 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQianqian Wang
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024
Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
Fuzzy K-Means Clustering without Cluster Centroids
Apr 07, 2024Fuzzy K-Means clustering is a critical technique in unsupervised data analysis. However, the performance of popular Fuzzy K-Means algorithms is sensitive to the selection of initial cluster centroids and is also affected by noise when updating mean cluster centroids. To address these challenges, this paper proposes a novel Fuzzy K-Means clustering algorithm that entirely eliminates the reliance on cluster centroids, obtaining membership matrices solely through distance matrix computation. This innovation enhances flexibility in distance measurement between sample points, thus improving the algorithm's performance and robustness. The paper also establishes theoretical connections between the proposed model and popular Fuzzy K-Means clustering techniques. Experimental results on several real datasets demonstrate the effectiveness of the algorithm.
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
Interpretable Multi-View Clustering Based on Anchor Graph Tensor Factorization
Apr 01, 2024The clustering method based on the anchor graph has gained significant attention due to its exceptional clustering performance and ability to process large-scale data. One common approach is to learn bipartite graphs with K-connected components, helping avoid the need for post-processing. However, this method has strict parameter requirements and may not always get K-connected components. To address this issue, an alternative approach is to directly obtain the cluster label matrix by performing non-negative matrix factorization (NMF) on the anchor graph. Nevertheless, existing multi-view clustering methods based on anchor graph factorization lack adequate cluster interpretability for the decomposed matrix and often overlook the inter-view information. We address this limitation by using non-negative tensor factorization to decompose an anchor graph tensor that combines anchor graphs from multiple views. This approach allows us to consider inter-view information comprehensively. The decomposed tensors, namely the sample indicator tensor and the anchor indicator tensor, enhance the interpretability of the factorization. Extensive experiments validate the effectiveness of this method.
Label Learning Method Based on Tensor Projection
Feb 26, 2024Multi-view clustering method based on anchor graph has been widely concerned due to its high efficiency and effectiveness. In order to avoid post-processing, most of the existing anchor graph-based methods learn bipartite graphs with connected components. However, such methods have high requirements on parameters, and in some cases it may not be possible to obtain bipartite graphs with clear connected components. To end this, we propose a label learning method based on tensor projection (LLMTP). Specifically, we project anchor graph into the label space through an orthogonal projection matrix to obtain cluster labels directly. Considering that the spatial structure information of multi-view data may be ignored to a certain extent when projected in different views separately, we extend the matrix projection transformation to tensor projection, so that the spatial structure information between views can be fully utilized. In addition, we introduce the tensor Schatten $p$-norm regularization to make the clustering label matrices of different views as consistent as possible. Extensive experiments have proved the effectiveness of the proposed method.
Doppelgangers: Learning to Disambiguate Images of Similar Structures
Sep 05, 2023
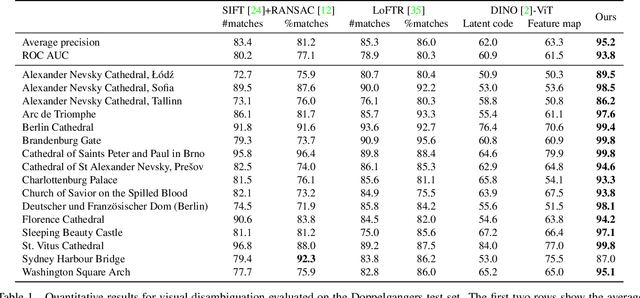
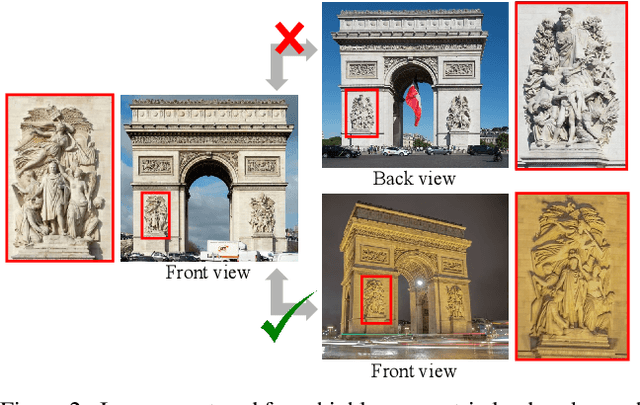
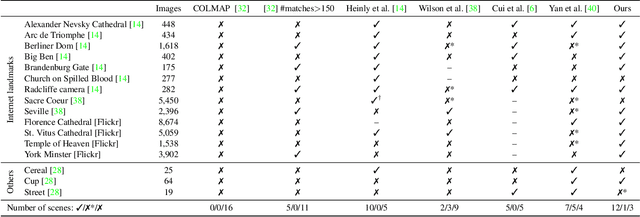
We consider the visual disambiguation task of determining whether a pair of visually similar images depict the same or distinct 3D surfaces (e.g., the same or opposite sides of a symmetric building). Illusory image matches, where two images observe distinct but visually similar 3D surfaces, can be challenging for humans to differentiate, and can also lead 3D reconstruction algorithms to produce erroneous results. We propose a learning-based approach to visual disambiguation, formulating it as a binary classification task on image pairs. To that end, we introduce a new dataset for this problem, Doppelgangers, which includes image pairs of similar structures with ground truth labels. We also design a network architecture that takes the spatial distribution of local keypoints and matches as input, allowing for better reasoning about both local and global cues. Our evaluation shows that our method can distinguish illusory matches in difficult cases, and can be integrated into SfM pipelines to produce correct, disambiguated 3D reconstructions. See our project page for our code, datasets, and more results: http://doppelgangers-3d.github.io/.
Source-Free Collaborative Domain Adaptation via Multi-Perspective Feature Enrichment for Functional MRI Analysis
Aug 24, 2023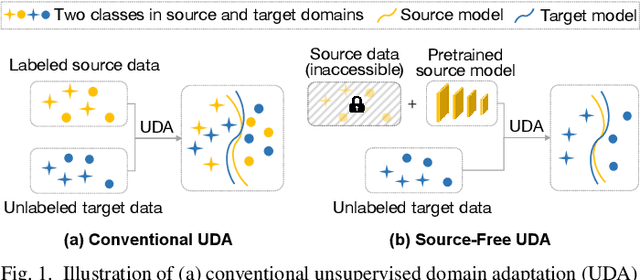
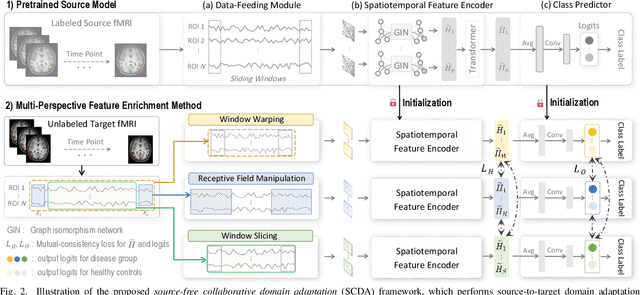
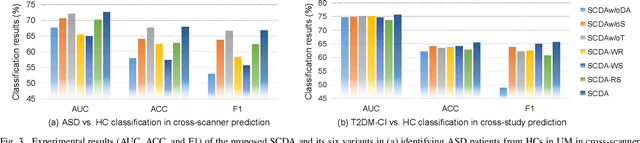
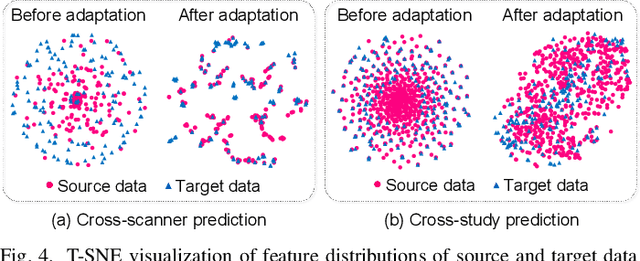
Resting-state functional MRI (rs-fMRI) is increasingly employed in multi-site research to aid neurological disorder analysis. Existing studies usually suffer from significant cross-site/domain data heterogeneity caused by site effects such as differences in scanners/protocols. Many methods have been proposed to reduce fMRI heterogeneity between source and target domains, heavily relying on the availability of source data. But acquiring source data is challenging due to privacy concerns and/or data storage burdens in multi-site studies. To this end, we design a source-free collaborative domain adaptation (SCDA) framework for fMRI analysis, where only a pretrained source model and unlabeled target data are accessible. Specifically, a multi-perspective feature enrichment method (MFE) is developed for target fMRI analysis, consisting of multiple collaborative branches to dynamically capture fMRI features of unlabeled target data from multiple views. Each branch has a data-feeding module, a spatiotemporal feature encoder, and a class predictor. A mutual-consistency constraint is designed to encourage pair-wise consistency of latent features of the same input generated from these branches for robust representation learning. To facilitate efficient cross-domain knowledge transfer without source data, we initialize MFE using parameters of a pretrained source model. We also introduce an unsupervised pretraining strategy using 3,806 unlabeled fMRIs from three large-scale auxiliary databases, aiming to obtain a general feature encoder. Experimental results on three public datasets and one private dataset demonstrate the efficacy of our method in cross-scanner and cross-study prediction tasks. The model pretrained on large-scale rs-fMRI data has been released to the public.
Preserving Specificity in Federated Graph Learning for fMRI-based Neurological Disorder Identification
Aug 20, 2023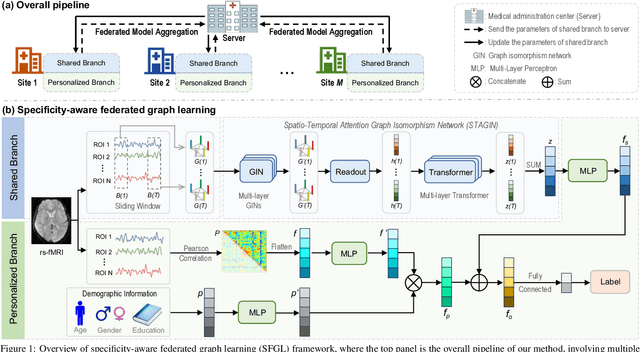
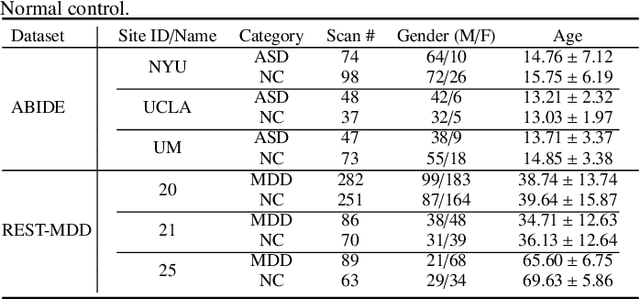
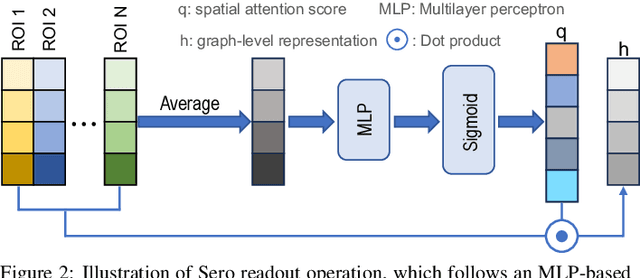

Resting-state functional magnetic resonance imaging (rs-fMRI) offers a non-invasive approach to examining abnormal brain connectivity associated with brain disorders. Graph neural network (GNN) gains popularity in fMRI representation learning and brain disorder analysis with powerful graph representation capabilities. Training a general GNN often necessitates a large-scale dataset from multiple imaging centers/sites, but centralizing multi-site data generally faces inherent challenges related to data privacy, security, and storage burden. Federated Learning (FL) enables collaborative model training without centralized multi-site fMRI data. Unfortunately, previous FL approaches for fMRI analysis often ignore site-specificity, including demographic factors such as age, gender, and education level. To this end, we propose a specificity-aware federated graph learning (SFGL) framework for rs-fMRI analysis and automated brain disorder identification, with a server and multiple clients/sites for federated model aggregation and prediction. At each client, our model consists of a shared and a personalized branch, where parameters of the shared branch are sent to the server while those of the personalized branch remain local. This can facilitate knowledge sharing among sites and also helps preserve site specificity. In the shared branch, we employ a spatio-temporal attention graph isomorphism network to learn dynamic fMRI representations. In the personalized branch, we integrate vectorized demographic information (i.e., age, gender, and education years) and functional connectivity networks to preserve site-specific characteristics. Representations generated by the two branches are then fused for classification. Experimental results on two fMRI datasets with a total of 1,218 subjects suggest that SFGL outperforms several state-of-the-art approaches.
Leveraging Brain Modularity Prior for Interpretable Representation Learning of fMRI
Jun 24, 2023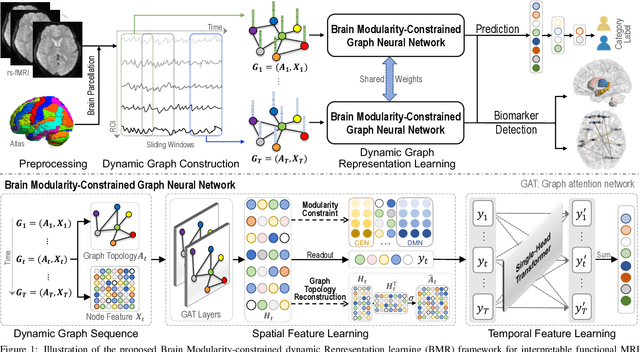
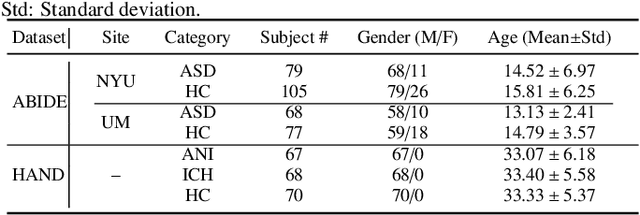
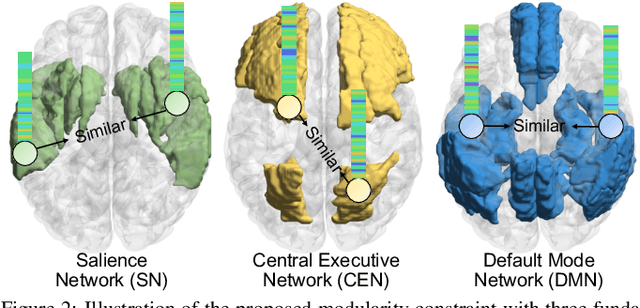
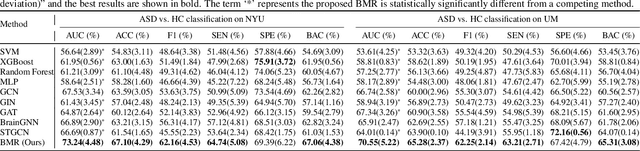
Resting-state functional magnetic resonance imaging (rs-fMRI) can reflect spontaneous neural activities in brain and is widely used for brain disorder analysis.Previous studies propose to extract fMRI representations through diverse machine/deep learning methods for subsequent analysis. But the learned features typically lack biological interpretability, which limits their clinical utility. From the view of graph theory, the brain exhibits a remarkable modular structure in spontaneous brain functional networks, with each module comprised of functionally interconnected brain regions-of-interest (ROIs). However, most existing learning-based methods for fMRI analysis fail to adequately utilize such brain modularity prior. In this paper, we propose a Brain Modularity-constrained dynamic Representation learning (BMR) framework for interpretable fMRI analysis, consisting of three major components: (1) dynamic graph construction, (2) dynamic graph learning via a novel modularity-constrained graph neural network(MGNN), (3) prediction and biomarker detection for interpretable fMRI analysis. Especially, three core neurocognitive modules (i.e., salience network, central executive network, and default mode network) are explicitly incorporated into the MGNN, encouraging the nodes/ROIs within the same module to share similar representations. To further enhance discriminative ability of learned features, we also encourage the MGNN to preserve the network topology of input graphs via a graph topology reconstruction constraint. Experimental results on 534 subjects with rs-fMRI scans from two datasets validate the effectiveness of the proposed method. The identified discriminative brain ROIs and functional connectivities can be regarded as potential fMRI biomarkers to aid in clinical diagnosis.
Neural Scene Chronology
Jun 13, 2023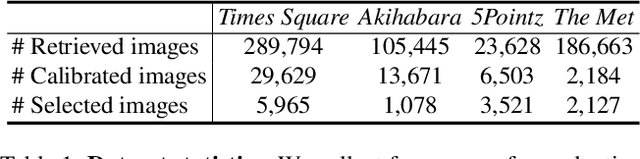
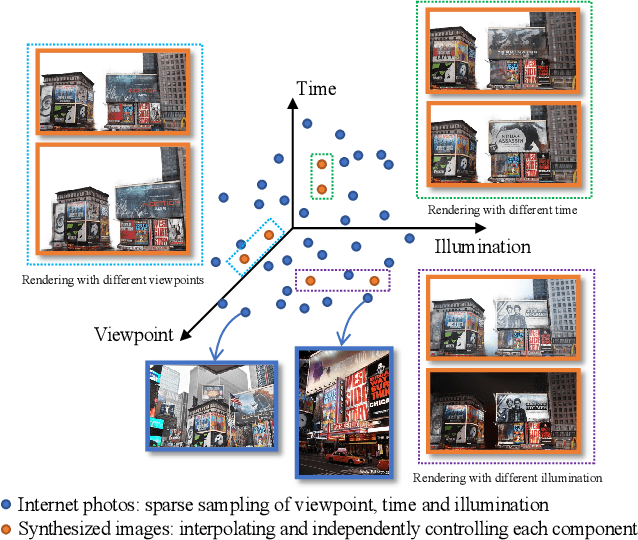
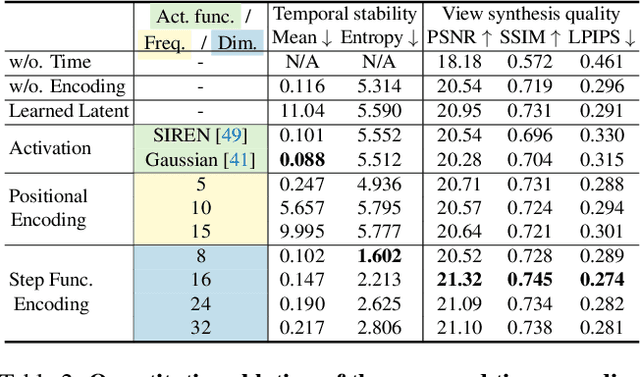
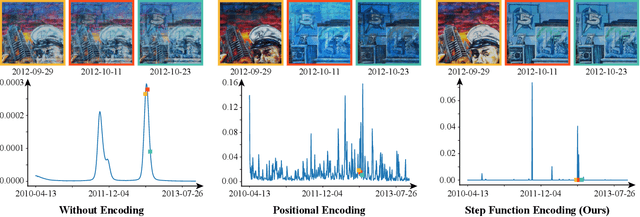
In this work, we aim to reconstruct a time-varying 3D model, capable of rendering photo-realistic renderings with independent control of viewpoint, illumination, and time, from Internet photos of large-scale landmarks. The core challenges are twofold. First, different types of temporal changes, such as illumination and changes to the underlying scene itself (such as replacing one graffiti artwork with another) are entangled together in the imagery. Second, scene-level temporal changes are often discrete and sporadic over time, rather than continuous. To tackle these problems, we propose a new scene representation equipped with a novel temporal step function encoding method that can model discrete scene-level content changes as piece-wise constant functions over time. Specifically, we represent the scene as a space-time radiance field with a per-image illumination embedding, where temporally-varying scene changes are encoded using a set of learned step functions. To facilitate our task of chronology reconstruction from Internet imagery, we also collect a new dataset of four scenes that exhibit various changes over time. We demonstrate that our method exhibits state-of-the-art view synthesis results on this dataset, while achieving independent control of viewpoint, time, and illumination.