 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZheng Zhu
TAIL: A Terrain-Aware Multi-Modal SLAM Dataset for Robot Locomotion in Deformable Granular Environments
Mar 25, 2024
Terrain-aware perception holds the potential to improve the robustness and accuracy of autonomous robot navigation in the wilds, thereby facilitating effective off-road traversals. However, the lack of multi-modal perception across various motion patterns hinders the solutions of Simultaneous Localization And Mapping (SLAM), especially when confronting non-geometric hazards in demanding landscapes. In this paper, we first propose a Terrain-Aware multI-modaL (TAIL) dataset tailored to deformable and sandy terrains. It incorporates various types of robotic proprioception and distinct ground interactions for the unique challenges and benchmark of multi-sensor fusion SLAM. The versatile sensor suite comprises stereo frame cameras, multiple ground-pointing RGB-D cameras, a rotating 3D LiDAR, an IMU, and an RTK device. This ensemble is hardware-synchronized, well-calibrated, and self-contained. Utilizing both wheeled and quadrupedal locomotion, we efficiently collect comprehensive sequences to capture rich unstructured scenarios. It spans the spectrum of scope, terrain interactions, scene changes, ground-level properties, and dynamic robot characteristics. We benchmark several state-of-the-art SLAM methods against ground truth and provide performance validations. Corresponding challenges and limitations are also reported. All associated resources are accessible upon request at \url{https://tailrobot.github.io/}.
DriveDreamer-2: LLM-Enhanced World Models for Diverse Driving Video Generation
Mar 11, 2024
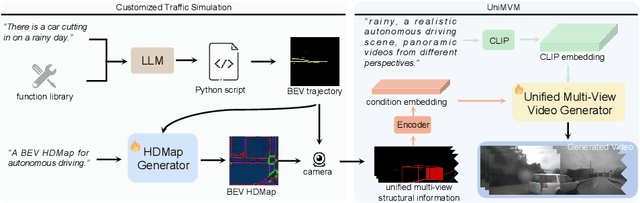


World models have demonstrated superiority in autonomous driving, particularly in the generation of multi-view driving videos. However, significant challenges still exist in generating customized driving videos. In this paper, we propose DriveDreamer-2, which builds upon the framework of DriveDreamer and incorporates a Large Language Model (LLM) to generate user-defined driving videos. Specifically, an LLM interface is initially incorporated to convert a user's query into agent trajectories. Subsequently, a HDMap, adhering to traffic regulations, is generated based on the trajectories. Ultimately, we propose the Unified Multi-View Model to enhance temporal and spatial coherence in the generated driving videos. DriveDreamer-2 is the first world model to generate customized driving videos, it can generate uncommon driving videos (e.g., vehicles abruptly cut in) in a user-friendly manner. Besides, experimental results demonstrate that the generated videos enhance the training of driving perception methods (e.g., 3D detection and tracking). Furthermore, video generation quality of DriveDreamer-2 surpasses other state-of-the-art methods, showcasing FID and FVD scores of 11.2 and 55.7, representing relative improvements of 30% and 50%.
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens
Jan 18, 2024World models play a crucial role in understanding and predicting the dynamics of the world, which is essential for video generation. However, existing world models are confined to specific scenarios such as gaming or driving, limiting their ability to capture the complexity of general world dynamic environments. Therefore, we introduce WorldDreamer, a pioneering world model to foster a comprehensive comprehension of general world physics and motions, which significantly enhances the capabilities of video generation. Drawing inspiration from the success of large language models, WorldDreamer frames world modeling as an unsupervised visual sequence modeling challenge. This is achieved by mapping visual inputs to discrete tokens and predicting the masked ones. During this process, we incorporate multi-modal prompts to facilitate interaction within the world model. Our experiments show that WorldDreamer excels in generating videos across different scenarios, including natural scenes and driving environments. WorldDreamer showcases versatility in executing tasks such as text-to-video conversion, image-tovideo synthesis, and video editing. These results underscore WorldDreamer's effectiveness in capturing dynamic elements within diverse general world environments.
On the Identifiability from Modulo Measurements under DFT Sensing Matrix
Dec 30, 2023Unlimited sampling was recently introduced to deal with the clipping or saturation of measurements where a modulo operator is applied before sampling. In this paper, we investigate the identifiability of the model where measurements are acquired under a discrete Fourier transform (DFT) sensing matrix first followed by a modulo operator (modulo-DFT). Firstly, based on the theorems of cyclotomic polynomials, we derive a sufficient condition for uniquely identifying the original signal in modulo-DFT. Additionally, for periodic bandlimited signals (PBSs) under unlimited sampling which can be viewed as a special case of modulo-DFT, the necessary and sufficient condition for the unique recovery of the original signal are provided. Moreover, we show that when the oversampling factor exceeds $3(1+1/P)$, PBS is always identifiable from the modulo samples, where $P$ is the number of harmonics including the fundamental component in the positive frequency part.
Generative Pretraining at Scale: Transformer-Based Encoding of Transactional Behavior for Fraud Detection
Dec 22, 2023In this work, we introduce an innovative autoregressive model leveraging Generative Pretrained Transformer (GPT) architectures, tailored for fraud detection in payment systems. Our approach innovatively confronts token explosion and reconstructs behavioral sequences, providing a nuanced understanding of transactional behavior through temporal and contextual analysis. Utilizing unsupervised pretraining, our model excels in feature representation without the need for labeled data. Additionally, we integrate a differential convolutional approach to enhance anomaly detection, bolstering the security and efficacy of one of the largest online payment merchants in China. The scalability and adaptability of our model promise broad applicability in various transactional contexts.
OpenStereo: A Comprehensive Benchmark for Stereo Matching and Strong Baseline
Dec 01, 2023Stereo matching, a pivotal technique in computer vision, plays a crucial role in robotics, autonomous navigation, and augmented reality. Despite the development of numerous impressive methods in recent years, replicating their results and determining the most suitable architecture for practical application remains challenging. Addressing this gap, our paper introduces a comprehensive benchmark focusing on practical applicability rather than solely on performance enhancement. Specifically, we develop a flexible and efficient stereo matching codebase, called OpenStereo. OpenStereo includes training and inference codes of more than 12 network models, making it, to our knowledge, the most complete stereo matching toolbox available. Based on OpenStereo, we conducted experiments on the SceneFlow dataset and have achieved or surpassed the performance metrics reported in the original paper. Additionally, we conduct an in-depth revisitation of recent developments in stereo matching through ablative experiments. These investigations inspired the creation of StereoBase, a simple yet strong baseline model. Our extensive comparative analyses of StereoBase against numerous contemporary stereo matching methods on the SceneFlow dataset demonstrate its remarkably strong performance. The source code is available at https://github.com/XiandaGuo/OpenStereo.
On the Road with GPT-4V(ision): Early Explorations of Visual-Language Model on Autonomous Driving
Nov 28, 2023



The pursuit of autonomous driving technology hinges on the sophisticated integration of perception, decision-making, and control systems. Traditional approaches, both data-driven and rule-based, have been hindered by their inability to grasp the nuance of complex driving environments and the intentions of other road users. This has been a significant bottleneck, particularly in the development of common sense reasoning and nuanced scene understanding necessary for safe and reliable autonomous driving. The advent of Visual Language Models (VLM) represents a novel frontier in realizing fully autonomous vehicle driving. This report provides an exhaustive evaluation of the latest state-of-the-art VLM, GPT-4V(ision), and its application in autonomous driving scenarios. We explore the model's abilities to understand and reason about driving scenes, make decisions, and ultimately act in the capacity of a driver. Our comprehensive tests span from basic scene recognition to complex causal reasoning and real-time decision-making under varying conditions. Our findings reveal that GPT-4V demonstrates superior performance in scene understanding and causal reasoning compared to existing autonomous systems. It showcases the potential to handle out-of-distribution scenarios, recognize intentions, and make informed decisions in real driving contexts. However, challenges remain, particularly in direction discernment, traffic light recognition, vision grounding, and spatial reasoning tasks. These limitations underscore the need for further research and development. Project is now available on GitHub for interested parties to access and utilize: \url{https://github.com/PJLab-ADG/GPT4V-AD-Exploration}
DREAM+: Efficient Dataset Distillation by Bidirectional Representative Matching
Oct 23, 2023Dataset distillation plays a crucial role in creating compact datasets with similar training performance compared with original large-scale ones. This is essential for addressing the challenges of data storage and training costs. Prevalent methods facilitate knowledge transfer by matching the gradients, embedding distributions, or training trajectories of synthetic images with those of the sampled original images. Although there are various matching objectives, currently the strategy for selecting original images is limited to naive random sampling. We argue that random sampling overlooks the evenness of the selected sample distribution, which may result in noisy or biased matching targets. Besides, the sample diversity is also not constrained by random sampling. Additionally, current methods predominantly focus on single-dimensional matching, where information is not fully utilized. To address these challenges, we propose a novel matching strategy called Dataset Distillation by Bidirectional REpresentAtive Matching (DREAM+), which selects representative original images for bidirectional matching. DREAM+ is applicable to a variety of mainstream dataset distillation frameworks and significantly reduces the number of distillation iterations by more than 15 times without affecting performance. Given sufficient training time, DREAM+ can further improve the performance and achieve state-of-the-art results. We have released the code at github.com/NUS-HPC-AI-Lab/DREAM+.
DriveDreamer: Towards Real-world-driven World Models for Autonomous Driving
Sep 18, 2023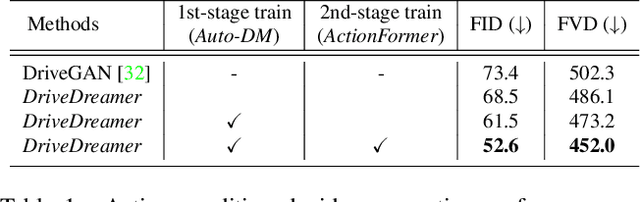
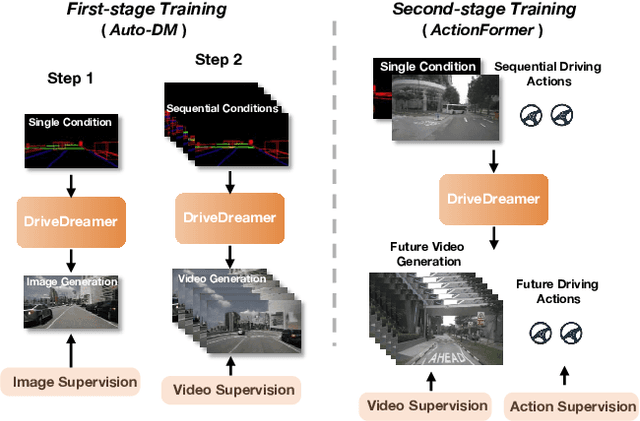

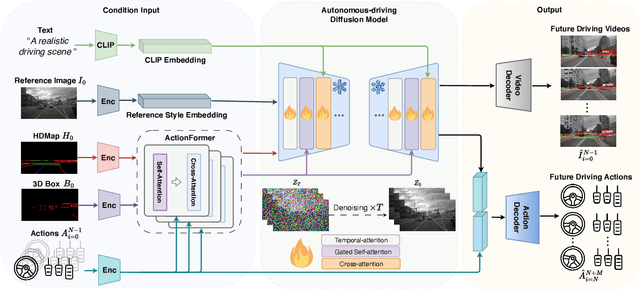
World models, especially in autonomous driving, are trending and drawing extensive attention due to their capacity for comprehending driving environments. The established world model holds immense potential for the generation of high-quality driving videos, and driving policies for safe maneuvering. However, a critical limitation in relevant research lies in its predominant focus on gaming environments or simulated settings, thereby lacking the representation of real-world driving scenarios. Therefore, we introduce DriveDreamer, a pioneering world model entirely derived from real-world driving scenarios. Regarding that modeling the world in intricate driving scenes entails an overwhelming search space, we propose harnessing the powerful diffusion model to construct a comprehensive representation of the complex environment. Furthermore, we introduce a two-stage training pipeline. In the initial phase, DriveDreamer acquires a deep understanding of structured traffic constraints, while the subsequent stage equips it with the ability to anticipate future states. The proposed DriveDreamer is the first world model established from real-world driving scenarios. We instantiate DriveDreamer on the challenging nuScenes benchmark, and extensive experiments verify that DriveDreamer empowers precise, controllable video generation that faithfully captures the structural constraints of real-world traffic scenarios. Additionally, DriveDreamer enables the generation of realistic and reasonable driving policies, opening avenues for interaction and practical applications.