 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLei Deng
Enhancing Graph Representation Learning with Attention-Driven Spiking Neural Networks
Mar 25, 2024
Graph representation learning has become a crucial task in machine learning and data mining due to its potential for modeling complex structures such as social networks, chemical compounds, and biological systems. Spiking neural networks (SNNs) have recently emerged as a promising alternative to traditional neural networks for graph learning tasks, benefiting from their ability to efficiently encode and process temporal and spatial information. In this paper, we propose a novel approach that integrates attention mechanisms with SNNs to improve graph representation learning. Specifically, we introduce an attention mechanism for SNN that can selectively focus on important nodes and corresponding features in a graph during the learning process. We evaluate our proposed method on several benchmark datasets and show that it achieves comparable performance compared to existing graph learning techniques.
Understanding the Functional Roles of Modelling Components in Spiking Neural Networks
Mar 25, 2024Spiking neural networks (SNNs), inspired by the neural circuits of the brain, are promising in achieving high computational efficiency with biological fidelity. Nevertheless, it is quite difficult to optimize SNNs because the functional roles of their modelling components remain unclear. By designing and evaluating several variants of the classic model, we systematically investigate the functional roles of key modelling components, leakage, reset, and recurrence, in leaky integrate-and-fire (LIF) based SNNs. Through extensive experiments, we demonstrate how these components influence the accuracy, generalization, and robustness of SNNs. Specifically, we find that the leakage plays a crucial role in balancing memory retention and robustness, the reset mechanism is essential for uninterrupted temporal processing and computational efficiency, and the recurrence enriches the capability to model complex dynamics at a cost of robustness degradation. With these interesting observations, we provide optimization suggestions for enhancing the performance of SNNs in different scenarios. This work deepens the understanding of how SNNs work, which offers valuable guidance for the development of more effective and robust neuromorphic models.
Extreme Video Compression with Pre-trained Diffusion Models
Feb 14, 2024Diffusion models have achieved remarkable success in generating high quality image and video data. More recently, they have also been used for image compression with high perceptual quality. In this paper, we present a novel approach to extreme video compression leveraging the predictive power of diffusion-based generative models at the decoder. The conditional diffusion model takes several neural compressed frames and generates subsequent frames. When the reconstruction quality drops below the desired level, new frames are encoded to restart prediction. The entire video is sequentially encoded to achieve a visually pleasing reconstruction, considering perceptual quality metrics such as the learned perceptual image patch similarity (LPIPS) and the Frechet video distance (FVD), at bit rates as low as 0.02 bits per pixel (bpp). Experimental results demonstrate the effectiveness of the proposed scheme compared to standard codecs such as H.264 and H.265 in the low bpp regime. The results showcase the potential of exploiting the temporal relations in video data using generative models. Code is available at: https://github.com/ElesionKyrie/Extreme-Video-Compression-With-Prediction-Using-Pre-trainded-Diffusion-Models-
Extending Context Window of Large Language Models via Semantic Compression
Dec 15, 2023Transformer-based Large Language Models (LLMs) often impose limitations on the length of the text input to ensure the generation of fluent and relevant responses. This constraint restricts their applicability in scenarios involving long texts. We propose a novel semantic compression method that enables generalization to texts that are 6-8 times longer, without incurring significant computational costs or requiring fine-tuning. Our proposed framework draws inspiration from source coding in information theory and employs a pre-trained model to reduce the semantic redundancy of long inputs before passing them to the LLMs for downstream tasks. Experimental results demonstrate that our method effectively extends the context window of LLMs across a range of tasks including question answering, summarization, few-shot learning, and information retrieval. Furthermore, the proposed semantic compression method exhibits consistent fluency in text generation while reducing the associated computational overhead.
High Perceptual Quality Wireless Image Delivery with Denoising Diffusion Models
Sep 27, 2023

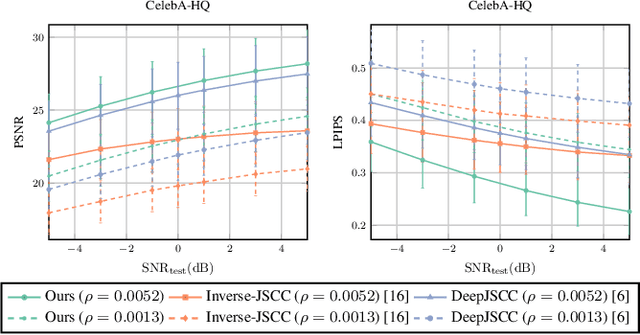

We consider the image transmission problem over a noisy wireless channel via deep learning-based joint source-channel coding (DeepJSCC) along with a denoising diffusion probabilistic model (DDPM) at the receiver. Specifically, we are interested in the perception-distortion trade-off in the practical finite block length regime, in which separate source and channel coding can be highly suboptimal. We introduce a novel scheme that utilizes the range-null space decomposition of the target image. We transmit the range-space of the image after encoding and employ DDPM to progressively refine its null space contents. Through extensive experiments, we demonstrate significant improvements in distortion and perceptual quality of reconstructed images compared to standard DeepJSCC and the state-of-the-art generative learning-based method. We will publicly share our source code to facilitate further research and reproducibility.
Attention Spiking Neural Networks
Sep 28, 2022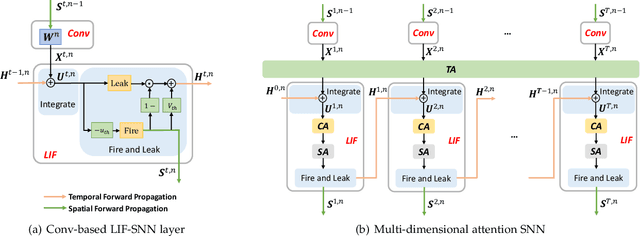
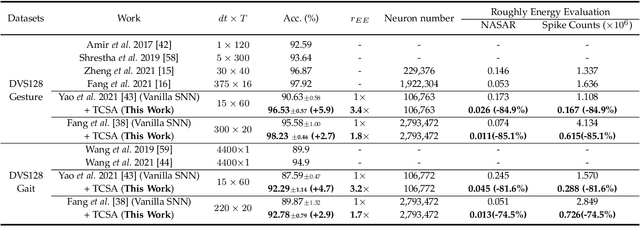
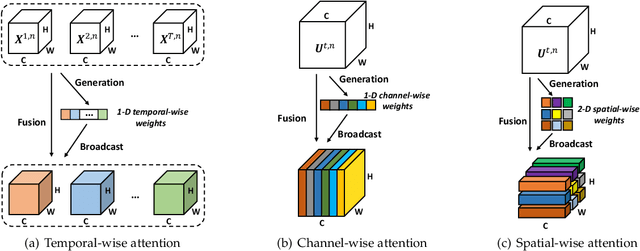
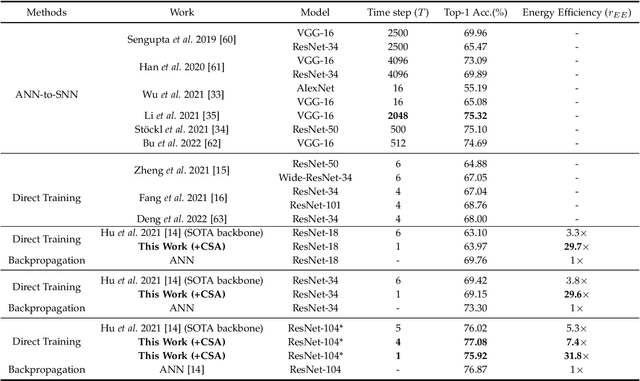
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
Contrastive learning-based computational histopathology predict differential expression of cancer driver genes
Apr 27, 2022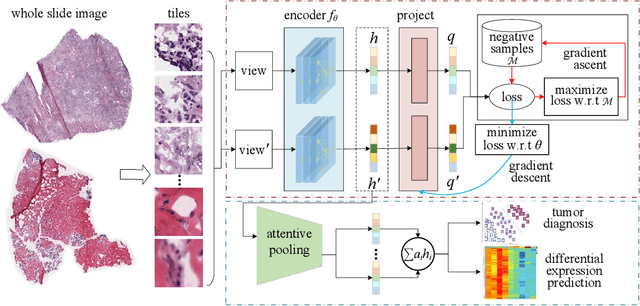
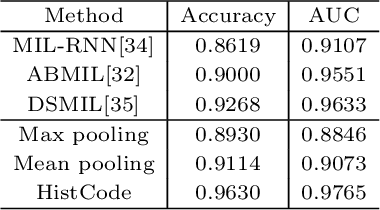
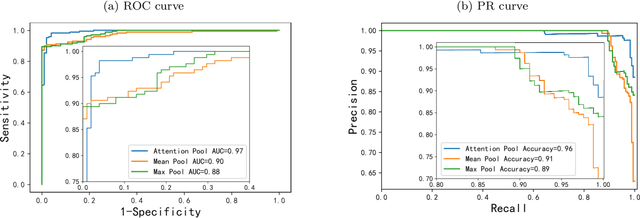
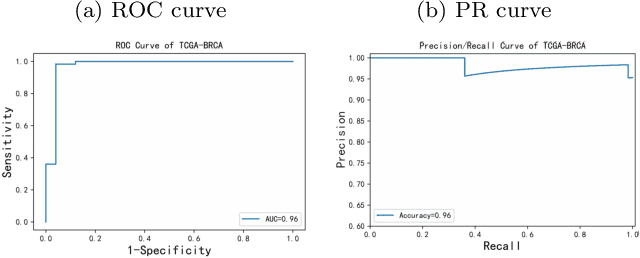
Digital pathological analysis is run as the main examination used for cancer diagnosis. Recently, deep learning-driven feature extraction from pathology images is able to detect genetic variations and tumor environment, but few studies focus on differential gene expression in tumor cells. In this paper, we propose a self-supervised contrastive learning framework, HistCode, to infer differential gene expressions from whole slide images (WSIs). We leveraged contrastive learning on large-scale unannotated WSIs to derive slide-level histopathological feature in latent space, and then transfer it to tumor diagnosis and prediction of differentially expressed cancer driver genes. Our extensive experiments showed that our method outperformed other state-of-the-art models in tumor diagnosis tasks, and also effectively predicted differential gene expressions. Interestingly, we found the higher fold-changed genes can be more precisely predicted. To intuitively illustrate the ability to extract informative features from pathological images, we spatially visualized the WSIs colored by the attentive scores of image tiles. We found that the tumor and necrosis areas were highly consistent with the annotations of experienced pathologists. Moreover, the spatial heatmap generated by lymphocyte-specific gene expression patterns was also consistent with the manually labeled WSI.
Spiking Neural Network Integrated Circuits: A Review of Trends and Future Directions
Mar 14, 2022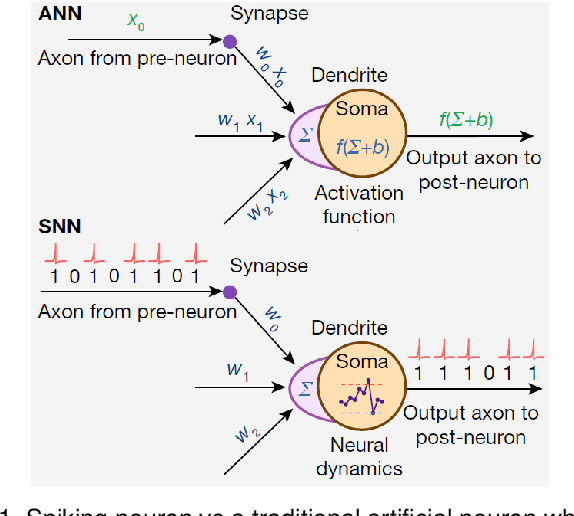
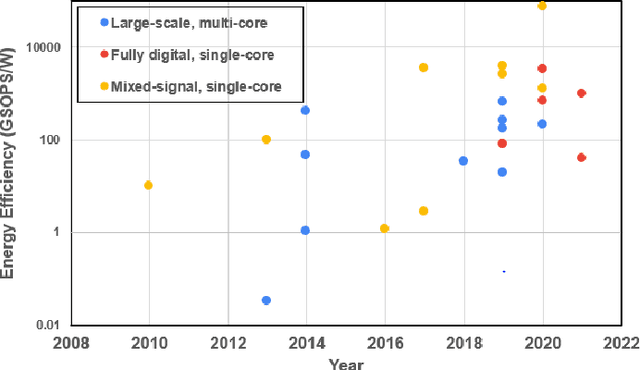
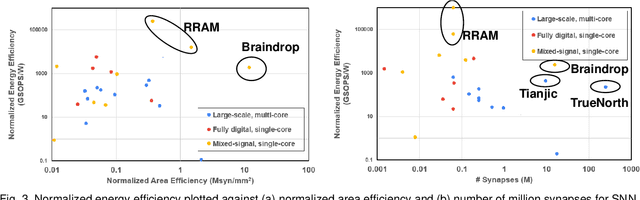
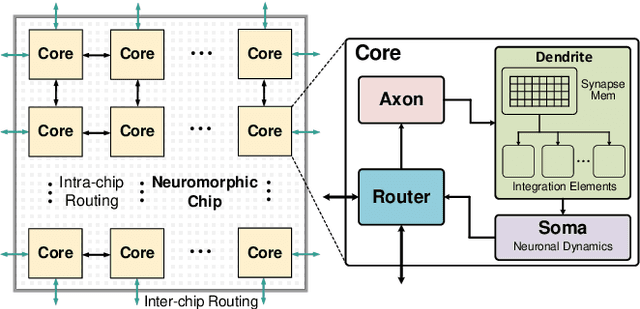
In this paper, we reviewed Spiking neural network (SNN) integrated circuit designs and analyzed the trends among mixed-signal cores, fully digital cores and large-scale, multi-core designs. Recently reported SNN integrated circuits are compared under three broad categories: (a) Large-scale multi-core designs that have dedicated NOC for spike routing, (b) digital single-core designs and (c) mixed-signal single-core designs. Finally, we finish the paper with some directions for future progress.
A Deep Learning Approach to Predicting Ventilator Parameters for Mechanically Ventilated Septic Patients
Feb 21, 2022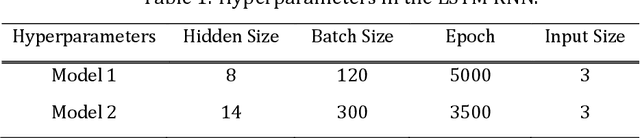
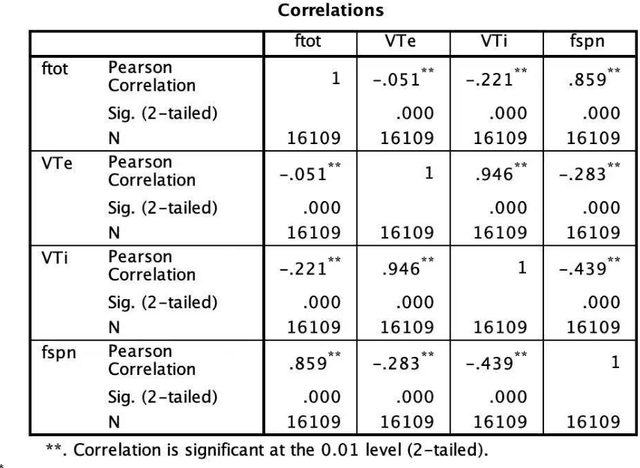
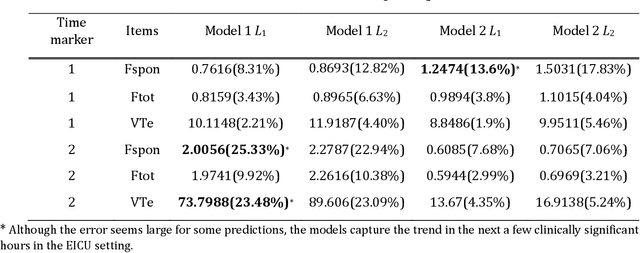
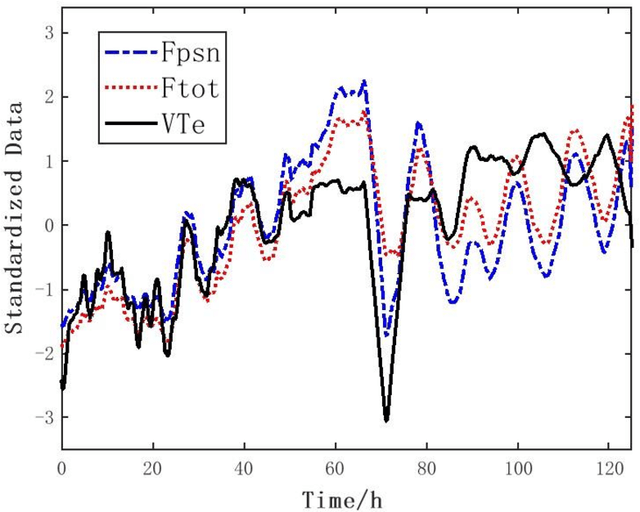
We develop a deep learning approach to predicting a set of ventilator parameters for a mechanically ventilated septic patient using a long and short term memory (LSTM) recurrent neural network (RNN) model. We focus on short-term predictions of a set of ventilator parameters for the septic patient in emergency intensive care unit (EICU). The short-term predictability of the model provides attending physicians with early warnings to make timely adjustment to the treatment of the patient in the EICU. The patient specific deep learning model can be trained on any given critically ill patient, making it an intelligent aide for physicians to use in emergent medical situations.
Survey on Graph Neural Network Acceleration: An Algorithmic Perspective
Feb 10, 2022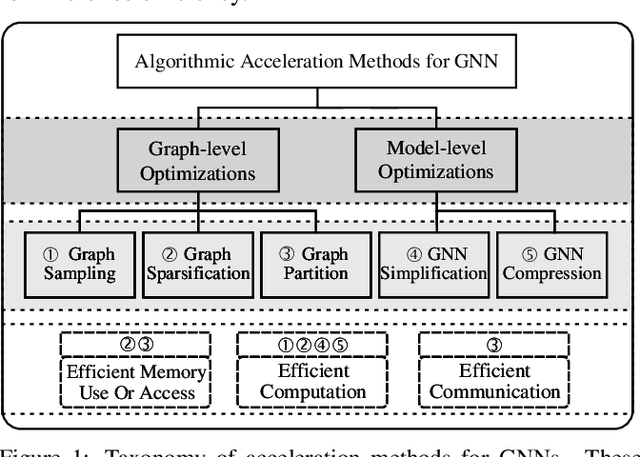
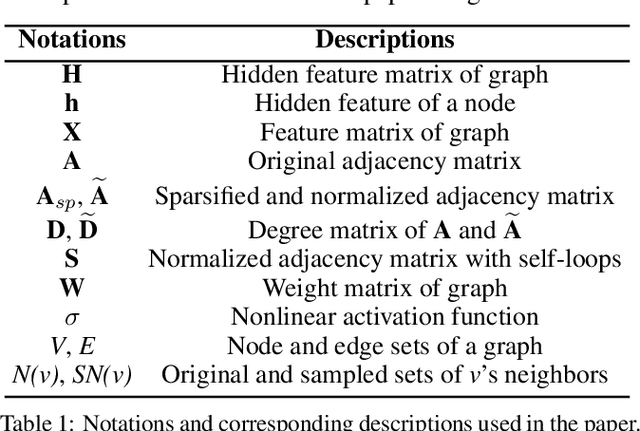
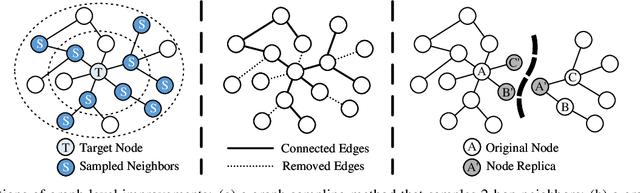

Graph neural networks (GNNs) have been a hot spot of recent research and are widely utilized in diverse applications. However, with the use of huger data and deeper models, an urgent demand is unsurprisingly made to accelerate GNNs for more efficient execution. In this paper, we provide a comprehensive survey on acceleration methods for GNNs from an algorithmic perspective. We first present a new taxonomy to classify existing acceleration methods into five categories. Based on the classification, we systematically discuss these methods and highlight their correlations. Next, we provide comparisons from aspects of the efficiency and characteristics of these methods. Finally, we suggest some promising prospects for future research.