper introduces a novel diffusion-based framework, GVGEN, designed to efficiently generate 3D Gaussian representations from text input. We propose two innovative techniques:(1) Structured Volumetric Representation. We first arrange disorganized 3D Gaussian points as a structured form GaussianVolume. This transformation allows the capture of intricate texture details within a volume composed of a fixed number of Gaussians. To better optimize the representation of these details, we propose a unique pruning and densifying method named the Candidate Pool Strategy, enhancing detail fidelity through selective optimization. (2) Coarse-to-fine Generation Pipeline. To simplify the generation of GaussianVolume and empower the model to generate instances with detailed 3D geometry, we propose a coarse-to-fine pipeline. It initially constructs a basic geometric structure, followed by the prediction of complete Gaussian attributes. Our framework, GVGEN, demonstrates superior performance in qualitative and quantitative assessments compared to existing 3D generation methods. Simultaneously, it maintains a fast generation speed ($\sim$7 seconds), effectively striking a balance between quality and efficiency.
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Mar 11, 2024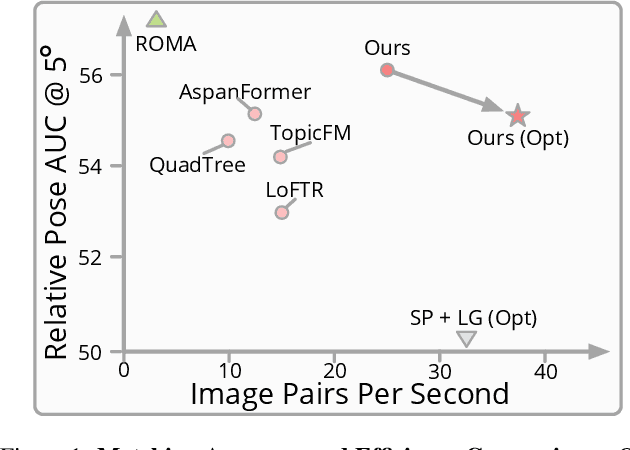
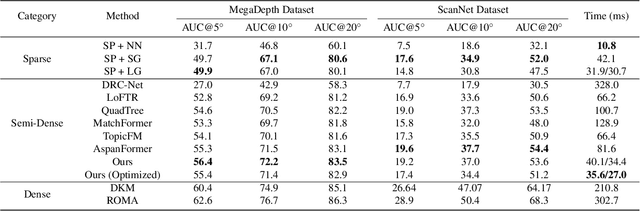
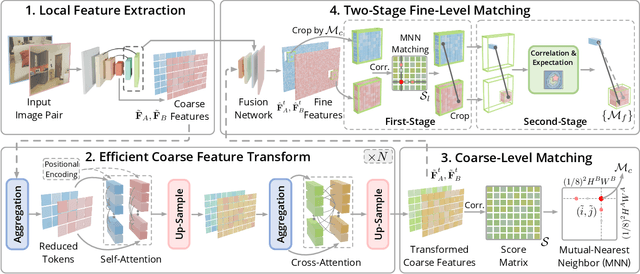
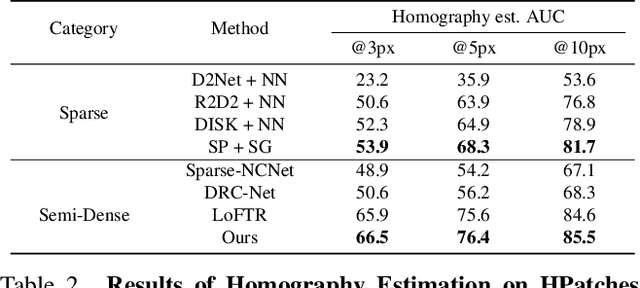
We present a novel method for efficiently producing semi-dense matches across images. Previous detector-free matcher LoFTR has shown remarkable matching capability in handling large-viewpoint change and texture-poor scenarios but suffers from low efficiency. We revisit its design choices and derive multiple improvements for both efficiency and accuracy. One key observation is that performing the transformer over the entire feature map is redundant due to shared local information, therefore we propose an aggregated attention mechanism with adaptive token selection for efficiency. Furthermore, we find spatial variance exists in LoFTR's fine correlation module, which is adverse to matching accuracy. A novel two-stage correlation layer is proposed to achieve accurate subpixel correspondences for accuracy improvement. Our efficiency optimized model is $\sim 2.5\times$ faster than LoFTR which can even surpass state-of-the-art efficient sparse matching pipeline SuperPoint + LightGlue. Moreover, extensive experiments show that our method can achieve higher accuracy compared with competitive semi-dense matchers, with considerable efficiency benefits. This opens up exciting prospects for large-scale or latency-sensitive applications such as image retrieval and 3D reconstruction. Project page: https://zju3dv.github.io/efficientloftr.
AI Revolution on Chat Bot: Evidence from a Randomized Controlled Experiment
Jan 19, 2024In recent years, generative AI has undergone major advancements, demonstrating significant promise in augmenting human productivity. Notably, large language models (LLM), with ChatGPT-4 as an example, have drawn considerable attention. Numerous articles have examined the impact of LLM-based tools on human productivity in lab settings and designed tasks or in observational studies. Despite recent advances, field experiments applying LLM-based tools in realistic settings are limited. This paper presents the findings of a field randomized controlled trial assessing the effectiveness of LLM-based tools in providing unmonitored support services for information retrieval.
Street Gaussians for Modeling Dynamic Urban Scenes
Jan 02, 2024This paper aims to tackle the problem of modeling dynamic urban street scenes from monocular videos. Recent methods extend NeRF by incorporating tracked vehicle poses to animate vehicles, enabling photo-realistic view synthesis of dynamic urban street scenes. However, significant limitations are their slow training and rendering speed, coupled with the critical need for high precision in tracked vehicle poses. We introduce Street Gaussians, a new explicit scene representation that tackles all these limitations. Specifically, the dynamic urban street is represented as a set of point clouds equipped with semantic logits and 3D Gaussians, each associated with either a foreground vehicle or the background. To model the dynamics of foreground object vehicles, each object point cloud is optimized with optimizable tracked poses, along with a dynamic spherical harmonics model for the dynamic appearance. The explicit representation allows easy composition of object vehicles and background, which in turn allows for scene editing operations and rendering at 133 FPS (1066$\times$1600 resolution) within half an hour of training. The proposed method is evaluated on multiple challenging benchmarks, including KITTI and Waymo Open datasets. Experiments show that the proposed method consistently outperforms state-of-the-art methods across all datasets. Furthermore, the proposed representation delivers performance on par with that achieved using precise ground-truth poses, despite relying only on poses from an off-the-shelf tracker. The code is available at https://zju3dv.github.io/street_gaussians/.
SAM-guided Graph Cut for 3D Instance Segmentation
Dec 25, 2023This paper addresses the challenge of 3D instance segmentation by simultaneously leveraging 3D geometric and multi-view image information. Many previous works have applied deep learning techniques to 3D point clouds for instance segmentation. However, these methods often failed to generalize to various types of scenes due to the scarcity and low-diversity of labeled 3D point cloud data. Some recent works have attempted to lift 2D instance segmentations to 3D within a bottom-up framework. The inconsistency in 2D instance segmentations among views can substantially degrade the performance of 3D segmentation. In this work, we introduce a novel 3D-to-2D query framework to effectively exploit 2D segmentation models for 3D instance segmentation. Specifically, we pre-segment the scene into several superpoints in 3D, formulating the task into a graph cut problem. The superpoint graph is constructed based on 2D segmentation models, where node features are obtained from multi-view image features and edge weights are computed based on multi-view segmentation results, enabling the better generalization ability. To process the graph, we train a graph neural network using pseudo 3D labels from 2D segmentation models. Experimental results on the ScanNet, ScanNet++ and KITTI-360 datasets demonstrate that our method achieves robust segmentation performance and can generalize across different types of scenes. Our project page is available at https://zju3dv.github.io/sam_graph.