 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheng Zhang
FiP: a Fixed-Point Approach for Causal Generative Modeling
Apr 14, 2024
Modeling true world data-generating processes lies at the heart of empirical science. Structural Causal Models (SCMs) and their associated Directed Acyclic Graphs (DAGs) provide an increasingly popular answer to such problems by defining the causal generative process that transforms random noise into observations. However, learning them from observational data poses an ill-posed and NP-hard inverse problem in general. In this work, we propose a new and equivalent formalism that does not require DAGs to describe them, viewed as fixed-point problems on the causally ordered variables, and we show three important cases where they can be uniquely recovered given the topological ordering (TO). To the best of our knowledge, we obtain the weakest conditions for their recovery when TO is known. Based on this, we design a two-stage causal generative model that first infers the causal order from observations in a zero-shot manner, thus by-passing the search, and then learns the generative fixed-point SCM on the ordered variables. To infer TOs from observations, we propose to amortize the learning of TOs on generated datasets by sequentially predicting the leaves of graphs seen during training. To learn fixed-point SCMs, we design a transformer-based architecture that exploits a new attention mechanism enabling the modeling of causal structures, and show that this parameterization is consistent with our formalism. Finally, we conduct an extensive evaluation of each method individually, and show that when combined, our model outperforms various baselines on generated out-of-distribution problems.
Taming Stable Diffusion for Text to 360° Panorama Image Generation
Apr 11, 2024Generative models, e.g., Stable Diffusion, have enabled the creation of photorealistic images from text prompts. Yet, the generation of 360-degree panorama images from text remains a challenge, particularly due to the dearth of paired text-panorama data and the domain gap between panorama and perspective images. In this paper, we introduce a novel dual-branch diffusion model named PanFusion to generate a 360-degree image from a text prompt. We leverage the stable diffusion model as one branch to provide prior knowledge in natural image generation and register it to another panorama branch for holistic image generation. We propose a unique cross-attention mechanism with projection awareness to minimize distortion during the collaborative denoising process. Our experiments validate that PanFusion surpasses existing methods and, thanks to its dual-branch structure, can integrate additional constraints like room layout for customized panorama outputs. Code is available at https://chengzhag.github.io/publication/panfusion.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation
Mar 08, 2024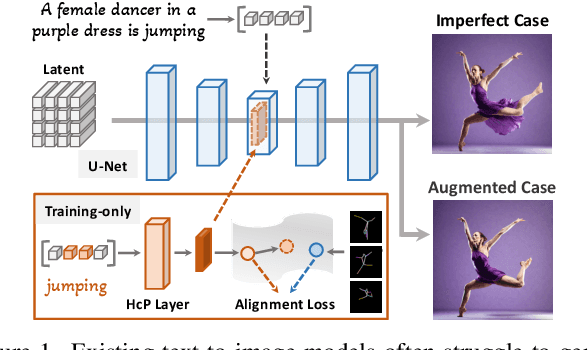
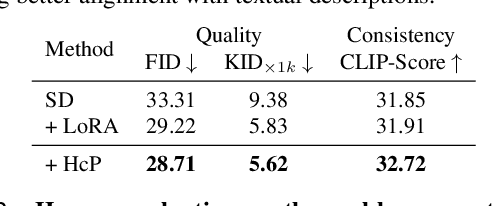
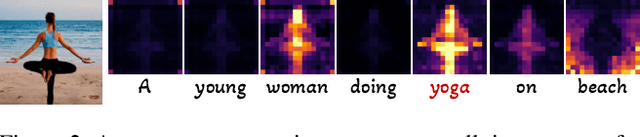
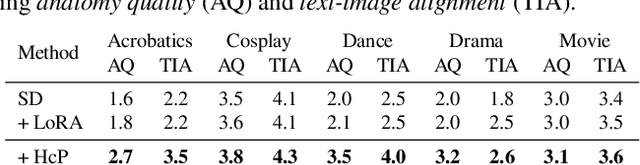
Vanilla text-to-image diffusion models struggle with generating accurate human images, commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs.Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls -- human-centric priors such as pose or depth maps -- during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage, essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning, we introduce scale-aware and step-wise constraints within the diffusion process, according to an in-depth analysis of the cross-attention layer. Extensive experiments show that our method largely improves over state-of-the-art text-to-image models to synthesize high-quality human images based on user-written prompts. Project page: \url{https://hcplayercvpr2024.github.io}.
Inverse Design of Photonic Crystal Surface Emitting Lasers is a Sequence Modeling Problem
Mar 08, 2024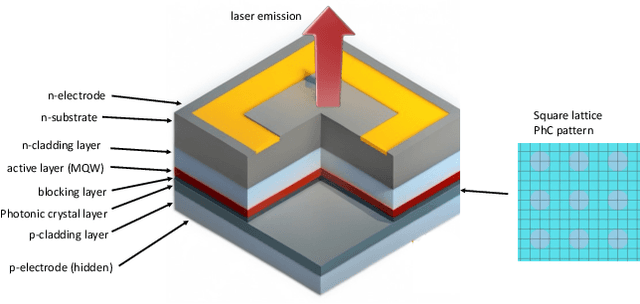
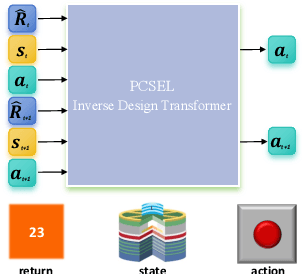
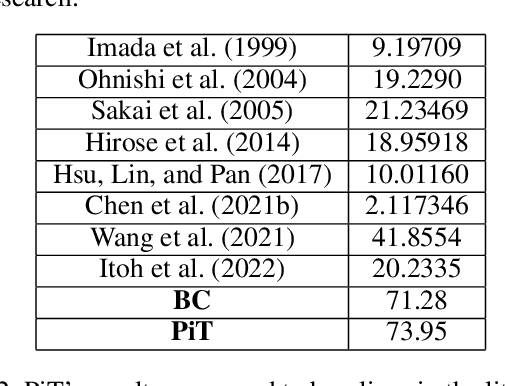
Photonic Crystal Surface Emitting Lasers (PCSEL)'s inverse design demands expert knowledge in physics, materials science, and quantum mechanics which is prohibitively labor-intensive. Advanced AI technologies, especially reinforcement learning (RL), have emerged as a powerful tool to augment and accelerate this inverse design process. By modeling the inverse design of PCSEL as a sequential decision-making problem, RL approaches can construct a satisfactory PCSEL structure from scratch. However, the data inefficiency resulting from online interactions with precise and expensive simulation environments impedes the broader applicability of RL approaches. Recently, sequential models, especially the Transformer architecture, have exhibited compelling performance in sequential decision-making problems due to their simplicity and scalability to large language models. In this paper, we introduce a novel framework named PCSEL Inverse Design Transformer (PiT) that abstracts the inverse design of PCSEL as a sequence modeling problem. The central part of our PiT is a Transformer-based structure that leverages the past trajectories and current states to predict the current actions. Compared with the traditional RL approaches, PiT can output the optimal actions and achieve target PCSEL designs by leveraging offline data and conditioning on the desired return. Results demonstrate that PiT achieves superior performance and data efficiency compared to baselines.
Deep Reinforcement Learning for Solving Management Problems: Towards A Large Management Mode
Mar 01, 2024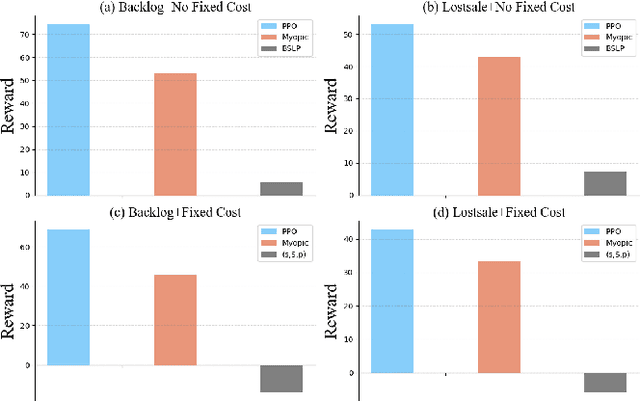
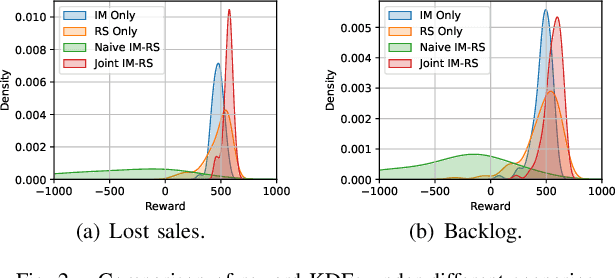
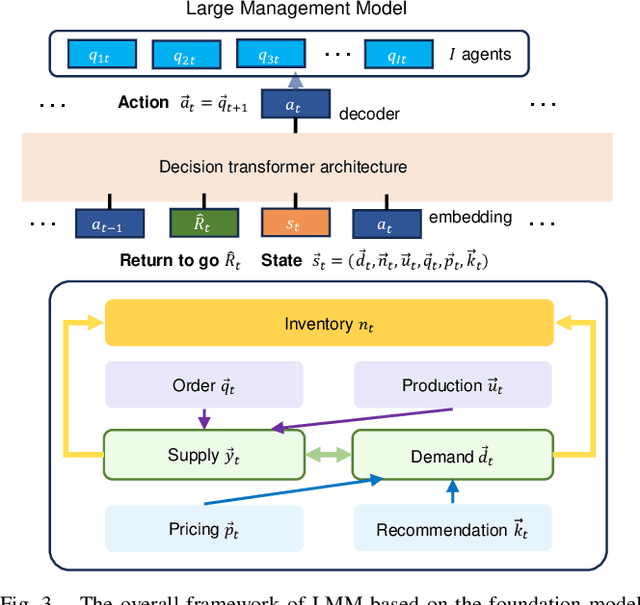
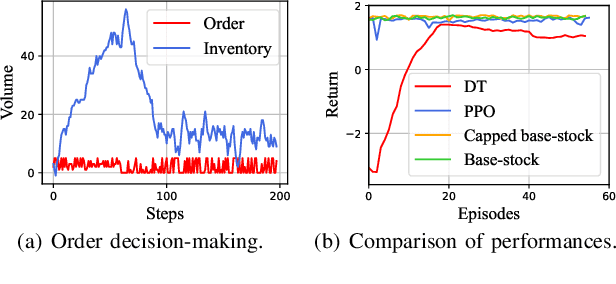
We introduce a deep reinforcement learning (DRL) approach for solving management problems including inventory management, dynamic pricing, and recommendation. This DRL approach has the potential to lead to a large management model based on certain transformer neural network structures, resulting in an artificial general intelligence paradigm for various management tasks. Traditional methods have limitations for solving complex real-world problems, and we demonstrate how DRL can surpass existing heuristic approaches for solving management tasks. We aim to solve the problems in a unified framework, considering the interconnections between different tasks. Central to our methodology is the development of a foundational decision model coordinating decisions across the different domains through generative decision-making. Our experimental results affirm the effectiveness of our DRL-based framework in complex and dynamic business environments. This work opens new pathways for the application of DRL in management problems, highlighting its potential to revolutionize traditional business management.
RobWE: Robust Watermark Embedding for Personalized Federated Learning Model Ownership Protection
Feb 29, 2024Embedding watermarks into models has been widely used to protect model ownership in federated learning (FL). However, existing methods are inadequate for protecting the ownership of personalized models acquired by clients in personalized FL (PFL). This is due to the aggregation of the global model in PFL, resulting in conflicts over clients' private watermarks. Moreover, malicious clients may tamper with embedded watermarks to facilitate model leakage and evade accountability. This paper presents a robust watermark embedding scheme, named RobWE, to protect the ownership of personalized models in PFL. We first decouple the watermark embedding of personalized models into two parts: head layer embedding and representation layer embedding. The head layer belongs to clients' private part without participating in model aggregation, while the representation layer is the shared part for aggregation. For representation layer embedding, we employ a watermark slice embedding operation, which avoids watermark embedding conflicts. Furthermore, we design a malicious watermark detection scheme enabling the server to verify the correctness of watermarks before aggregating local models. We conduct an exhaustive experimental evaluation of RobWE. The results demonstrate that RobWE significantly outperforms the state-of-the-art watermark embedding schemes in FL in terms of fidelity, reliability, and robustness.
You Only Need One Color Space: An Efficient Network for Low-light Image Enhancement
Feb 08, 2024Low-Light Image Enhancement (LLIE) task tends to restore the details and visual information from corrupted low-light images. Most existing methods learn the mapping function between low/normal-light images by Deep Neural Networks (DNNs) on sRGB and HSV color space. Nevertheless, enhancement involves amplifying image signals, and applying these color spaces to low-light images with a low signal-to-noise ratio can introduce sensitivity and instability into the enhancement process. Consequently, this results in the presence of color artifacts and brightness artifacts in the enhanced images. To alleviate this problem, we propose a novel trainable color space, named Horizontal/Vertical-Intensity (HVI). It not only decouples brightness and color from RGB channels to mitigate the instability during enhancement but also adapts to low-light images in different illumination ranges due to the trainable parameters. Further, we design a novel Color and Intensity Decoupling Network (CIDNet) with two branches dedicated to processing the decoupled image brightness and color in the HVI space. Within CIDNet, we introduce the Lightweight Cross-Attention (LCA) module to facilitate interaction between image structure and content information in both branches, while also suppressing noise in low-light images. Finally, we conducted 22 quantitative and qualitative experiments to show that the proposed CIDNet outperforms the state-of-the-art methods on 11 datasets. The code will be available at https://github.com/Fediory/HVI-CIDNet.
The Essential Role of Causality in Foundation World Models for Embodied AI
Feb 06, 2024Recent advances in foundation models, especially in large multi-modal models and conversational agents, have ignited interest in the potential of generally capable embodied agents. Such agents would require the ability to perform new tasks in many different real-world environments. However, current foundation models fail to accurately model physical interactions with the real world thus not sufficient for Embodied AI. The study of causality lends itself to the construction of veridical world models, which are crucial for accurately predicting the outcomes of possible interactions. This paper focuses on the prospects of building foundation world models for the upcoming generation of embodied agents and presents a novel viewpoint on the significance of causality within these. We posit that integrating causal considerations is vital to facilitate meaningful physical interactions with the world. Finally, we demystify misconceptions about causality in this context and present our outlook for future research.
LQER: Low-Rank Quantization Error Reconstruction for LLMs
Feb 04, 2024Post-training quantization of Large Language Models (LLMs) is challenging. In this work, we introduce Low-rank Quantization Error Reduction (LQER), which combines quantization and low-rank approximation to recover the model capability. LQER leverages an activation-induced scale matrix to drive the singular value distribution of quantization error towards a desirable distribution, which enables nearly-lossless W4A8 quantization on various LLMs and downstream tasks without the need for knowledge distillation, grid search, or gradient-base iterative optimization. Unlike existing methods, the computation pattern of LQER eliminates the need for specialized Scatter and Gather processes to collect high-precision weights from irregular memory locations. Our W4A8 LLMs achieve near-lossless performance on six popular downstream tasks, while using 1.36$\times$ fewer hardware resources than the leading state-of-the-art method. We will open-source our framework once the paper is accepted.