 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHe Zhu
HILL: Hierarchy-aware Information Lossless Contrastive Learning for Hierarchical Text Classification
Mar 26, 2024
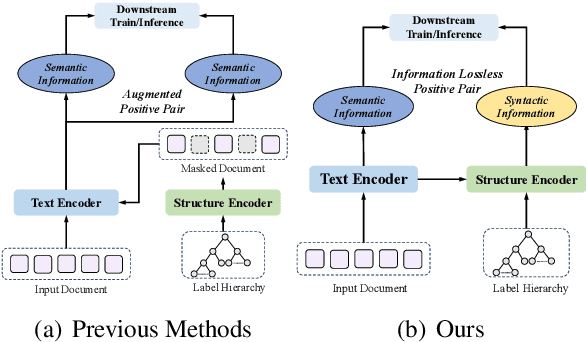

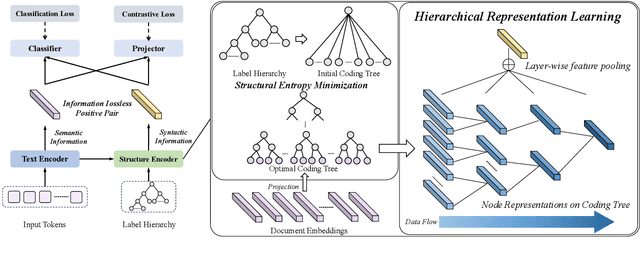
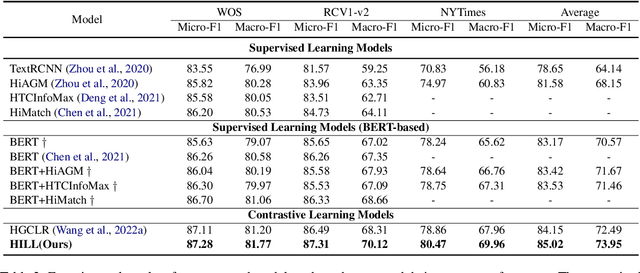
Existing self-supervised methods in natural language processing (NLP), especially hierarchical text classification (HTC), mainly focus on self-supervised contrastive learning, extremely relying on human-designed augmentation rules to generate contrastive samples, which can potentially corrupt or distort the original information. In this paper, we tend to investigate the feasibility of a contrastive learning scheme in which the semantic and syntactic information inherent in the input sample is adequately reserved in the contrastive samples and fused during the learning process. Specifically, we propose an information lossless contrastive learning strategy for HTC, namely \textbf{H}ierarchy-aware \textbf{I}nformation \textbf{L}ossless contrastive \textbf{L}earning (HILL), which consists of a text encoder representing the input document, and a structure encoder directly generating the positive sample. The structure encoder takes the document embedding as input, extracts the essential syntactic information inherent in the label hierarchy with the principle of structural entropy minimization, and injects the syntactic information into the text representation via hierarchical representation learning. Experiments on three common datasets are conducted to verify the superiority of HILL.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Prompt-based Personalized Federated Learning for Medical Visual Question Answering
Feb 15, 2024We present a novel prompt-based personalized federated learning (pFL) method to address data heterogeneity and privacy concerns in traditional medical visual question answering (VQA) methods. Specifically, we regard medical datasets from different organs as clients and use pFL to train personalized transformer-based VQA models for each client. To address the high computational complexity of client-to-client communication in previous pFL methods, we propose a succinct information sharing system by introducing prompts that are small learnable parameters. In addition, the proposed method introduces a reliability parameter to prevent the negative effects of low performance and irrelevant clients. Finally, extensive evaluations on various heterogeneous medical datasets attest to the effectiveness of our proposed method.
Bidirectional Generative Pre-training for Improving Time Series Representation Learning
Feb 14, 2024Learning time-series representations for discriminative tasks has been a long-standing challenge. Current pre-training methods are limited in either unidirectional next-token prediction or randomly masked token prediction. We propose a novel architecture called Bidirectional Timely Generative Pre-trained Transformer (BiTimelyGPT), which pre-trains on time-series data by both next-token and previous-token predictions in alternating transformer layers. This pre-training task preserves original distribution and data shapes of the time-series. Additionally, the full-rank forward and backward attention matrices exhibit more expressive representation capabilities. Using biosignal data, BiTimelyGPT demonstrates superior performance in predicting neurological functionality, disease diagnosis, and physiological signs. By visualizing the attention heatmap, we observe that the pre-trained BiTimelyGPT can identify discriminative segments from time-series sequences, even more so after fine-tuning on the task.
Formal-LLM: Integrating Formal Language and Natural Language for Controllable LLM-based Agents
Feb 04, 2024Recent advancements on Large Language Models (LLMs) enable AI Agents to automatically generate and execute multi-step plans to solve complex tasks. However, since LLM's content generation process is hardly controllable, current LLM-based agents frequently generate invalid or non-executable plans, which jeopardizes the performance of the generated plans and corrupts users' trust in LLM-based agents. In response, this paper proposes a novel ``Formal-LLM'' framework for LLM-based agents by integrating the expressiveness of natural language and the precision of formal language. Specifically, the framework allows human users to express their requirements or constraints for the planning process as an automaton. A stack-based LLM plan generation process is then conducted under the supervision of the automaton to ensure that the generated plan satisfies the constraints, making the planning process controllable. We conduct experiments on both benchmark tasks and practical real-life tasks, and our framework achieves over 50% overall performance increase, which validates the feasibility and effectiveness of employing Formal-LLM to guide the plan generation of agents, preventing the agents from generating invalid and unsuccessful plans. Further, more controllable LLM-based agents can facilitate the broader utilization of LLM in application scenarios where high validity of planning is essential. The work is open-sourced at https://github.com/agiresearch/Formal-LLM.
SAM-guided Graph Cut for 3D Instance Segmentation
Dec 25, 2023This paper addresses the challenge of 3D instance segmentation by simultaneously leveraging 3D geometric and multi-view image information. Many previous works have applied deep learning techniques to 3D point clouds for instance segmentation. However, these methods often failed to generalize to various types of scenes due to the scarcity and low-diversity of labeled 3D point cloud data. Some recent works have attempted to lift 2D instance segmentations to 3D within a bottom-up framework. The inconsistency in 2D instance segmentations among views can substantially degrade the performance of 3D segmentation. In this work, we introduce a novel 3D-to-2D query framework to effectively exploit 2D segmentation models for 3D instance segmentation. Specifically, we pre-segment the scene into several superpoints in 3D, formulating the task into a graph cut problem. The superpoint graph is constructed based on 2D segmentation models, where node features are obtained from multi-view image features and edge weights are computed based on multi-view segmentation results, enabling the better generalization ability. To process the graph, we train a graph neural network using pseudo 3D labels from 2D segmentation models. Experimental results on the ScanNet, ScanNet++ and KITTI-360 datasets demonstrate that our method achieves robust segmentation performance and can generalize across different types of scenes. Our project page is available at https://zju3dv.github.io/sam_graph.
Attention Schema in Neural Agents
Jun 01, 2023
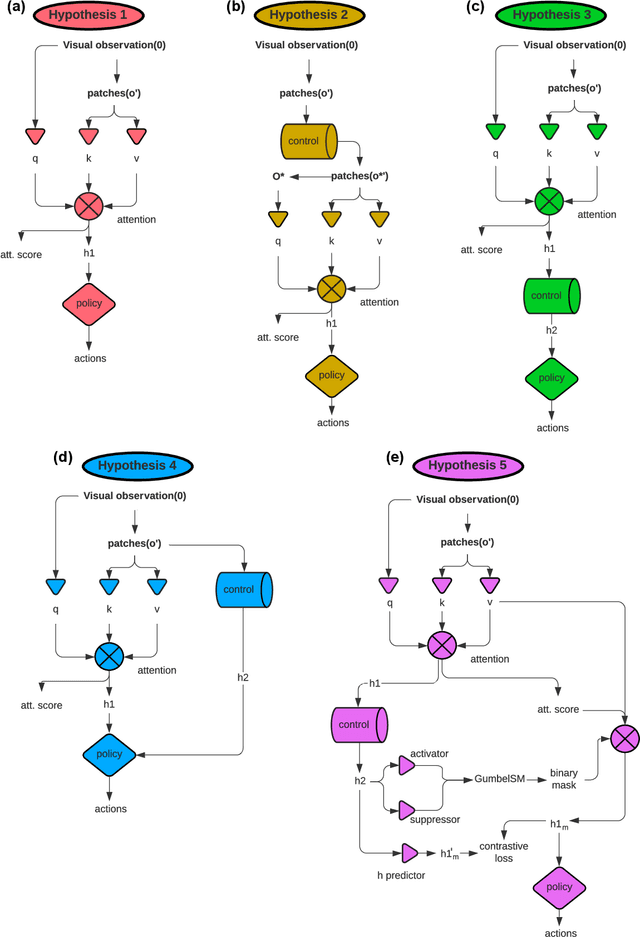
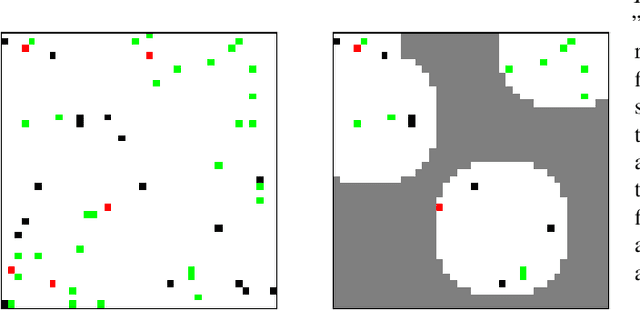
Attention has become a common ingredient in deep learning architectures. It adds a dynamical selection of information on top of the static selection of information supported by weights. In the same way, we can imagine a higher-order informational filter built on top of attention: an Attention Schema (AS), namely, a descriptive and predictive model of attention. In cognitive neuroscience, Attention Schema Theory (AST) supports this idea of distinguishing attention from AS. A strong prediction of this theory is that an agent can use its own AS to also infer the states of other agents' attention and consequently enhance coordination with other agents. As such, multi-agent reinforcement learning would be an ideal setting to experimentally test the validity of AST. We explore different ways in which attention and AS interact with each other. Our preliminary results indicate that agents that implement the AS as a recurrent internal control achieve the best performance. In general, these exploratory experiments suggest that equipping artificial agents with a model of attention can enhance their social intelligence.
HiTIN: Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification
May 24, 2023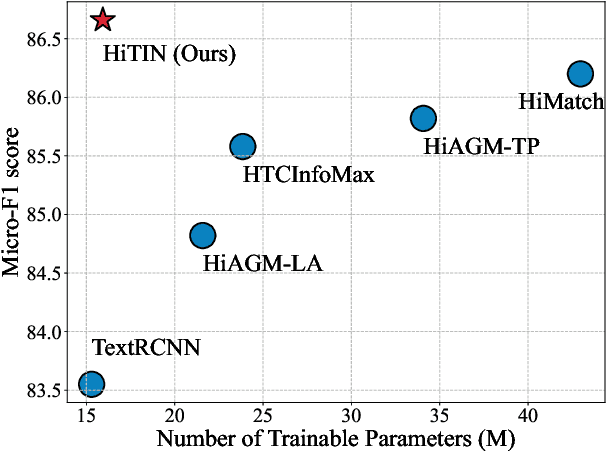

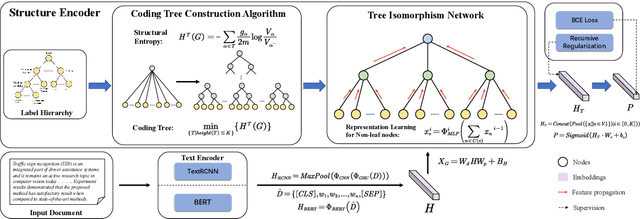

Hierarchical text classification (HTC) is a challenging subtask of multi-label classification as the labels form a complex hierarchical structure. Existing dual-encoder methods in HTC achieve weak performance gains with huge memory overheads and their structure encoders heavily rely on domain knowledge. Under such observation, we tend to investigate the feasibility of a memory-friendly model with strong generalization capability that could boost the performance of HTC without prior statistics or label semantics. In this paper, we propose Hierarchy-aware Tree Isomorphism Network (HiTIN) to enhance the text representations with only syntactic information of the label hierarchy. Specifically, we convert the label hierarchy into an unweighted tree structure, termed coding tree, with the guidance of structural entropy. Then we design a structure encoder to incorporate hierarchy-aware information in the coding tree into text representations. Besides the text encoder, HiTIN only contains a few multi-layer perceptions and linear transformations, which greatly saves memory. We conduct experiments on three commonly used datasets and the results demonstrate that HiTIN could achieve better test performance and less memory consumption than state-of-the-art (SOTA) methods.
Adaptive Data Augmentation for Contrastive Learning
Apr 19, 2023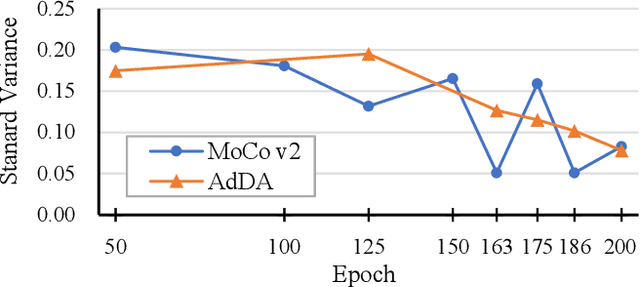
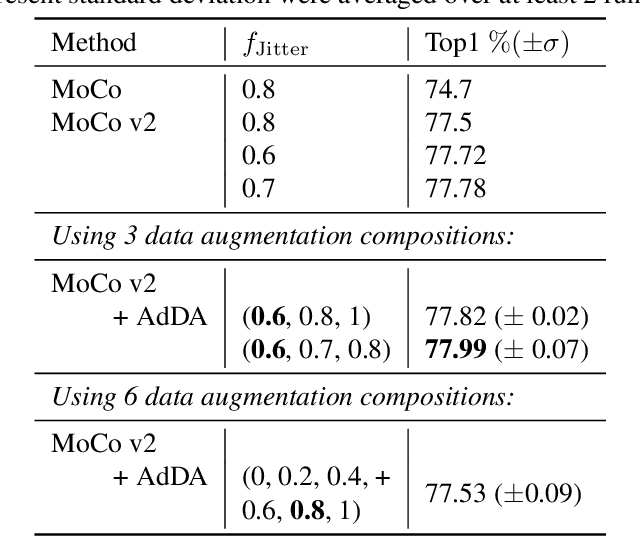
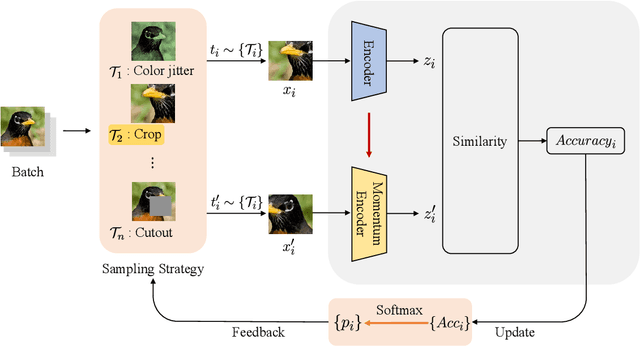
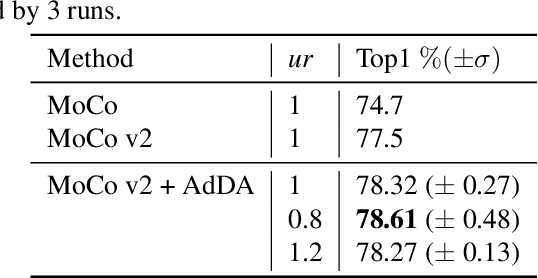
In computer vision, contrastive learning is the most advanced unsupervised learning framework. Yet most previous methods simply apply fixed composition of data augmentations to improve data efficiency, which ignores the changes in their optimal settings over training. Thus, the pre-determined parameters of augmentation operations cannot always fit well with an evolving network during the whole training period, which degrades the quality of the learned representations. In this work, we propose AdDA, which implements a closed-loop feedback structure to a generic contrastive learning network. AdDA works by allowing the network to adaptively adjust the augmentation compositions according to the real-time feedback. This online adjustment helps maintain the dynamic optimal composition and enables the network to acquire more generalizable representations with minimal computational overhead. AdDA achieves competitive results under the common linear protocol on ImageNet-100 classification (+1.11% on MoCo v2).
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023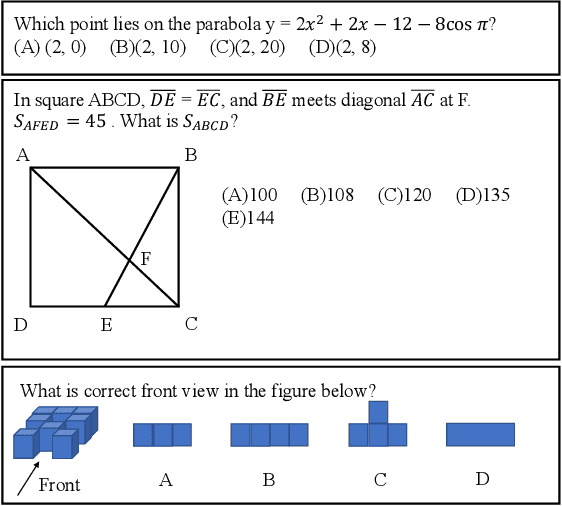

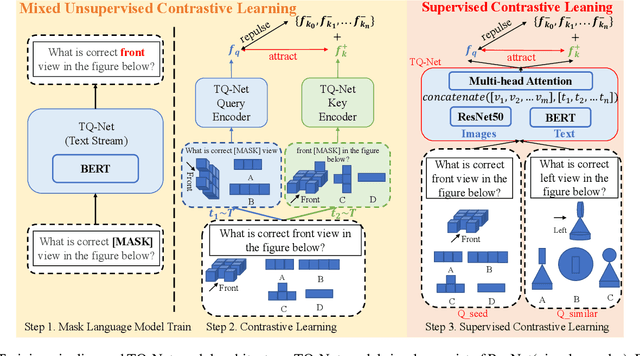
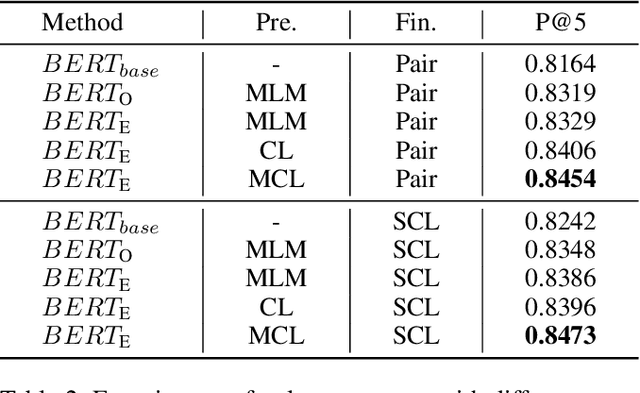
Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.