 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoyang Li
Safe Returning FaSTrack with Robust Control Lyapunov-Value Functions
Apr 03, 2024
Real-time navigation in a priori unknown environment remains a challenging task, especially when an unexpected (unmodeled) disturbance occurs. In this paper, we propose the framework Safe Returning Fast and Safe Tracking (SR-F) that merges concepts from 1) Robust Control Lyapunov-Value Functions (R-CLVF), and 2) the Fast and Safe Tracking (FaSTrack) framework. The SR-F computes an R-CLVF offline between a model of the true system and a simplified planning model. Online, a planning algorithm is used to generate a trajectory in the simplified planning space, and the R-CLVF is used to provide a tracking controller that exponentially stabilizes to the planning model. When an unexpected disturbance occurs, the proposed SR-F algorithm provides a means for the true system to recover to the planning model. We take advantage of this mechanism to induce an artificial disturbance by ``jumping'' the planning model in open environments, forcing faster navigation. Therefore, this algorithm can both reject unexpected true disturbances and accelerate navigation speed. We validate our framework using a 10D quadrotor system and show that SR-F is empirically 20\% faster than the original FaSTrack while maintaining safety.
What Are We Measuring When We Evaluate Large Vision-Language Models? An Analysis of Latent Factors and Biases
Apr 03, 2024Vision-language (VL) models, pretrained on colossal image-text datasets, have attained broad VL competence that is difficult to evaluate. A common belief is that a small number of VL skills underlie the variety of VL tests. In this paper, we perform a large-scale transfer learning experiment aimed at discovering latent VL skills from data. We reveal interesting characteristics that have important implications for test suite design. First, generation tasks suffer from a length bias, suggesting benchmarks should balance tasks with varying output lengths. Second, we demonstrate that factor analysis successfully identifies reasonable yet surprising VL skill factors, suggesting benchmarks could leverage similar analyses for task selection. Finally, we present a new dataset, OLIVE (https://github.com/jq-zh/olive-dataset), which simulates user instructions in the wild and presents challenges dissimilar to all datasets we tested. Our findings contribute to the design of balanced and broad-coverage vision-language evaluation methods.
Interpretable Modeling of Deep Reinforcement Learning Driven Scheduling
Mar 24, 2024In the field of high-performance computing (HPC), there has been recent exploration into the use of deep reinforcement learning for cluster scheduling (DRL scheduling), which has demonstrated promising outcomes. However, a significant challenge arises from the lack of interpretability in deep neural networks (DNN), rendering them as black-box models to system managers. This lack of model interpretability hinders the practical deployment of DRL scheduling. In this work, we present a framework called IRL (Interpretable Reinforcement Learning) to address the issue of interpretability of DRL scheduling. The core idea is to interpret DNN (i.e., the DRL policy) as a decision tree by utilizing imitation learning. Unlike DNN, decision tree models are non-parametric and easily comprehensible to humans. To extract an effective and efficient decision tree, IRL incorporates the Dataset Aggregation (DAgger) algorithm and introduces the notion of critical state to prune the derived decision tree. Through trace-based experiments, we demonstrate that IRL is capable of converting a black-box DNN policy into an interpretable rulebased decision tree while maintaining comparable scheduling performance. Additionally, IRL can contribute to the setting of rewards in DRL scheduling.
PlanGPT: Enhancing Urban Planning with Tailored Language Model and Efficient Retrieval
Feb 29, 2024In the field of urban planning, general-purpose large language models often struggle to meet the specific needs of planners. Tasks like generating urban planning texts, retrieving related information, and evaluating planning documents pose unique challenges. To enhance the efficiency of urban professionals and overcome these obstacles, we introduce PlanGPT, the first specialized Large Language Model tailored for urban and spatial planning. Developed through collaborative efforts with institutions like the Chinese Academy of Urban Planning, PlanGPT leverages a customized local database retrieval framework, domain-specific fine-tuning of base models, and advanced tooling capabilities. Empirical tests demonstrate that PlanGPT has achieved advanced performance, delivering responses of superior quality precisely tailored to the intricacies of urban planning.
Towards Non-Robocentric Dynamic Landing of Quadrotor UAVs
Jan 21, 2024In this work, we propose a dynamic landing solution without the need for onboard exteroceptive sensors and an expensive computation unit, where all localization and control modules are carried out on the ground in a non-inertial frame. Our system starts with a relative state estimator of the aerial robot from the perspective of the landing platform, where the state tracking of the UAV is done through a set of onboard LED markers and an on-ground camera; the state is expressed geometrically on manifold, and is returned by Iterated Extended Kalman filter (IEKF) algorithm. Subsequently, a motion planning module is developed to guide the landing process, formulating it as a minimum jerk trajectory by applying the differential flatness property. Considering visibility and dynamic constraints, the problem is solved using quadratic programming, and the final motion primitive is expressed through piecewise polynomials. Through a series of experiments, the applicability of this approach is validated by successfully landing 18 cm x 18 cm quadrotor on a 43 cm x 43 cm platform, exhibiting performance comparable to conventional methods. Finally, we provide comprehensive hardware and software details to the research community for future reference.
DCDet: Dynamic Cross-based 3D Object Detector
Jan 14, 2024Recently, significant progress has been made in the research of 3D object detection. However, most prior studies have focused on the utilization of center-based or anchor-based label assignment schemes. Alternative label assignment strategies remain unexplored in 3D object detection. We find that the center-based label assignment often fails to generate sufficient positive samples for training, while the anchor-based label assignment tends to encounter an imbalanced issue when handling objects of varying scales. To solve these issues, we introduce a dynamic cross label assignment (DCLA) scheme, which dynamically assigns positive samples for each object from a cross-shaped region, thus providing sufficient and balanced positive samples for training. Furthermore, to address the challenge of accurately regressing objects with varying scales, we put forth a rotation-weighted Intersection over Union (RWIoU) metric to replace the widely used L1 metric in regression loss. Extensive experiments demonstrate the generality and effectiveness of our DCLA and RWIoU-based regression loss. The Code will be available at https://github.com/Say2L/DCDet.git.
Hybrid Aerodynamics-Based Model Predictive Control for a Tail-Sitter UAV
Dec 22, 2023
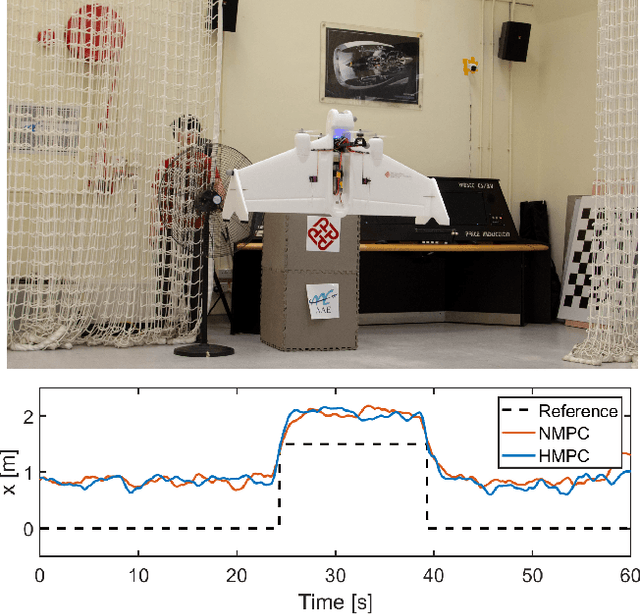
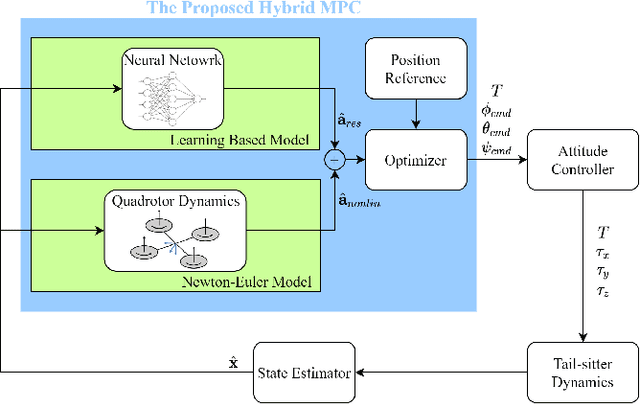
It is challenging to model and control a tail-sitter unmanned aerial vehicle (UAV) because its blended wing body generates complicated nonlinear aerodynamic effects, such as wing lift, fuselage drag, and propeller-wing interactions. We therefore devised a hybrid aerodynamic modeling method and model predictive control (MPC) design for a quadrotor tail-sitter UAV. The hybrid model consists of the Newton-Euler equation, which describes quadrotor dynamics, and a feedforward neural network, which learns residual aerodynamic effects. This hybrid model exhibits high predictive accuracy at a low computational cost and was used to implement hybrid MPC, which optimizes the throttle, pitch angle, and roll angle for position tracking. The controller performance was validated in real-world experiments, which obtained a 57% tracking error reduction compared with conventional nonlinear MPC. External wind disturbance was also introduced and the experimental results confirmed the robustness of the controller to these conditions.
Distilling Autoregressive Models to Obtain High-Performance Non-Autoregressive Solvers for Vehicle Routing Problems with Faster Inference Speed
Dec 19, 2023Neural construction models have shown promising performance for Vehicle Routing Problems (VRPs) by adopting either the Autoregressive (AR) or Non-Autoregressive (NAR) learning approach. While AR models produce high-quality solutions, they generally have a high inference latency due to their sequential generation nature. Conversely, NAR models generate solutions in parallel with a low inference latency but generally exhibit inferior performance. In this paper, we propose a generic Guided Non-Autoregressive Knowledge Distillation (GNARKD) method to obtain high-performance NAR models having a low inference latency. GNARKD removes the constraint of sequential generation in AR models while preserving the learned pivotal components in the network architecture to obtain the corresponding NAR models through knowledge distillation. We evaluate GNARKD by applying it to three widely adopted AR models to obtain NAR VRP solvers for both synthesized and real-world instances. The experimental results demonstrate that GNARKD significantly reduces the inference time (4-5 times faster) with acceptable performance drop (2-3\%). To the best of our knowledge, this study is first-of-its-kind to obtain NAR VRP solvers from AR ones through knowledge distillation.
Training on Synthetic Data Beats Real Data in Multimodal Relation Extraction
Dec 05, 2023The task of multimodal relation extraction has attracted significant research attention, but progress is constrained by the scarcity of available training data. One natural thought is to extend existing datasets with cross-modal generative models. In this paper, we consider a novel problem setting, where only unimodal data, either text or image, are available during training. We aim to train a multimodal classifier from synthetic data that perform well on real multimodal test data. However, training with synthetic data suffers from two obstacles: lack of data diversity and label information loss. To alleviate the issues, we propose Mutual Information-aware Multimodal Iterated Relational dAta GEneration (MI2RAGE), which applies Chained Cross-modal Generation (CCG) to promote diversity in the generated data and exploits a teacher network to select valuable training samples with high mutual information with the ground-truth labels. Comparing our method to direct training on synthetic data, we observed a significant improvement of 24.06% F1 with synthetic text and 26.42% F1 with synthetic images. Notably, our best model trained on completely synthetic images outperforms prior state-of-the-art models trained on real multimodal data by a margin of 3.76% in F1. Our codebase will be made available upon acceptance.
Plug-and-Play, Dense-Label-Free Extraction of Open-Vocabulary Semantic Segmentation from Vision-Language Models
Nov 28, 2023From an enormous amount of image-text pairs, large-scale vision-language models (VLMs) learn to implicitly associate image regions with words, which is vital for tasks such as image captioning and visual question answering. However, leveraging such pre-trained models for open-vocabulary semantic segmentation remains a challenge. In this paper, we propose a simple, yet extremely effective, training-free technique, Plug-and-Play Open-Vocabulary Semantic Segmentation (PnP-OVSS) for this task. PnP-OVSS leverages a VLM with direct text-to-image cross-attention and an image-text matching loss to produce semantic segmentation. However, cross-attention alone tends to over-segment, whereas cross-attention plus GradCAM tend to under-segment. To alleviate this issue, we introduce Salience Dropout; by iteratively dropping patches that the model is most attentive to, we are able to better resolve the entire extent of the segmentation mask. Compared to existing techniques, the proposed method does not require any neural network training and performs hyperparameter tuning without the need for any segmentation annotations, even for a validation set. PnP-OVSS demonstrates substantial improvements over a comparable baseline (+29.4% mIoU on Pascal VOC, +13.2% mIoU on Pascal Context, +14.0% mIoU on MS COCO, +2.4% mIoU on COCO Stuff) and even outperforms most baselines that conduct additional network training on top of pretrained VLMs.