 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXing Liu
An Integrating Comprehensive Trajectory Prediction with Risk Potential Field Method for Autonomous Driving
Apr 01, 2024
Due to the uncertainty of traffic participants' intentions, generating safe but not overly cautious behavior in interactive driving scenarios remains a formidable challenge for autonomous driving. In this paper, we address this issue by combining a deep learning-based trajectory prediction model with risk potential field-based motion planning. In order to comprehensively predict the possible future trajectories of other vehicles, we propose a target-region based trajectory prediction model(TRTP) which considers every region a vehicle may arrive in the future. After that, we construct a risk potential field at each future time step based on the prediction results of TRTP, and integrate risk value to the objective function of Model Predictive Contouring Control(MPCC). This enables the uncertainty of other vehicles to be taken into account during the planning process. Balancing between risk and progress along the reference path can achieve both driving safety and efficiency at the same time. We also demonstrate the security and effectiveness performance of our method in the CARLA simulator.
Understanding the Functional Roles of Modelling Components in Spiking Neural Networks
Mar 25, 2024Spiking neural networks (SNNs), inspired by the neural circuits of the brain, are promising in achieving high computational efficiency with biological fidelity. Nevertheless, it is quite difficult to optimize SNNs because the functional roles of their modelling components remain unclear. By designing and evaluating several variants of the classic model, we systematically investigate the functional roles of key modelling components, leakage, reset, and recurrence, in leaky integrate-and-fire (LIF) based SNNs. Through extensive experiments, we demonstrate how these components influence the accuracy, generalization, and robustness of SNNs. Specifically, we find that the leakage plays a crucial role in balancing memory retention and robustness, the reset mechanism is essential for uninterrupted temporal processing and computational efficiency, and the recurrence enriches the capability to model complex dynamics at a cost of robustness degradation. With these interesting observations, we provide optimization suggestions for enhancing the performance of SNNs in different scenarios. This work deepens the understanding of how SNNs work, which offers valuable guidance for the development of more effective and robust neuromorphic models.
TexRO: Generating Delicate Textures of 3D Models by Recursive Optimization
Mar 22, 2024This paper presents TexRO, a novel method for generating delicate textures of a known 3D mesh by optimizing its UV texture. The key contributions are two-fold. We propose an optimal viewpoint selection strategy, that finds the most miniature set of viewpoints covering all the faces of a mesh. Our viewpoint selection strategy guarantees the completeness of a generated result. We propose a recursive optimization pipeline that optimizes a UV texture at increasing resolutions, with an adaptive denoising method that re-uses existing textures for new texture generation. Through extensive experimentation, we demonstrate the superior performance of TexRO in terms of texture quality, detail preservation, visual consistency, and, notably runtime speed, outperforming other current methods. The broad applicability of TexRO is further confirmed through its successful use on diverse 3D models.
LEO- and RIS-Empowered User Tracking: A Riemannian Manifold Approach
Mar 09, 2024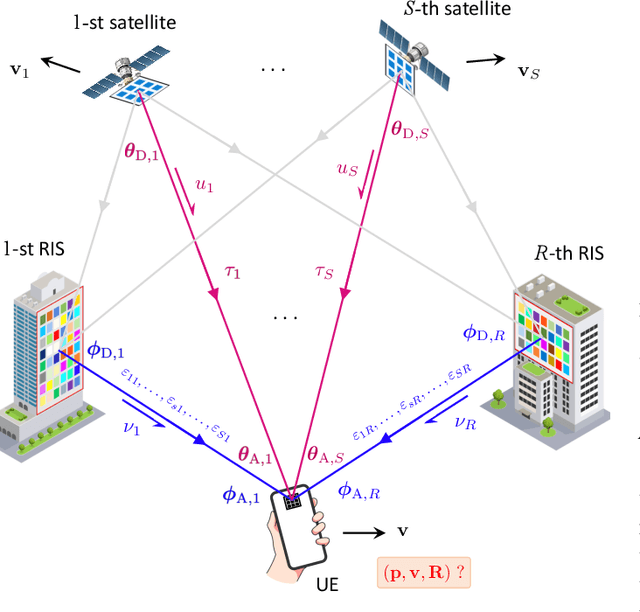
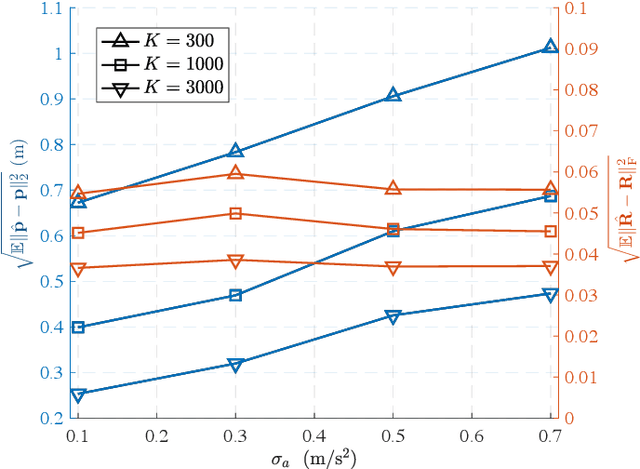
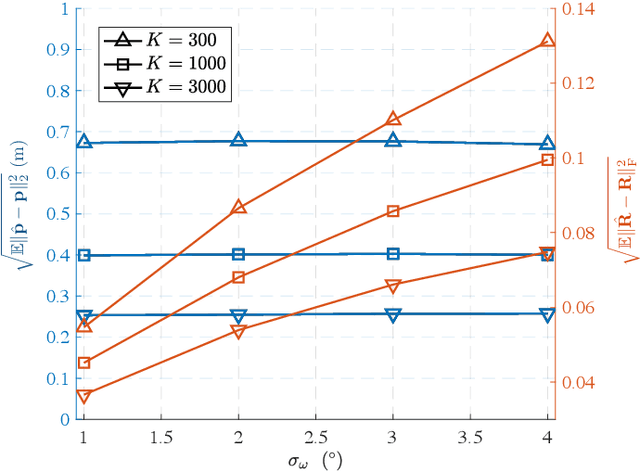
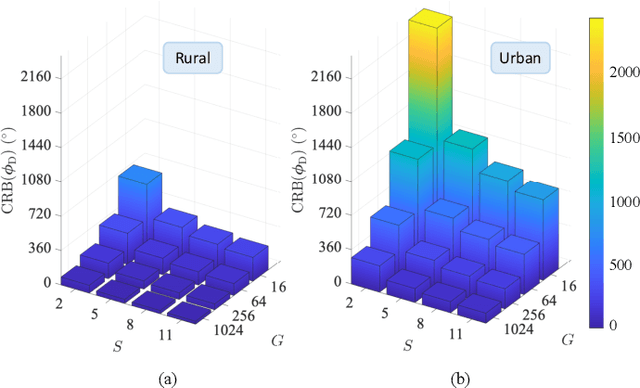
Low Earth orbit (LEO) satellites and reconfigurable intelligent surfaces (RISs) have recently drawn significant attention as two transformative technologies, and the synergy between them emerges as a promising paradigm for providing cross-environment communication and positioning services. This paper investigates an integrated terrestrial and non-terrestrial wireless network that leverages LEO satellites and RISs to achieve simultaneous tracking of the 3D position, 3D velocity, and 3D orientation of user equipment (UE). To address inherent challenges including nonlinear observation function, constrained UE state, and unknown observation statistics, we develop a Riemannian manifold-based unscented Kalman filter (UKF) method. This method propagates statistics over nonlinear functions using generated sigma points and maintains state constraints through projection onto the defined manifold space. Additionally, by employing Fisher information matrices (FIMs) of the sigma points, a belief assignment principle is proposed to approximate the unknown observation covariance matrix, thereby ensuring accurate measurement updates in the UKF procedure. Numerical results demonstrate a substantial enhancement in tracking accuracy facilitated by RIS integration, despite urban signal reception challenges from LEO satellites. In addition, extensive simulations underscore the superior performance of the proposed tracking method and FIM-based belief assignment over the adopted benchmarks. Furthermore, the robustness of the proposed UKF is verified across various uncertainty levels.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations
Feb 27, 2024Large-scale recommendation systems are characterized by their reliance on high cardinality, heterogeneous features and the need to handle tens of billions of user actions on a daily basis. Despite being trained on huge volume of data with thousands of features, most Deep Learning Recommendation Models (DLRMs) in industry fail to scale with compute. Inspired by success achieved by Transformers in language and vision domains, we revisit fundamental design choices in recommendation systems. We reformulate recommendation problems as sequential transduction tasks within a generative modeling framework (``Generative Recommenders''), and propose a new architecture, HSTU, designed for high cardinality, non-stationary streaming recommendation data. HSTU outperforms baselines over synthetic and public datasets by up to 65.8\% in NDCG, and is 5.3x to 15.2x faster than FlashAttention2-based Transformers on 8192 length sequences. HSTU-based Generative Recommenders, with 1.5 trillion parameters, improve metrics in online A/B tests by 12.4\% and have been deployed on multiple surfaces of a large internet platform with billions of users. More importantly, the model quality of Generative Recommenders empirically scales as a power-law of training compute across three orders of magnitude, up to GPT-3/LLaMa-2 scale, which reduces carbon footprint needed for future model developments, and further paves the way for the first foundational models in recommendations.
GEA: Reconstructing Expressive 3D Gaussian Avatar from Monocular Video
Feb 26, 2024This paper presents GEA, a novel method for creating expressive 3D avatars with high-fidelity reconstructions of body and hands based on 3D Gaussians. The key contributions are twofold. First, we design a two-stage pose estimation method to obtain an accurate SMPL-X pose from input images, providing a correct mapping between the pixels of a training image and the SMPL-X model. It uses an attention-aware network and an optimization scheme to align the normal and silhouette between the estimated SMPL-X body and the real body in the image. Second, we propose an iterative re-initialization strategy to handle unbalanced aggregation and initialization bias faced by Gaussian representation. This strategy iteratively redistributes the avatar's Gaussian points, making it evenly distributed near the human body surface by applying meshing, resampling and re-Gaussian operations. As a result, higher-quality rendering can be achieved. Extensive experimental analyses validate the effectiveness of the proposed model, demonstrating that it achieves state-of-the-art performance in photorealistic novel view synthesis while offering fine-grained control over the human body and hand pose. Project page: https://3d-aigc.github.io/GEA/.
LEO Satellite and RIS: Two Keys to Seamless Indoor and Outdoor Localization
Dec 28, 2023The contemporary landscape of wireless technology underscores the critical role of precise localization services. Traditional global navigation satellite systems (GNSS)-based solutions, however, fall short when it comes to indoor environments, and existing indoor localization techniques such as electromagnetic fingerprinting methods face challenges of high implementation costs and limited coverage. This article explores an innovative solution that seamlessly blends low Earth orbit (LEO) satellites with reconfigurable intelligent surfaces (RISs), unlocking its potential for realizing uninterrupted indoor and outdoor localization with global coverage. By leveraging the strong signal reception of the LEO satellite signals and capitalizing on the radio environment-reshaping capability of RISs, the integration of these two technologies presents a vision of a future where localization services transcend existing constraints. After a comprehensive review of the distinctive attributes of LEO satellites and RISs, we evaluate the localization error bounds for the proposed collaborative system, showcasing their promising performance on simultaneous indoor and outdoor localization. To conclude, we engage in a discussion on open problems and future research directions for LEO satellite and RIS-enabled localization.
GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
Dec 08, 2023This paper presents GIR, a 3D Gaussian Inverse Rendering method for relightable scene factorization. Compared to existing methods leveraging discrete meshes or neural implicit fields for inverse rendering, our method utilizes 3D Gaussians to estimate the material properties, illumination, and geometry of an object from multi-view images. Our study is motivated by the evidence showing that 3D Gaussian is a more promising backbone than neural fields in terms of performance, versatility, and efficiency. In this paper, we aim to answer the question: ``How can 3D Gaussian be applied to improve the performance of inverse rendering?'' To address the complexity of estimating normals based on discrete and often in-homogeneous distributed 3D Gaussian representations, we proposed an efficient self-regularization method that facilitates the modeling of surface normals without the need for additional supervision. To reconstruct indirect illumination, we propose an approach that simulates ray tracing. Extensive experiments demonstrate our proposed GIR's superior performance over existing methods across multiple tasks on a variety of widely used datasets in inverse rendering. This substantiates its efficacy and broad applicability, highlighting its potential as an influential tool in relighting and reconstruction. Project page: https://3dgir.github.io
Dynamic Analysis Method for Hidden Dangers in Substation Based on Knowledge Graph
Nov 22, 2023To address the challenge of identifying and understanding hidden dangers in substations from unstructured text data, a novel dynamic analysis method is proposed. This approach begins by analyzing and extracting data from the unstructured text related to hidden dangers. It then leverages a flexible, distributed data search engine built on Elastic-Search to handle this information. Following this, the hidden Markov model is employed to train the data within the engine. The Viterbi algorithm is integrated to decipher the hidden state sequences, facilitating the segmentation and labeling of entities related to hidden dangers. The final step involves using the Neo4j graph database to dynamically create a knowledge map that visualizes hidden dangers in the substation. This method's effectiveness is demonstrated through an example analysis using data from a specific substation's hidden dangers.